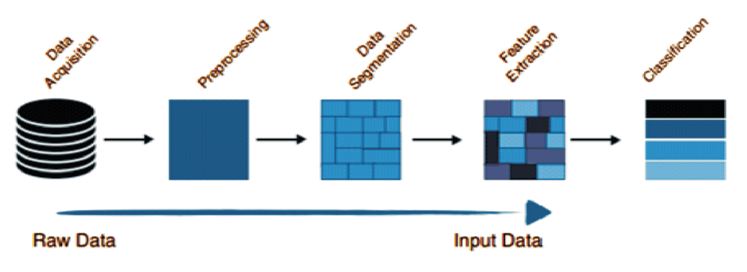
Figure 1. Steps of Activity Recognition Process (ARP)
Smartphone sensors produce high-dimensional feature vectors that can be utilized to recognize different human activities. However, the contribution of each vector in the identification process is different, and several strategies have been examined over time to develop a procedure that yields favorable results. This paper presents the latest Machine Learning algorithms proposed for human activity classification, which include data acquisition, data preprocessing, data segmentation, feature selection, and dataset classification into training and testing sets. The solutions are compared and thoroughly analyzed by highlighting the respective advantages and disadvantages. The results show that the Support Vector Machine (SVM) algorithm achieved an accuracy rate of 95%.
The observation of human activities and behavior can play a crucial role in various sectors such as healthcare, counter-terrorism, and surveillance. Human Activity Recognition (HAR) has emerged as an important research area in recent years, with the goal of automatically recognizing various activities. The HAR field involves several tasks, ranging from signal acquisition to activity classification. Researchers have studied various techniques and methods for automatic human activity recognition, including dedicated hardware, computational, and qualitative techniques for preprocessing data. Inertial signal sensors commonly found in smartphones can be used to identify distinct physical states of humans (Ferrari et al., 2021).
Research on human activity recognition models date back to the late 1990s and early 2000s. Over the past two decades, researchers have explored numerous methods and classification techniques in the field of HAR. In recent years, the focus has shifted towards implementing effective solutions that can accurately recognize and classify activities (Berchtold et al., 2011).
Notably, recent research has focused on developing solutions that can recognize Activities of Daily Living (ADLs) from inertial signals using mobile sensors. This is largely due to the decreasing cost of hardware and the widespread availability of smartphones equipped with inertial sensors like accelerometers and gyroscopes. Mobile devices enable data acquisition and processing for a wide range of applications, including monitoring, medical management, and security purposes. In Human Activity Recognition (HAR), most classification methods rely on the Activity Recognition Process (ARP) protocol, which comprises five steps, as shown in Figure 1, such as data acquisition, data pre-processing, data segmentation, feature extraction, and classification.
Figure 1. Steps of Activity Recognition Process (ARP)
The proposed model aims to classify physical activities based on a person's movements, such as walking, sitting, standing, going upstairs or downstairs, and lying down. It will be using the accelerometer sensor on a smartphone to collect activity data, which will be first trained, and then features will be extracted. The converted data will be divided to build a recognition model to identify the user's behaviors (Kadri et al., 2020; Khan et al., 2019). Various technologies have been developed to identify activities, including Machine Learning and Deep Learning algorithms. This model utilized Machine Learning algorithms, including commonly used methods such as Support Vector Machine (SVM), Decision Tree algorithm, and the K-Nearest Neighbours (KNN).
The primary goal of the HAR model is to automatically analyze and process a person's actions or movements using data acquired by smartphone sensors such as accelerometers and gyroscopes, and predict the state of a person.
Among all electronic devices, smartphones or mobile phones are the most commonly and widely used, in contrast to other electronic devices. This is largely because smartphones are now extensively used even by the senior population and are now considered a regular part of their routine. In the recognition process, inertial sensors are the primary source of data used to recognize activities. The activities of daily physical activity are recognized by the "activity recognition" chain (in the middle). These activities vary in complexity, with simple tasks like walking, lying, sitting, and standing being examples of some easy tasks, while tasks like cleaning, cooking, driving a taxi, and climbing are examples of more difficult tasks. Based on the level of difficulty, various techniques and types of methods are implemented. This paper mainly focuses on activities that are classified as easy.
Ferrari et al. (2021) propose a novel solution for each task in the Human Activity Recognition (HAR) classification process. The study emphasizes the importance of collecting relevant information and model training, as they significantly impact classifier performance. Specifically, hand-crafted features may be better suited for modeling known traits, while extracted features may uncover unknown characteristics and patterns. The paper concludes that both Deep Learning and Machine Learning approaches can effectively solve HAR problems. To address the issue of population diversity, which can reduce the accuracy of the HAR model, data collection should be conducted on a larger scale. Additionally, more research and studies should be conducted on the pre-processing pipeline and data combination.
Ahmed et al. (2020) presents a novel feature selection process that employs a hybrid approach of filter and wrapper methods. The method involves using Sequential Floating Forward Search (SFFS) for feature extraction to obtain only the relevant features for better performance. The Support Vector Machine (SVM) algorithm is then utilized to train and test the extracted features and produce nonlinear classifiers using the kernel trick. The results showed that the classification performance was increased by 6%, achieving an accuracy of 96.81% by using optimal features.
Kadri et al. (2020) presented an approach to develop an efficient recommendation system for health using smartphone sensor data, particularly the accelerometer. The proposed system provides the status of daily physical activities following the guidelines provided by the World Health Organization (WHO), regardless of the user's health status. The model uses a decision tree algorithm and Bidirectional Long Short-Term Memory (BiLSTM). The decision tree algorithm outperformed the BiLSTM with 80% of jogging, 83% standing, and 67% walking accurately predicted. However, the Deep Learning model failed to predict the "upstairs" activity with 0% accuracy, and the Decision Tree algorithm was used instead, which provided much better results than Deep Learning. The Machine Learning classification performed much more accurately than Deep Learning algorithms.
Nematallah et al. (2019) proposes the use of a Machine Learning technique called Logistic Model Tree (LMT) for predicting human movement using inertial sensors such as accelerometers found in mobile phones. The study utilizes two public datasets, Wireless Sensor Data Mining (WISDM) and University of California, Irvine Human Activity Recognition (UCIHAR), for training and testing the system. The results showed that the LMT method outperformed Random Forest (RF) and Logistic Regression (LR) with 90.86% and 94.02% detection accuracy for WISDM and UCIHAR, respectively. Additionally, the overall accuracy for cross-dataset evaluation was found to be 89.82% and 88.73%.
Qi et al. (2020) proposed an Adaptive Human Activity Detection and Real-time Monitoring (AdaHAR) system to detect more human movements in complex scenarios. The system used hierarchical clustering and classification algorithms to autonomously label and classify 12 activities, including 5 dynamic, 6 static, and a set of transitions. The authors tested the system with six Machine Learning algorithms, and the SVM model achieved the highest accuracy.
A new Human Activity Recognition (HAR) framework using mobile phone data collected by the embedded 3-axis inertial sensors (accelerometer and gyroscope sensor) was presented. Concone et al. (2017) compared the KNN method with the K-means clustering-based classifier and achieved over 90% accuracy and recognition. Rabbi et al. (2021) presented a comparative study of several algorithms, including Support Vector Machine (SVM), Decision Tree (DT), Random Forest (RF), and Artificial Neural Network (ANN), for Human Activity Recognition (HAR). The study used a general HAR dataset from the Unique Client Identifier Machine Learning (UCI ML) repository for testing and training, with six activities considered, walking, walking up or down stairs, laying, standing, and sitting. Logistic Regression (LR) was used due to its simplicity and better performance.
Straczkiewicz et al. (2019) focus was on the increasing population and its impact on smartphone-based HAR models. Although smartphones are well-suited for collecting activity data due to their built-in inertial sensors, population diversity can affect the quality of collected data, leading to decreased accuracy (Nithya et al., 2022).
The Unique Client Identifier Machine Learning (UCI ML) Repository was used to obtain a dataset that consisted of recordings of six daily activities performed by a total of 30 individuals between the ages of 19 and 47. To record the activity data, smartphones were mounted to the waist of each participant, with a frequency of 50 Hz used during the experiment, resulting in 50 data points per second. All six activities were performed twice by each participant.
Human_Activity_Recognition_Using_Smartphones_Data is a dataset available in the UCI ML Repository in CSV format. It contains a total of 7352 rows or observations and 128 columns or attributes. Figure 2 shows a dataset representation.

Figure 2. Dataset Represented in Image
Data pre-processing is the process of converting or processing the data so that the algorithm can process it more easily. This allows the machine learning model to interpret the dataset's properties more easily. Data pre-processing in this study involves a three-step process. The first step is applying noise filtering. The second step addresses the problem of class imbalance, and the third step involves a simple majority voting-based attribute selection phase. The histograms of total acceleration data by activity are shown in Figure 3.
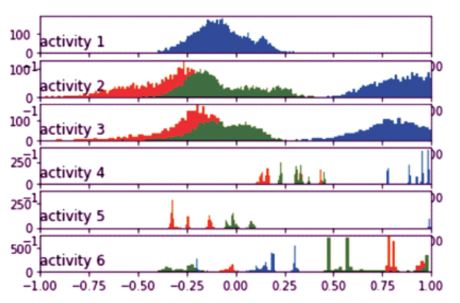
Figure 3. Histograms of the Total Acceleration Data by Activity
Histograms for body acceleration and body gyroscope are plotted to visualize the effect of data pre-processing on the anomaly of the data.
The presence of noise in datasets can degrade the overall efficiency and predictive ability of Machine Learning algorithms. It may even lead to incorrect classification or prediction. Two types of noise that can occur in datasets are missing values and outliers.
Feature extraction reduces data dimensionality by abstracting each data segment into a high-level representation of the same segment while identifying the most essential characteristics of the signal.
Machine Learning techniques are widely used for activity recognition tasks due to their efficiency in solving complexities related to such tasks. Various methods have been developed to achieve accurate activity recognition.
The SVM classification technique was utilized as it is a versatile, powerful, and precise method for classification tasks. Its primary objective is to separate variables using the kernel trick. The kernel generates the maximum marginal hyperplanes recursively to solve the problem. This hyperplane divides the dataset into corresponding classes, i.e., the faulty class and the non-faulty class.
The k-Nearest Neighbors (k-NN) algorithm is an example of an instance-based approach used in Machine Learning. The k-NN technique uses a distance metric to compare each new instance to old ones, and the nearest existing instance is used to assign the class to the new one. In the basic situation, k is set to 1. However, if k is greater than 1, the majority class of the k-nearest neighbors is assigned to a new instance. This algorithm is considered a basic algorithm that belongs to the category of lazy algorithms.
The Decision Tree Algorithm uses a hierarchical model in which input data is mapped from the root to the leaf through branches. A classification rule is defined as the path between the root and the leaf. The length of the tree may need to be adjusted in some cases.
It is an ensemble ML classification model that improves results by reducing overfitting compared to classic decision trees. The majority voting rule is used to arrive at the final prediction. The RF approach constructs decision trees using random samples from the dataset, obtains predictions from each, and then chooses the optimal solution using the majority voting rule. In multiclass classification, it combines the mode of all the different decision tree models developed to arrive at a final result. The averaging of results helps to reduce overfitting.
The Naive Bayes (NB) Rule is based on the idea of deducing a hypothesis (H) from the evidence available (E). It connects two concepts: the hypothesis's probability before getting evidence, P(H), and the hypothesis's probability after acquiring evidence, P(H|E). In general, it can be calculated using the following Equation 1.
P(H|E) = (P(E|H) * P(H)) / P(E)
Training data is used to teach the model, while validation data is used to test the model and produce new predictions.
Decision trees such as regression and classification trees are prone to high variance, meaning that applying a decision tree to randomly divided training data can lead to significantly different outcomes. To minimize the variance of a quantitative learning system, a generalpurpose strategy is bootstrap aggregation, also known as bagging. Bagging has been shown to enhance accuracy significantly by grouping hundreds or even thousands of trees into a single operation.
In the proposed model, Python with Anaconda on Windows 10 was used. Additionally, libraries such as Matplotlib, Seaborn, Sklearn, Numpy, and Pandas were utilized. Table 1 displays the formulas for key metrics used. The confusion matrix, a commonly used tool in classification methods, produces the following values.

Table 1. Key Metrics
Figures 4 to 8 depict various classification methods using the SVM classifier to determine the best algorithm for the given dataset. Likewise, other classification tables and curves were plotted using different algorithms. Figure 6 illustrates all the defined models with their corresponding accuracies.
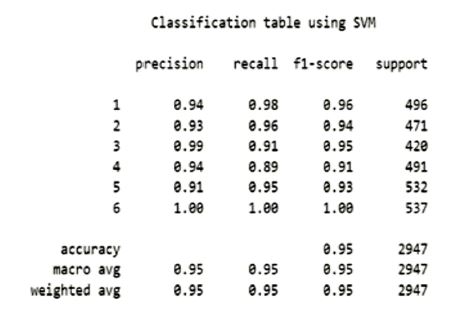
Figure 4. Classification Table Using SVM Classifier
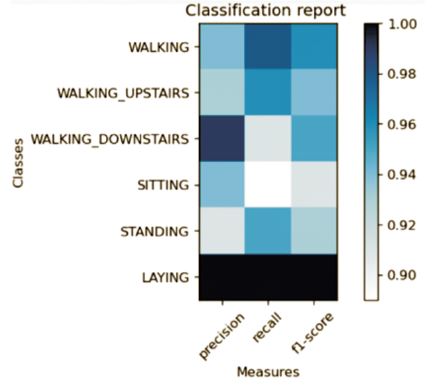
Figure 5. Classification Report Matrix of Key Metrics per Class
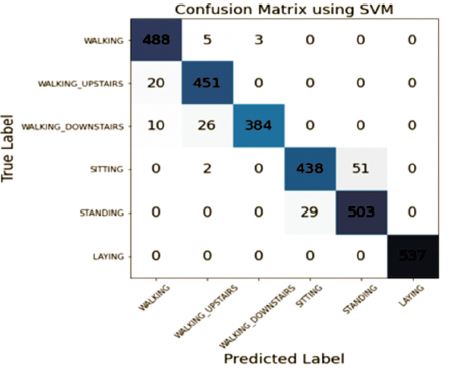
Figure 6. Confusion Matrix using SVM Classifier
In Figure 7, the ROC curve results illustrate the behaviour of different classes, and the results showed an accuracy of approximately 95% in the SVM algorithm. Figure 8 shows the list of all defined models and accuracies.
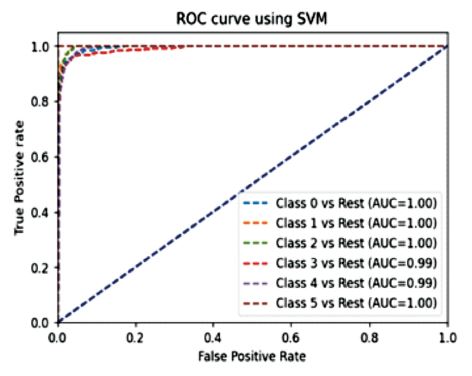
Figure 7. ROC AUC Curve per Class using SVM Classifier
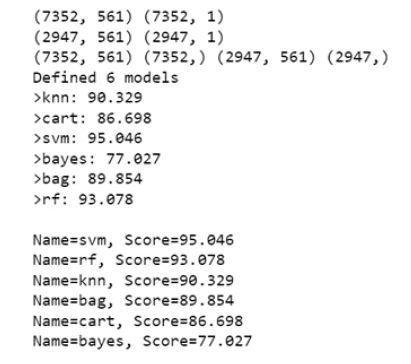
Figure 8. Defined Models and their Accuracies
This paper describes the important steps involved in the Activity Recognition Process (ARP) and provides a detailed explanation of each phase of the ARP pipeline. It also includes the Machine Learning (ML) methods used for the HAR model and the six algorithms used to determine the most accurate one.
During the data collection phase, it was observed that the number of new sensors and similar devices was increasing with time. This trend not only included the introduction of new types of sensors but also reflected the increasing diversity of the population. To keep up with these changes, the researchers took advantage of the increasing number of sensors and devices and incorporated them into the data collection process to obtain more accurate data, thus increasing the overall accuracy of the HAR model. Although this process required several trials and errors, it proved to be helpful in the end.
Furthermore, various combinations of the data can be experimented with to enhance the model's overall performance. However, incorporating new sensors may pose a challenge as they may have different specifications, leading to inconsistencies in the data. To mitigate this issue, the pre-processing phase should be executed meticulously to minimize signal differences between different sources.
Support Vector Machine (SVM) outperformed other Machine Learning Algorithms, with Random Forest being the closest in terms of accuracy. It was observed that Machine Learning (ML) algorithms performed better than many Deep Learning algorithms if proper pre-processing, tuning, and testing of the data were done.
Further research can be done to discover new and better features that can efficiently represent the key traits of human activity. This can be achieved by combining the professional domain knowledge contained in handmade traits with the fairness of auto-generated traits.
In addition, exploring other ML algorithms can lead to better possible outcomes in the future.
The proposed model utilized mobile inertial signals such as accelerometer and gyroscope to obtain data from the subject. This model can be extended to predict the state of the movements whether they are healthy or not according to the basic World Health Organization (WHO) guidelines, by monitoring the daily actions using smartphone sensors.