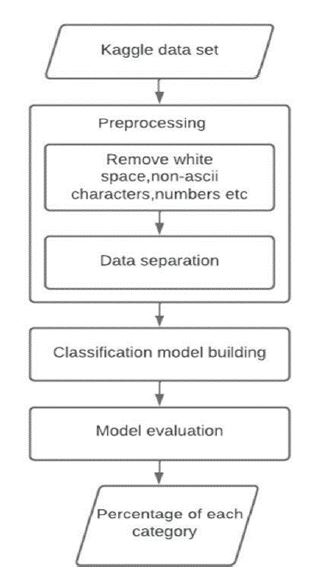
Figure 1. Methodology for the Proposed System
The objective of the paper is to mitigate internet negativity by identifying and blocking toxic comments related to a particular topic or product. The detrimental effects of social media abuse and harassment can cause people to refrain from expressing themselves. Although some platforms disable user comments altogether, this method is not efficient. The presence of toxicity in comments can assist platforms in taking appropriate measures. The paper aims to classify comments according to their toxicity levels for future blockage. The dataset comprises comments classified into six types, toxic, severe toxic, threat, obscene, identity hate, and insult. Multiple classification techniques will be employed to determine the most accurate one for the data. The authors will employ four types of classification and select the most precise one for each dataset. This methodology enables the authors to choose various datasets for the problem and select the most accurate classifier for each dataset.
In the current era, the growing prevalence of social media, news portals, blogs, Q&A forums, and other interactive websites has resulted in an increase in the number of nasty, harassing, insulting, or toxic comments that users receive. This type of behavior can make users victims of cyberbullying or online harassment, which can have serious consequences for them. In 2017, a survey conducted by the Pew Research Center found that 40% of Americans had personally experienced online harassment, with 20% having witnessed severe forms of online harassment, such as physical threats, stalking, or sexual harassment.
However, addressing this issue comes with several challenges. One major challenge is the problem of class imbalance in the dataset. As these types of comments are sparse in nature, they introduce skewness into the dataset. One of the challenges in the research is the data preprocessing, which can be time-consuming and requires a good understanding of the data. To address this challenge, the paper aims to select the most accurate model for the dataset and explore the possibility of changing the dataset as needed, with minimal data preprocessing.
This paper focuses on the problem of sentiment analysis, which has been defined in a Kaggle challenge involving researchers and industry professionals. Sentiment Analysis (SA) can be performed at two levels, such as binary or fine grained. Binary sentiment analysis involves assigning a positive or negative class to a text document, while fine grained sentiment analysis allows for multiclass classification or regression, such as classifying a text within a range of values. Other tasks within the domain of sentiment analysis include figurative language detection and aspect-based sentiment analysis.
This paper proposes a solution to the problem of online harassment and cyberbullying by creating a model that contains four classifiers, such as Logistic Regression (LR), Ki Nearest Neighbors (KNN) classifier, Support Vector Machine (SVM), and Random Forest, to address the sentiment analysis problem. A Wikipedia corpus dataset, which has already classified the data into six types of comments, is utilized. By selecting the most accurate model for the dataset and being open to changing the dataset, when necessary, an effective solution is aimed to be developed.
The primary objective of this research is to determine the level of toxicity in comments or texts, based on six different types of toxicities. To achieve this, commonly used classification algorithms were employed.
Yin et al. (2009) suggested improving the performance of a basic Term Frequency-Inverse Document Frequency (TF-IDF) model by adding sentiment and context features in the detection of harassment on Web 2.0. Agarwal et al. (2011) introduced a Part-of-Speech (POS)-Specific prior polarity feature for sentiment analysis on Twitter data and used a tree kernel to avoid the need for tedious feature engineering.
Srivastava et al. (2018) proposed that minimal preprocessing techniques are capable of achieving good model performance. Sharma and Patel (2018) proposed toxic comment classification using neural networks and machine learning to find the best possible optimized solutions for online toxic comment classification. Van Aken et al. (2018) presented multiple approaches for toxic comment classification where each approach makes different errors and can be combined into an ensemble with improved F1-measure. Çiğdem et al. (2019) proposed automatic detection of cyberbullying on social networks using data obtained from YouTube and other social media platforms. Stochastic Gradient Boosting (SGB) and Multi-Layer Perceptron (MLP) classifiers were found to have better results than other classifiers.
d'Sa et al. (2019) contributed to the design of binary classification and regression-based approaches aimed at predicting whether a comment is toxic or not. Zaheri et al. (2020) proposed a technique to classify instrumental text into toxic and non-toxic categories. Hosseini et al. (2017) proposed that an advisory can subtly modify a highly toxic phrase in a way that the system assigns a significantly lower toxicity score to it. Li (2018) suggested that natural language processing is one of the most influential tools that enable researchers to extract and analyze essential features from text-based information.
Carta et al. (2019) presented an approach capable of performing multi-class, multi-label classification of a decision within a range of six classes of toxicity. Risch et al. (2020) explained that it is difficult to explain the toxicity of a comment if none of the single words is considered toxic without context.
The proposal is to categorize different types of toxicity to improve analysis, despite the range of publicly available models, including toxicity, served through the Perspective Application Programming Interface (API). Despite their accessibility, these models are not perfect and may still generate errors. Additionally, users are not given the choice to specify the particular form of toxicity they wish to identify.
A multi-headed model using text analysis is being built to detect various types of toxicity, including threats, obscenity, insults, and identity-based hate.
The research is utilizing the Wikipedia corpus dataset, which has undergone toxicity ratings by human raters. A corpus represents a sample of genuine language usage within a relevant context and with a general goal. The dataset is composed of comments from user pages and article discussions spanning the years 2004 to 2015, and it was made available on Kaggle.
Figure 1 illustrates the methods that were followed to solve the problem. The first step in this process is to obtain a dataset from Kaggle. Once obtained, the data is preprocessed by removing white spaces, non-ASCII characters, and numbers, as well as separating the data into appropriate categories. The next step involves building a classification model using this preprocessed data. The model is then evaluated to ensure its accuracy, and finally, the results are presented as a percentage for each category.
Figure 1. Methodology for the Proposed System
Table 1 displays the count of each type of comment in the dataset. This information is useful for understanding the composition of the dataset and the prevalence of each type of toxicity in the comments. By analyzing this distribution, researchers can develop a better understanding of the different types of toxic comments and the patterns in which they appear in online discussions.

Table 1. Summary of Toxicity Labels
The bar graph in Figure 2 displays a comparison of the counts of each category in the dataset.
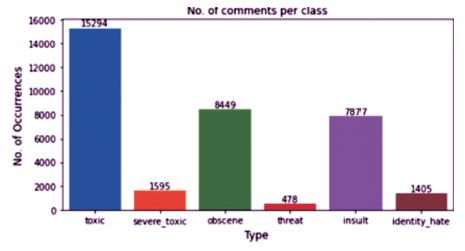
Figure 2. Occurrence of Each Category
The bar graph in Figure 3 represents the percentage of each category of comments. From the graph, it can be observed that 10% of the comments are toxic.
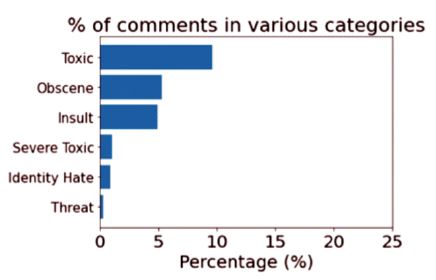
Figure 3. Percentage for Each Category
A Word Cloud is a technique used for data visualization that represents text data, where the size of each word corresponds to its frequency or importance. By using a Word Cloud, important textual data points can be emphasized. In this paper, a Word Cloud was used to visually analyze comment toxicity, as shown in Figure 4.

Figure 4. Words Frequented in Insult
The first stage of the proposed system is data preprocessing. In this stage, numbers, capital letters, and punctuation marks are removed from the comments. As comments may or may not contain these elements, all numbers, punctuation marks, and non-American Standard Code for Information Interchange (ASCII) characters are removed and the entire text is converted to lowercase. Figure 5 shows the data before preprocessing.

Figure 5. Before Preprocessing
The data after preprocessing, which involved the removal of numbers, non-ASCII characters, and punctuations, is displayed in Figure 6.

Figure 6. After Preprocessing
The basic pipeline used in this paper involved a count vectorizer or a TF-IDF vectorizer followed by a classifier. The classifiers used were Logistic Regression (LR), Random Forest (RF), K-Nearest Neighbour (KNN), and Support Vector Machines (SVM) with the One Vs RestClassifier model. Default parameters were used for all classifiers initially. However, the LR classifier performed well in terms of probabilities, prompting further improvement through parameter tuning.
To assess the generalizability of the model, the dataset was divided into training and validation sets with an 80:20 ratio. The data was then divided into six different datasets based on the ratio, as shown in Table 2.
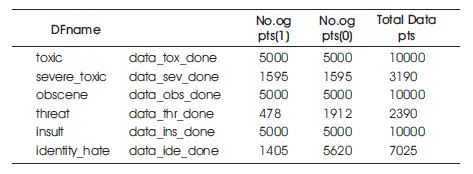
Table 2. Dataset Ratios for Training and Validation
The F1 score is a metric that ranges from 0 to 1, where 1 indicates the best performance and 0 indicates the worst. It is calculated as a weighted average of precision and recall. Each classifier algorithm was evaluated using its corresponding F1 score. The contribution of precision and recall to the F1 score is equal.
Using the Logistic Regression model, F1 scores were obtained for each dataset. The results are shown in Table 3.
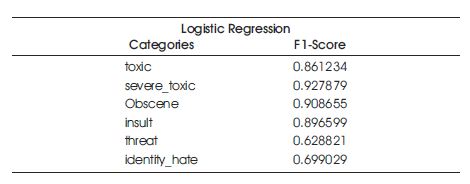
Table 3. Results of the Logistic Regression Model
The K-Nearest Neighbors model was created using n_neighbors = 5. The results of this model are shown in Table 4.
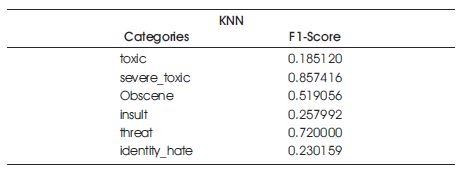
Table 4. Results of the KNN Model
The proposed system uses the Random Forest classifier with n_estimators set to 100 and random_state set to 42 as the parameters. The results of the experiment are presented in Table 5.
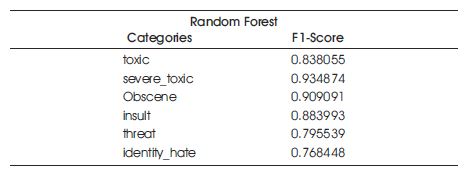
Table 5. Results of the Random Forest Classifier
The Support Vector Machine model was trained and the results are summarized in Table 6. The categories such as toxic, severe toxic, obscene, insult, threat and identity are included.
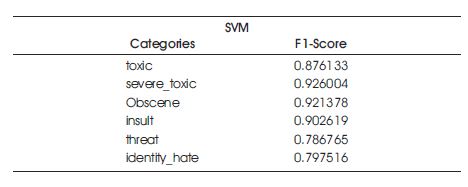
Table 6. Results of the Support Vector Machine Model
Based on the analysis of the scatter plot of different models, including Log Regression, KNN, SVM, and Random Forest in Figure 7, it can be inferred that the Random Forest model yields the most precise outcomes.
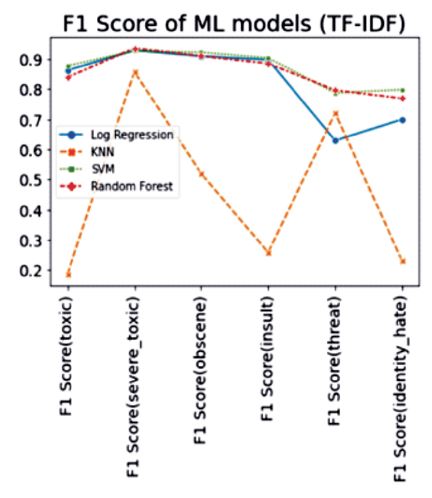
Figure 7. Performance Comparison of Different Classifier Models
Upon reviewing the outcomes, it can be inferred that the random forest classifier yielded the highest level of accuracy, with SVM following closely behind. The selection of the most accurate model was based on the highest F1 scores in each category. Future work could involve experimentation with different contextual word embeddings and deep learning approaches, as well as the implementation of an ensemble strategy to improve overall performance. This approach could be applied to various social media chat windows to detect and remove toxic language based on its category, helping to limit cyberbullying, harassment, and other inappropriate behavior in online communication.