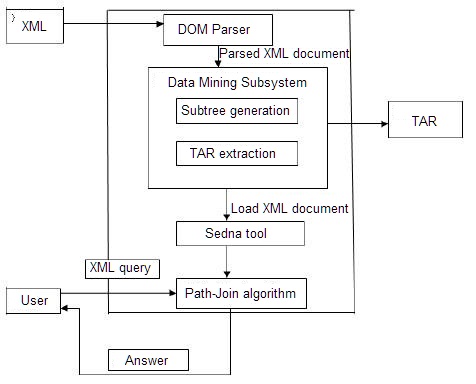
Figure 1. Proposed framework
Extensible Markup Language (XML) has become a de facto standard for storing, sharing and exchanging information across heterogeneous platforms. The XML content is growing day-by-day in rapid pace. Enterprises need to make queries on XML databases frequently. As huge XML data is available, it is a challenging task to extract required data from the XML database. It is computationally expensive to answer queries without any support. In this paper, the authors have presented a technique known as Tree-based Association Rules (TARs) mined rules that provide required information on structure and content of XML file and the TARs are also stored in XML format. The mined knowledge (TARs) is used later for XML query answering support. This enables quick and accurate answering. Distributed query processing is used to relate two or more databases using sedna tool. To search information from xml document, an algorithm called path-join algorithm is used. They also developed a prototype application to demonstrate the efficiency of the proposed system. The empirical results are very positive and query answering is expected to be useful in real time applications.
XML [3] has become a popular format for storing and sharing data across heterogeneous platforms. The XML format is neutral, flexible and interoperable. It is widely used in applications as it can allow applications to have communication, though they are built on different platforms. The XML documents are plenty in enterprises and the data retrieval can be done in two ways. The first approach is that the user gives keywords and the program searches for relevant documents. The second approach has given the XML queries that are answered. The first approach is done using conventional information retrieval [9] technique that works on the search process based on the given search word. With respect to query answering, it is not easy to process such request. To make this searching easy, this paper presents a data mining for XML query answering support. The XML documents are validated by either DTD or schema. However, schema presence is not mandatory to process XML file .This paper presents a data mining framework for XML query answering support. The XML documents essence is extracted and kept in another XML file in the form of TARs.
This XML file is loaded into the sedna [4] tool for retrieval. With the help of this XML query answering becomes easy. Then path-join algorithm is used to search and retrieve the data from the sedna tool. Figure 1 shows the proposed framework.
Figure 1. Proposed framework
There are three main areas that are related to our proposal: TARs, distributed query processing and path join algorithm.
Tree-based Association Rules are applied in the XML document to retrieve the contents of xml documents in an efficient manner. Distributed query processing is used to relate two or more databases using sedna tool. To search information from XML document, an algorithm called path-join algorithm is used.
Association rules describe the co-occurrence of data items in a large amount of collected data and are represented as implications of the form X _ Y , where X and Y are two arbitrary sets of data items. The quality of an association rule is measured by means of support and confidence. Support corresponds to the frequency of the set X Y in the data set, while confidence corresponds to the conditional probability of finding Y, having found X and is given by supp(X Y) /supp(X).
A Tree-based Association Rule is a tuple of the form Tr=(SB; SH; STr; CTr), where SB =( NB; EB; RB; lB; CB) andSH =(NH; EH; rH; lH; CH) are trees and STr and CTr are real numbers in the interval representing the support and confidence of the rule, respectively. A TAR describes the co-occurrence of the two trees SB and SH in an XML document. SB _ SH; SB is called the body or antecedent of Tr while SH is the head or consequent of the rule. Furthermore, SB is a subtree of SH with an additional property on the node labels: the set of tags of SB is contained in the set of tags of SH with the addition of the empty label "€": lSB (NSB) lSB(NSB) {}. The empty label is introduced because the body of a rule may contain nodes with unspecified tags, that is, blank nodes. Moreover, a rooted TAR (RTAR) is a TAR such that SB is a rooted subtree of SH, and an extended TAR (ETAR) is a TAR such that SB is an induced subtree of SH. Let count (S;D) denote the number of occurrences of a subtree S in the tree D and cardinality(D) denote the number of nodes of D. We formally define the support of a TAR SB _ SH as count(SH;D)/cardinality(D) and its confidence as count(SH;D)/count(SB;D) Given an XML document, we extract two types of TARs. A TAR is a structure TAR (sTAR) iff, for each node n contained in SH, cH(n) = ┴ , that is, no data value is present in sTARs, i.e., they provide information only on the structure of the document. A TAR, SB _ SH, is an instance TAR (iTAR) if SH contains at least one node n such that cH(n), that is, iTARs provide information both on the structure and on the data values contained in a document. Differently from DataGuides, sTARs do not show all possible paths in the XML document but only the frequent paths. In particular, for each fragment, its support determines how frequent the substructure is. This means that sTARs provide a simple path index which supports path matching and can be used for the optimization of the query process. An index for an XML data set is a predefined structure whose performance is maximized when the query matches exactly the designed structure. Therefore, the goal, when designing an index, is to make it as similar as possible to the most frequent queries. Finding frequent sub trees is described in [1,2, 5, 6, 7, 8]. Algorithm 1 finds frequent sub trees and calculates interesting rules.
Algorithm 1. Get-Useful-Rules (D, minsupp, minconf)
1: // frequent subtrees
2: FS =FindOftenSubtrees (D, minsupp)
3: ruleSet = Ø
4: for all s € FS do
5: // rules computed from s
6:transientSet = Determine-Rules(s; minconf)
7: // all rules
8: ruleSet = ruleSet ∪ transientSet
9: end for
10: return ruleSet
Operation 2. Determine-Rules (s; minconf)
1: ruleSet = Ø blackList= Ø
2: for all Cs , subtrees of s do
3: if Cs is not a subtree of any element in blackList then
4: conf = supp(s) / supp(Cs )
5: if conf > minconf then
6: newRule =(Cs ; s; conf; supp(s))
7: ruleSet =ruleSet ∪ {newRule}
8: else
9: blackList =blackList ∪Cs
10: end if
11: end if
12: end for
13: return ruleSet.
Sedna is a powerful, open source, native XML Database, written from the ground up in C/C++ by Team MODIS. The team has developed and is continuing to develop an XML Database which is starting to seriously boast the functionality and performance of mature relational databases such as MySQL and thus can be taken very seriously by application developers for production grade applications. Sedna's network protocol is completely binary based. Team MODIS did provide a Java API. This implementation sticks very closely to the original XML:DB API specification. It has been developed with production grade applications in mind. The utmost of care has gone into testing every single method and piece of functionality. Path–join algorithm enables faster retrieval of information from the database.
Path Join algorithms are sort-merge based algorithms to process ancestor-descendant type expressions.
Path_join(al,dl,sl)
ax=0,dx=0;
//to get the end position of parent
e=get_el(al[dx]);
//to get the end position of child
e1=get_el(dl[ax]);
while(get_parent(al))
{if(al[dx]==sl)
{e=get_el(al[dx]);
output(al[dx]);
else
dx++;
}}while(get_child(dl))
{if(e(al[dx])==e1(dl[ax]))
{output(dl[ax]);
dl++; // point to the next child node
}
else {
ax++; }}
Time required for the extraction of the intentional knowledge from an XML database. As none of the nodes increases extraction, time increases initially.
Answer Time of getting intentional answer is comparatively less than that of extensional answer, as instead of accessing original document mined rule file is used to answer the query.
Accuracy of intentional answer is measured in terms of precision and recall. Query answering depends on support threshold. When support is high, then chance of correct answering is high as less no of rules are to be accessed.
The main goals achieved are: Storing information into a database in xml format. Tree-Based Association rules are applied into Xml database and loading the database into sedna tool. Searching and retrieving the information from XML document is performed using path-join algorithm. In future we would perform database operations like updation, deletion of records from xml database. Thereby XML database can be used as an alternate for relational databases.