Figure 1. Transfer Learning
The utilization of online platforms for spreading hate speech has become a major concern. The conventional techniques used to identify hate speech, such as relying on keywords and manual moderation, frequently fall short and can lead to either missed detections or incorrect identifications. In response, researchers have developed various deeplearning strategies for locating hate speech in text. This paper covers a wide range of Deep Learning approaches, encompassing Convolutional Neural Networks and especially transformer-based models. It also discusses the key factors that influence the performance of these methods, such as the choice of datasets, the use of pre-processing strategies, and the design of the model architecture. In conjunction with summarizing existing research, it also identifies a selection of key hurdles and limitations of Deep Learning for discovering hate speech and has proposed a novel method to overcome them. In Bidirectional Long Short-Term Memory and BERT for Hate Speech Detection (BiDETECT), which involves adding a Bidirectional Long Short-Term Memory (BiLSTM) layer to Bidirectional Encoder Representations from Transformers (BERT) for classification, the hurdles include the difficulties in defining hate speech, the limitations of current datasets, and the challenges of generalizing models to new domains. It also discusses the ethical implications of employing Deep Learning to pinpoint hate speech and the need for responsible and transparent research in this area.
Recognizing hateful speech in social media and other virtual communities is a challenging problem that requires the development of effective and responsible computational techniques. The term "hate speech" refers to any speech or expression that is intended to offend, intimidate, or harm a particular individual or group based on ancestry, heritage, ethnicity, gender expression, or other characteristics. In the context of communal interactions and media, hate speech can take many forms, including written posts, images, videos, and other types of content.
It is important to note that hate speech is not the same as criticism or disagreement. Hate speech is typically characterized by its intention to harm or offend a particular group of people and its use of derogatory language or slurs. Examples of hate speech on social media could include racist or sexist comments, threats of violence, or other forms of inflammatory or offensive language (Badjatiya et al., 2017; Davidson et al., 2017).
An important obstacle in hate speech mining is the challenge of capturing complex patterns in text. Traditional Machine Learning (ML) approaches such as support vector machines and decision trees are limited in their ability to model the nuances and subtleties of natural language. On the other hand, advanced cognitive computing strategies such as Recurrent Neural Networks (RNN) and Convolutional Neural Networks (CNN) are capable of capturing these patterns and have shown significant improvements in performance.
For instance, a recent study utilized a convolutional neural network to detect hate speech in virtual forum posts. The model was trained on a significant number of annotated tweets, resulting in high accuracy for identifying hate speech. The paper also explored the use of various word embeddings, such as word2vec and GloVe, to represent words in the tweets (Mikolov et al., 2013; Pennington et al., 2014). These embeddings capture semantic relationships between words and provide additional information for the model to learn from. Another approach for detecting hateful language is through the use of Natural Language Processing techniques, specifically sentiment analysis and sentiment lexicons. These techniques can provide insights into the emotional content of text and help identify offensive or hateful language (Malik et al., 2022).
In a recent study, researchers used a sentiment lexicon to classify comments on a news website as positive, negative, or neutral and found that the majority of hateful comments were classified as negative. Caselli et al. (2020) existing models such as Hate speech detection using Bidirectional Encoder Representations from Transformers (HateBERT), which retrains Bidirectional Encoder Representations from Transformers (BERT) for abusive language detection in English and other languages, have not achieved efficient accuracy (Devlin et al., 2018). This paper proposes an innovative architecture that fuses a Bidirectional Long Short-Term Memory(BiLSTM) layer before the classifier in the foundational BERT architecture, resulting in improved accuracy compared to existing models.
While Deep Learning techniques have the potential to benefit hate speech discovery, it also has some disadvantages. One significant challenge is the absence of standard definitions and datasets for hate speech. Various researchers and organizations may have different interpretations of hate speech, which can affect the model's performance. Moreover, the present datasets for hate speech detection are often limited in size and diversity, and may not adequately represent the complete range of hateful content that exists online.
The detection of hate speech involves the use of computational techniques to identify language that is intended to disparage, threaten, or harm individuals or groups based on their personal characteristics. This type of speech can take various forms, including written, spoken, or visual content, and is often spread through social media and internet platforms. The widespread use of these platforms has made hate speech detection an urgent problem, as it has the potential to cause harm and negative social consequences. The detection of hateful speech is a complex issue that requires the development of responsible and effective computational techniques. Researchers from multiple fields, including computer science, natural language processing, and social psychology, have contributed to this research area, which has significant implications for social media and online platforms.
Hate language on social media platforms such as Twitter (Malik et al., 2022), YouTube (Ottoni et al., 2018), and Reddit (Mittos et al., 2020), use a range of traditional methods as well as recently highlighted transformer models. Aizawa (2003) investigated the use of Machine Learning to classify tweets containing hate speech. To achieve this, the researchers collected a corpus of 24,000 tweets and used crowd-sourcing to categorize them as hate speech, profanity, or neither. Various features were extracted from the tweets, including ngrams and metadata such as the quantity of hashtags, references, retweets, mentions, links, and shares contained in the messages. It also performed Part Of Speech (POS) tagging on the tweets. In experiments using varying multi-class classifiers, they found that Logistic Regression with L2 regularization was effective in identifying hate speech. This paper uses the same dataset for experimentation.
Hate speech detection has traditionally relied on techniques such as Term Frequency-Inverse Document Frequency (TF-IDF) and character-level n-grams for feature representation (Aizawa, 2003; Davidson et al., 2017; Waseem & Hovy, 2016). Support Vector Machines (SVMs), Logistic Regression, Random Forest, Naïve Bayes, and Gradient Boost Decision Tree are supervised and ensemble Machine Learning algorithms used for classification and regression tasks. Among these algorithms, XGBoost (eXtreme Gradient Boosting) with TFIDF has performed the best and exhibited the most competitive results (Aizawa, 2003). In this approach, each tweet is represented as a TF-IDF object, which is a dictionary of terms where the value of each entry is based on the product of the Term's Frequency (TF) within the tweet and its Inverse Document Frequency (IDF) within the entire dataset.
Machine Learning (ML) has demonstrated its effectiveness in numerous domains, such as human translation, voice, image, and forecasting, as well as in other applications. These techniques have been successful in identifying patterns and relationships in data, allowing for accurate predictions or classifications. The use of machine learning (ML) to detect hate speech on social media has limitations that must be considered, including the inability to capture context, dependence on manual feature engineering, limited scalability, poor generalization, and a lack of interpretability. These limitations are overcome by Deep Learning methods, which have several advantages.
Deep Learning methods for uncovering hate speech use deep neural networks that can accept various types of feature encoding as input. These methods are generally more effective than traditional approaches because they eliminate the need for manual feature engineering. Popular Artificial Neural Network (ANN) architectures used in hate speech detection include Convolutional Neural Networks (CNNs) (Gambäck & Sikdar, 2017), Long Short- Term Memory (LSTM), and Bidirectional LSTM (Bi-LSTM). Word embedding strategies use distributed representations of vocabulary in vectorized forms, enabling downstream text mining tasks. Word embedding models such as word2vec (Mikolov et al., 2013) and Glove (Pennington et al., 2014) encode semantic meaning between words using word-word co-occurrence probabilities (Mozafari et al., 2020). These models have been extensively adopted in uncovering hate speech in conjunction with sentiment analysis and have been combined with traditional and deep neural network-based classifiers.
The use of LSTM, Bi-LSTM, and CNN in combination with classical word embedding techniques, such as Glove, has shown successful performance in hate speech detection. However, modern transformer-based embedding techniques, such as BERT and Efficiently Learning an Encoder that Classifies Token Replacements Accurately (ELECTRA) are often more accurate (Malik et al., 2022). Transformers can be combined with various algorithms, such as CNN and LSTM, to achieve impressive performance on hate speech detection datasets in multiple languages.
In 2018, several breakthrough techniques were introduced for Natural Language Processing (NLP) tasks, including Universal Language Model Fine-Tuning (ULMFiT) (Mozafari et al., 2020), Embeddings from Language Models (ELMO) (Mozafari et al., 2020), Generative Pretrained Transformer (GPT) (Radford et al., 2018), and BERT (Devlin et al., 2018). ULMFiT can be integrated into a variety of NLP tasks by initializing a global language model using an all-encompassing dataset and subsequently adjusting its parameters on the target task data. ELMO employs a Bidirectional LSTM (Long Short-Term Memory) artificial neural network, trained for a distinct purpose, to generate contextualized word embeddings. These embeddings capture the significance and usage of words within a particular context, enabling a more precise comprehension of language. GPT and BERT are two transformer-based language models that were pretrained using only a plain text corpus. BERT outperformed other models in a suite of subsequent Natural Language Processing tasks (Mozafari et al., 2020). This paper proposes the use of the pre-trained BERT model for hate speech identification and fine-tuning for the same.
The Machine Learning approach of transfer learning involves applying a model that has been learned for one task to another related task (Zhuang et al., 2020). Figure 1 shows the transfer learning. The aim is to transfer the knowledge gained from solving one problem to another that is distinct but connected.
Figure 1. Transfer Learning
One of the major advantages of transfer learning is that it can considerably reduce the amount of data and computing power required to train a new model. This is because the model has already learned important features and patterns from the original task, which can also be useful for the new task.
The example of BERT (Devlin et al., 2018), a cutting-edge language model trained on a diverse set of text data, illustrates its capability to understand the meanings of words and their relationships. This makes it well-suited for a wide range of applications, such as language translation, question answering, and text classification. Other typical NLP tasks include named entity recognition, which involves identifying and categorizing proper nouns in text, sentiment analysis, which involves assessing the emotional tone of text, and language generation, which involves generating natural language text or speech using algorithms.
BERT has been fine-tuned for a range of tasks such as sentiment analysis, named entity recognition, and language translation. BERT's pre-trained model demonstrated superior performance by leveraging its knowledge of language structure and semantics learned during pre-training.
In this paper, BERT will be used for transfer learning through fine-tuning for a specific task. The fine-tuning process involves adding task-specific layers on top of the pretrained model and training these layers using labeled data for the new task. The model can learn task-specific features while still utilizing its understanding gained during the pre-training phase.
The BERT (Bidirectional Encoder Representations from Transformers) model, developed by Google Research, is a large computational model that can learn and adapt to more data using complex, multi-layered neural networks (Pennington et al., 2014). It is a state-of-the-art language model that employs a transformer-based architecture and is trained on a comprehensive dataset of text. BERT uses multiple layers of self-attention and fully connected layers to process input text and generate output vectors that represent the text in a highdimensional space. This enables the model to capture complex relationships between words and their contexts within the input text. The number of variables used during training depends on the specific architecture of the model. The BERT base model has approximately 110 million parameters, while the BERT large model has around 340 million parameters.
The BERT (Bidirectional Encoder Representations from Transformers) model, developed by Google Research, is a large computational model that can learn and adapt to more data using complex, multi-layered neural networks (Pennington et al., 2014). It is a state-of-the-art language model that employs a transformer-based architecture and is trained on a comprehensive dataset of text. BERT uses multiple layers of self-attention and fully connected layers to process input text and generate output vectors that represent the text in a high dimensional space. This enables the model to capture complex relationships between words and their contexts within the input text. The number of variables used during training depends on the specific architecture of the model. The BERT base model has approximately 110 million parameters, while the BERT large model has around 340 million parameters.
The BERT model utilizes a variant of the Masked Language Modeling (MLM) objective during training, where certain words within the input text are randomly masked and the model is trained to predict the original words based on their contextual information. This methodology aids in the model's ability to understand the relationships between words in the input text and generate more accurate output vectors. BERT has gained significant popularity and has been applied to various Natural Language Processing tasks, setting new benchmarks in the field. The base model is designed to be more efficient and can be run on a single Graphics Processing Unit (GPU), while the large model requires more computational resources and is better suited for complex tasks. Figure 2 shows the overall pre-training procedure for BERT.
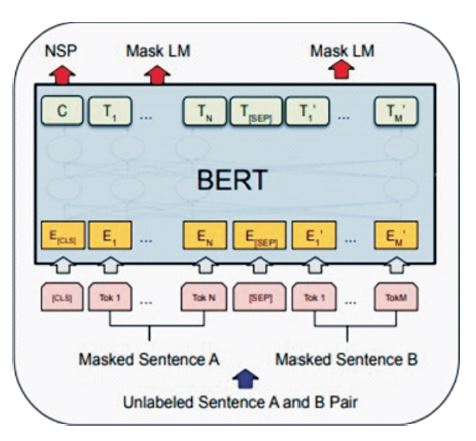
Figure 2. Pre-Training Procedures for BERT
The various layers of a neural module have the ability to capture different levels of syntactic and semantic contexts within the source information. This enables the network to extract and represent the underlying structure of the data at various scales, ranging from low-level details to high-level abstractions. As a result, the network can produce more accurate and comprehensive representations of the data points being analyzed.
The BERT model is composed of multiple layers stacked on top of each other, with the number of layers depending on the specific architecture of the model. The BERT base model consists of 12 layers, while the BERT large model has 24 layers. One of the major benefits of the BERT model is its ability to be fine-tuned for specific tasks, as opposed to building a new model from scratch for each new dataset (Mozafari et al., 2020). By fine-tuning a pretrained BERT model on a new task with a smaller amount of additional training data, the model can achieve greater accuracy and efficiency for the new task, making it a more convenient and faster option for Natural Language Processing tasks.
The experiments involved fine-tuning BERT on the dataset (Mozafari et al., 2020) and comparing the results with those obtained using other Machine Learning methods and models. It includes the experimental setup, the dataset that was employed for the paper, and the various configurations of BERT was tested. It will also present and analyze experimentation findings and appraise the consequences of the findings for the use of BERT in detecting hate speech in tweets.
The Davidson dataset (Davidson et al., 2019), compiled by researchers at the University of Michigan, contains over 25,000 tweets that have been categorized as either offensive, hate speech, or neither. These tweets were collected from various sources, including Twitter's public Application Programming Interface (API), and cover a wide range of topics and languages. The dataset is a large, diverse, and well-annotated collection of tweets that can be used to develop and evaluate models for detecting and classifying aggressive language. Table 1 shows the Davidson dataset ant its key statistics.
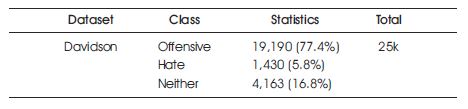
Table 1. Dataset and Statistics
Preprocessing is an important step in preparing tweets for training a Natural Language Processing model. This typically involves cleaning and normalizing the text, which can help enhance the efficacy of the model and produce more robust results.
One common pre-processing step for tweets is the use of regular expressions, which are patterns that can be used to match and extract specific information from text. Regular expressions can be used to remove unwanted characters, such as punctuation and special characters, from tweets, as well as to extract specific information like hashtags or user mentions.
Overall, the goal of pre-processing tweets is to prepare the data in a way that is conducive to training a Natural Language Processing model. By applying these techniques, one can improve the model's performance and make it more effective at tasks such as language classification and sentiment analysis. The following preprocessing steps were performed for the aforementioned dataset.
A pre-trained pyTorch BERT base model was customized from the Hugging Face repository on a dataset of tweet reads, where each tweet was categorized as belonging to hate speech or non-hate speech (Hugging Face, n.d.). This enabled the BERT model to learn contextual representations of the tweet data. For the study, 80% of the dataset was allocated for training to optimize the model's parameters during fine-tuning. An additional 10% of the data was set aside for validation to evaluate the model's performance during training, while the remaining 10% was used for testing to assess the model's performance after training was complete. Figure 3 depicts the architecture of the pre-trained pyTorch BERT base model used in this study.
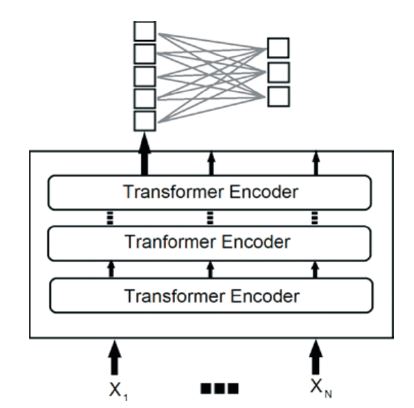
Figure 3. BERT (base) Architecture
The methods were implemented using Google Colaboratory, which is a free resource that provides access to a Tesla T4 GPU and 12G of Random Access Memory (RAM). A BiLSTM layer was added on top of the BERT base model with a hidden size of 768 as shown in Figure 4. BiLSTM is a variant of the neural network family that allows for the representation of dependencies beyond immediate context in sequential data, such as natural language. It processes input sequences in both forward and backward directions, making it suitable for tasks such as language modeling and language classification.

Figure 4. BERT (base) Architecture with Bi-LSTM Layer Connected to a Classifier Layer
The model was regularized by adding a dropout layer after the BERT encoder, which is a well-known technique in Deep Learning to prevent overfitting. A bidirectional Long Short-Term Memory (LSTM) layer was added after the BERT encoder to capture the temporal information in the sequential data. Another dropout layer was applied after the LSTM layer to further regularize the model. Finally, a linear layer was added on top of the LSTM layer to perform classification. This modified architecture was trained on the target task and showed improved performance compared to the original BERT model.
The dropout rate is a hyper parameter that determines the proportion of neurons that are randomly "dropped out" or deactivated during training in a neural network. This technique can help prevent overfitting and improve the generalization of the model. In this study, a dropout rate of 0.1 was used, indicating that 10% of the neurons in the network will be randomly deactivated during training. This can prevent neurons from overspecializing and forcing the network to rely on a broader set of neurons to make predictions.
To classify hate speech, a dense layer with a single output node and sigmoid activation function was added. The sigmoid function translates the output of the classifier layer to a value between 0 and 1, representing the likelihood that the input tweet belongs to the class of hate speech.
The model was trained using the binary cross-entropy loss function and optimized with the Adam algorithm, with a learning rate of 0.00002, a learning rate scheduler, and a batch size of 32. Additionally, an Adam epsilon value of 0.00000001 was utilized. Epsilon is used to prevent division by zero when the moving average of the squared gradients approaches zero, which can occur during early training when the model is randomly initialized and the gradients are small.
The research has demonstrated F1 scores ranging from 70% to 91% with transformer models and their variations (Malik et al., 2022). The incorporation of a CNN into a pretrained BERT model and its adaptation for a specific use case produced the best F1 score of 92% for the Davidson dataset, which significantly surpassed earlier baselines (Mozafari et al., 2020). The proposed model exhibited the capability to achieve an accuracy of 94%.
The present study proposes a novel approach to identify hate speech in social media using a combination of Bidirectional Encoder Representations from Transformers (BERT) and a Bidirectional Long Short-Term Memory (BiLSTM) layer. The approach involves fine-tuning a pretrained BERT base model on a dataset of tweets labeled as either hate speech or non-hate speech and adding a BiLSTM layer on top of the BERT base. A comparison of the performance of the proposed model with existing approaches, including transformer models and a CNNbased model, was carried out, and the proposed model was found to outperform these approaches on the Davidson dataset. The results suggest that the combination of BERT and a BiLSTM layer could be an effective approach for detecting hate language in virtual communities. However, there are still challenges to address and improve the effectiveness of uncovering hate languages in virtual communities, such as the lack of standard definitions and diverse datasets and the potential for models to perpetuate biases. Further research is required to tackle these challenges and advance the field.
One of the primary difficulties in uncovering hate language in virtual communities is the lack of standard definitions and datasets for hate speech. Various definitions of hate speech may exist among researchers and organizations, and these discrepancies could greatly influence the efficacy of the models. Moreover, the current datasets for mining hate language are often limited in size and diversity, and may not represent the full range of hateful content that exists online. As a result, models trained on these datasets may not generalize well to other contexts or languages.
Another challenge is the potential for Deep Learning models to perpetuate biases present in the data. For instance, if a biased dataset is used to train a model for uncovering hate languages, the model may learn to classify content as hate speech based on these biases rather than objective criteria. This can result in unfair and inappropriate classifications, which can undermine the credibility and effectiveness of the model.
Despite the challenges, there are opportunities to address the issues and improve the potency of Deep Learning for recognizing and combating abusive language. For example, efforts to develop standard definitions and more diverse and representative datasets could help improve the generalizability and fairness of Deep Learning models. In conjunction with these measures, alternative techniques can be employed to alleviate the potential negative consequences of biases present in the data. Adversarial training involves generating artificially perturbed inputs that are used to train the model in a bid to make it more robust to variations in the data. Data augmentation is another approach that involves artificially generating new data samples from the existing ones, in order to increase the diversity of the training set and reduce the model's reliance on any particular subset of the data.
Deep Learning has the potential to become a powerful tool for detecting hate languages in virtual communities, but it also faces significant challenges. Extensive and comprehensive analysis is needed to address these constraints and develop more effective and responsible computational techniques for mining hate languages.
Detecting hate speech in virtual communities is a complex task that requires advanced computational techniques. Deep learning and NLP techniques have shown promise, but challenges remain, including the lack of standard definitions and diverse datasets, as well as the potential for models to perpetuate biases. A novel approach using BERT and BiLSTM was proposed and found to outperform existing approaches on a dataset of tweets labeled as hate speech or non-hate speech. However, the lack of standard definitions and diverse datasets remains a primary difficulty in uncovering hate language in virtual communities, and further research is needed to address these challenges and advance the field.