Intrusion Detection System Using Data Mining
Minakshi Sahu * Brojo Kishore Mishra ** Susanta Kumar Das *** Ashok Mishra ****
* Research Scholar, Department of Computer Science and Engineering, Centurion University of Technology and Management, Odisha, India.
** Associate Professor, Department of Information Technology, C.V. Raman College of Engineering, Bhubaneswar, Odisha, India.
*** Reader, P.G Department of Computer Science, Berhampur University, Odisha, India.
**** Professor, Department of Mathematics, Centurion University of Technology and Management, Odisha, India.
Abstract
Intrusion Detection system has become the main research focus in the area of information security. Last few years have witnessed a large variety of technique and model to provide increasingly efficient intrusion detection solutions. Traditional Network IDS are limited and do not provide a comprehensive solution for these serious problems which are causing many types of security breaches and IT service impacts. They search for potential malicious abnormal activities on the network traffics; and sometimes succeed to find true network attacks and anomalies (true positive). However, in many cases, systems fail to detect malicious network behaviors (false negative) or they fire alarms when there is nothing wrong in the network (false positive). In accumulation, they also require extensive and meticulous manual processing and interference. The authors advocate here applying Data Mining (DM) techniques on the network traffic data is a potential solution that helps in design and development of a better efficient intrusion detection system. Data mining methods have been used to build the automatic intrusion detection systems. The central idea is to utilize auditing programs to extract the set of features that describe each network connection or session, and apply data mining programs, to learn that capture intrusive and non-intrusive behavior. In this research paper, the authors are focusing on Data Mining based intrusion detection system.
Keywords :
- Anomaly Detection,
- Data Mining Techniques,
- Intrusion Detection,
- Misuse Detection.
Introduction
In recent years, as second line of security defense after firewall, the intrusion detection technique has got rapid development. It plays a very important role in attack detection, security check and network inspect. But with the continuous popularization of network application, the rapid broadening of network bandwidth and the rapid improvement, the problems of misjudgment, misdetection and lack of real-time response to attack that are inherent for the intrusion detection technique are becoming more and more thrown out, which has badly affected the practical value of intrusion detection product. The authors may analyze its root cause by the data resource of intrusion detection technique. There are two main data resource for the intrusion detection technique: network data packs for the network-based IDS (intrusion detection system) and system audit logs for the host-based IDS. The increasing speed of the former data traffic is greater than the one of processing capacity of IDS; the latter isn’t designed especially for IDS and its recorded characteristic variables can’t usually meet the need of IDS, more or less, and usually need complex processing algorithm for data mining. So enormous processing data and complicated signature selecting are the main problems that make the intrusion detection technique get into difficulties and directly affect the per formance and real-time characteristic of intrusion detection.
1. Intrusion Detection
An intrusion is an active sequence of related events that deliberately try to cause harm, such as rendering system unusable,accessing unauthorized information or manipulating such information. To record the information about both successful and unsuccessful attempts, the security professionals place the devices that examine the network traffic, called sensors. These sensors are kept in both front of the firewall (the unprotected area) and behind the firewall (the protected area) and values through comparing the information are recorded by the two.
An Intrusion Detection System (IDS) can be defined as a tool, method and resource to help identify, access and report unauthorized activity. Intrusion Detection is typically one part of an overall protection system that is installed around a system or device. IDS work at the network layer of the OSI model and sensors are placed at the choke points on the network. They analyze packets to find specific patterns in the network traffic, if they find such a pattern in the traffic, an alert is logged and a response can be based on data recorded.
1.1 The need for Intrusion Detection Systems
A computer system should provide confidentiality, integrity and assurance against denial of service. However, due to increased connectivity (especially on the Internet), and the vast spectrum of financial possibilities that are opening up, more and more systems are subject to attack by intruders. These subversion attempts try to exploit flaws in the operating system as well as in application programs and have resulted in spectacular incidents like the Internet Worm incident of 1988 [5].
There are two ways to handle subversion attempts. One way is to prevent subversion itself by building a completely secure system. The authors could, require all users to identify and authenticate themselves; they could protect data by various cryptographic methods and very tight access control mechanisms. However this is not really feasible because,
- In practice, it is not possible to build a completely secure system. Miller [3] gives a compelling report on bugs in popular programs and operating systems that seems to indicate that (a) bug free software is still a dream and (b) no one seems to want to make the effort to try to develop such software. Apart from the fact that they do not seem to be getting our money's worth when they buy software, there are also security implications when our E-mail software, for example, can be attacked. Designing and implementing a totally secure system is thus an extremely difficult task.
- The vast installed base of systems worldwide guarantees that any transition to a secure system, (if it is ever developed) will be long in coming.
- Cryptographic methods have their own problems. Passwords can be cracked, users can lose their passwords, and entire crypto-systems can be broken.
- Even a truly secure system is vulnerable to abuse by insiders who abuse their privileges.
- It has been seen that the relationship between the level of access control and user efficiency is an inverse one, which means that the stricter the mechanisms, the lower the efficiency becomes.
The authors see that they are stuck with systems that have vulnerabilities for a while to come. If there are attacks on a system, they would like to detect them as soon as possible (preferably in real-time) and take appropriate action. This is essentially what an Intrusion Detection System (IDS) does. An IDS does not usually take preventive measures when an attack is detected, it is a reactive rather than pro-active agent. It plays the role of an informant rather than a police officer.
The most popular way to detect intrusions has been by using the audit data generated by the operating system. An audit trail is a record of activities on a system that are logged to a file in chronologically sorted order. Since almost all activities are logged on a system, it is possible that a manual inspection of these logs would allow intrusions to be detected. However, the incredibly large sizes of audit data generated (on the order of 100 Megabytes a day) make manual analysis impossible. IDSs automate the drudgery of wading through the audit data jungle. Audit trails are particularly useful because they can be used to establish guilt of attackers, and they are often the only way to detect unauthorized but subversive user activity.
Many times, even after an attack has occurred, it is important to analyze the audit data so that the extent of damage can be determined, the tracking down of the attackers is facilitated, and steps may be taken to prevent such attacks in the future. An IDS can also be used to analyze audit data for such insights. This makes IDSs valuable as real-time as well as post-mortem analysis tools.
1.2 Classification of Intrusion Detection Systems
Intrusions can be divided into 6 main types [21]
- Attempted break-ins: which are detected by a typical behavior profile or violations of security constraints.
- Masquerade attacks: which are detected by atypical behavior profiles or violations of security constraints.
- Penetration of the security control system: which are detected by monitoring for specific patterns of activity.
- Leakage: which is detected by atypical use of system resources.
- Denial of service: which is detected by atypical use of system resources.
- Malicious use: which is detected by a typical profiles, violations of security constraints, or use of special privileges.
However, The techniques of intrusion detection can be divided into two main types.
- Anomaly Detection: Anomaly detection techniques assume that all intrusive activities are necessarily anomalous. This means that if they could establish a "normal activity profile" for a system, They flag all system states varying from the established profile by statistically significant amounts as intrusion attempts. However, if they consider that the set of intrusive activities only intersects the set of anomalous activities instead of being exactly the same, they find a couple of interesting possibilities: (1) Anomalous activities that are not intrusive are flagged as intrusive. (2) Intrusive activities that are not anomalous result in false negatives (events are not flagged intrusive, though they actually are). This is a dangerous problem, and is far more serious than the problem of false positives.

The main issues in anomaly become the selection of threshold levels so that neither of the above 2 problems is unreasonably magnified, and the selection of features to monitor. Anomaly detection systems are also computationally expensive because of the overhead of keeping track of, and possibly updating several system profile metrics. Some systems based on this technique are discussed in Section 4 while a block diagram of a typical anomaly detection system is shown in Figure 1.
- Misuse Detection: The concept behind misuse detection schemes is that there are ways to represent the attacks in the form of a pattern or a signature so that even variations of the same attack can be detected. This means that these systems are not unlike virus detection systems they can detect many or all known they are of little use for as yet unknown attack methods. An interesting point to note is that anomaly detection systems try to detect the complement of "bad" behavior. Misuse detection systems try to recognize known "bad" behavior. The main issues in misuse detection systems are how to write a signature that encompasses all possible variations of the pertinent attack, and how to write signatures that do not also match non-intrusive activity. Several methods of misuse detection, including a new pattern matching model are discussed later. A block diagram of a typical misuse detection system is shown in Figure 2.
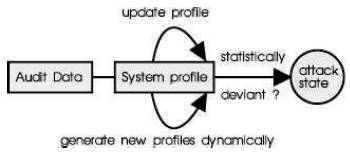
Figure 1. A Block diagram of a typical anomaly detection system
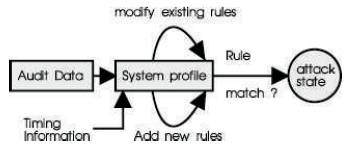
Figure 2. A Block diagram of a typical misuse detection system
2. Data Mining
In this information age, the authors believe that the information leads to power and success, and thanks to sophisticated technologies such as computers, satellites, etc., we have been collecting tremendous amounts of information. Initially, with the advent of computers and means for mass digital storage, we started collecting and storing all sorts of data, counting on the power of computers to help sort through this amalgam of information. Unfortunately, these massive collections of data stored on disparate structures very rapidly became overwhelming. This initial chaos has led to the creation of structured databases and Database Management Systems (DBMS). The efficient database management systems have been ver y important assets for management of a large corpus of data and especially for effective and efficient retrieval of particular information from a large collection whenever needed. The proliferation of database management systems has also contributed to recent massive gathering of all sorts of information. Today, we have far more information than they can handle: from business transactions and scientific data, to satellite pictures, text reports and military intelligence. Information retrieval is simply not enough anymore for decision-making. Confronted with huge collections of data, we have now created new needs to help us to make better managerial choices. These needs are automatic summarization of data, extraction of the “essence” of information stored, and the discovery of patterns in raw data.
With the enormous amount of data stored in files, databases, and other repositories, it is increasingly important, if not necessary, to develop a powerful means for analysis and perhaps interpretation of such data and for the extraction of interesting knowledge that could help in decision-making.
Data Mining, also popularly known as Knowledge Discovery in Databases (KDD), refers to the nontrivial extraction of implicit, previously unknown and potentially useful information from data in databases. While data mining and knowledge discovery in databases (or KDD) are frequently treated as synonyms, data mining is actually part of the knowledge discovery process. Figure 3 shows the data mining as a step in an iterative knowledge discovery process.
In principle, data mining is not specific to one type of media or data. Data mining should be applicable to any kind of information repository. However, algorithms and approaches may differ when applied to different types of data.
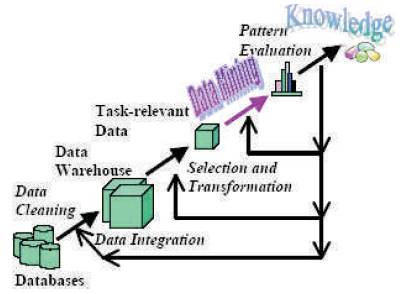
Figure 3. Data Mining is the core of Knowledge Discovery process
3. Intrusion Detection Using Data Mining Techniques
Many researchers have investigated the deployment of data mining algorithms and techniques for intrusion detection [1, 10-13, 17-20]. Examples of these techniques include [11]:
- Feature selection data analysis: The main idea in feature selection is to remove features with little or no predictive information from the original set of features of the audit data to form a subset of appropriate features. Feature selection significantly reduces computational complexity resulting from using the full original feature set. Other benefits of feature selection are: improving the prediction of ID models, providing faster and cost effective ID models and providing better understanding and virtualization of the generated intrusions. Feature selection algorithms are typically classified into two categories: subset selection and feature ranking. Subset selection algorithms use heuristic search such as genetic algorithms, simulated annealing and greedy hill climbing to generate and evaluate a subset of features as a group for suitability. On the other hand, feature ranking uses a metric to rank the features based on their scores on that metric and removes all features that do not achieve an adequate score [8].
- Classification analysis: The goal of classification is to assign objects (intrusions) to classes based on the values of the object’s features. Classification algorithms can be used for both misuse and anomaly detections [10]. In misuse detection, network traffic data are collected and labeled as “normal” or “intrusion”. This labeled data set is used as a training data to learn classifiers of different types (e.g., SVM, NN, NB, or ID3) which can be used to detect the known intrusions. In anomaly detection, the normal behaviour model is learned from the training dataset that are known to be “normal” using learning algorithms [9]. Classification can be applied to detect intrusions in data streams; a predefined collection of historical data with their observed nature helps in determining the nature of newly arriving data stream and hence will be useful in classification of the new data stream and to detect the intrusion. Data may be non sequential or sequential in nature. Non-sequential data are those data where order of occurrence is not important, while sequential data are those data where the order of occurrence with respect to time is important to consider. Using data mining and specially classification techniques can play a very important role on two dimensions; the similarity measures and the classification schema [2].. Kumar [15] stated that any data, facts, concepts, or instructions, can be represented in a formalized manner suitable for communication, interpretation, or processing by humans or by automated means. Kumar [15] classified sequential data into temporal or non-temporal, where temporal data are those data, which have time stamp attached to it and non-temporal data are those which are ordered with respect to some other dimension other than time such as space. Temporal data can be classified into discrete temporal sequential data such as logs time or continuous temporal sequential data such as observations.
- Clustering analysis: Clustering assign objects (intrusions) to groups (clusters) on the basis of distance measurements made on the objects. As opposed to classification, clustering is an unsupervised learning process since no information is available on the labels of the training data. In anomaly detection, clustering and outlier analysis can be used to drive the ID model [16]. Distance or similarity measure plays an important role in grouping observations in homogeneous clusters. It is important to formulate a metric to determine whether an event is deemed normal or anomalous using measures such as Jaccard similarity measure, Cosine similarity measure, Euclidian distance measure and Longest Common Subsequence (LCS) measure. Jaccard similarity coefficient is a statistical measure of similarity between sample sets and can be defined as the degree of commonality between twosets [14]. Cosine similarity is a common vector based similarity measure and mostly used in text databases and it calculates the angle of difference in direction of two vectors, irrespective of their lengths [6]. Euclidean distance is a widely used distance measure for vector spaces, for two vectors X and Y in an ndimensional Euclidean space; Euclidean distance can be defined as the square root of the sum of differences of the corresponding dimensions of the vectors [14]. The Longest Common Subsequence (LCS) is a new similarity measure developed recently, where the degree of similarity between two sequences can be measured by extracting the maximal number of identical symbols existing in both sequences in the same order or the longest common subsequences. Kumar [16] stated that the length of this subsequence describes the similarity between the sequences. He considered two sequences X[1…m] and Y[1… n] comes from D different symbols belonging to the alphabet T. A subsequence S[1… s] where (0≤ s ≤ m) of X, can be obtained by deleting arbitrarily (m -s) symbols from X. If S is also a subsequence of Y, then S is a common subsequence of X and Y, denoted by CS(X,Y). The longest common subsequence of X and Y, abbreviated by LCS(X,Y) is the CS(X,Y) having maximal length, whose length is denoted by LLCS. Mining models for network intrusion detection view data as sequences of TCP/IP packet, and K-Nearest neighborhood algorithms is commonly used in all techniques with different similarity measures [4], [7], [13].
Finally, clustering and classification algorithms must be efficiently scalable, and can handle network data of high volume, dimensionality, and heterogeneity [10]. Han and Kamber [10] mentioned some other DM approaches that can be used for ID and they summarize them as follows,
- Association and correlation analysis: The main objective of association rule analysis is to discover association relationships between specific values of features in large datasets. This helps to discover the hidden patterns and has a wide variety of applications in business and research. Association rules can help to select discriminating attributes that are useful for intrusion detection. It can be applied to find relationships between system attributes describing network data. New attributes derived from the aggregated data may also be helpful, such as summary counts of traffic matching a particular pattern.
- Stream data analysis: Intrusions and malicious attacks are of dynamic nature. Moreover, data streams may help to detect intrusions in the sense that an event may be normal on its own, but considered the malicious viewed as part of a sequence of events [10]. Thus, it is necessary to perform the intrusion detection in data stream, real-time environment. This helps to identify the sequences of events that are frequently encountered together, find sequential patterns, and identify outliers. Other data mining methods for finding evolving clusters and building dynamic classification models in data streams can be applied for these purposes.
- Distributed data mining: Intruders can work from several different locations and attack many different destinations. Distributed data mining methods may be utilized to analyze network data from several network locations, this helps to detect the distributed attacks and prevent attackers in different places from harming their data and resources.
- Visualization and querying tools: Visualization data mining tools that include features to view classes, associations, clusters, and outliers can be used for viewing any anomalous patterns detected. Graphical user interface associated with these tools allow security analysts to understand the intrusion detection results, evaluate IDS performance and decide on future enhancements for the system.
Conclusion
Intrusion Detection is still a fledgling field of research. However, it is beginning to assume enormous importance in today's computing environment. The combination of facts such as the unbridled growth of the Internet, the vast financial possibilities opening up in electronic trade, and the lack of truly secure systems make it an important and pertinent field of research. In this paper, the authors have presented Intrusion Detection Systems by applying Data mining techniques to efficiently detect the various types of network intrusions [9,22].
References
[1]. A. Chauhan, G. Mishra, and G. Kumar, (2011). “Survey on Data mining Techniques in Intrusion Detection”, International Journal of Scientific & Engineering Research Vol.2 Issue 7.
[2]. A. Sharma, A.K. Pujari, and K.K. Paliwal, (2007). "Intrusion detection using text processing techniques with a kernel based similarity measure", presented at Computers & Security, pp.488-495.
[3]. Barton P Miller, David Koski, Cjin Pheow Lee, Vivekananda Maganty, Ravi Murthy, Ajitkumar Natarajan, Jeff Steidl. (1995). “Fuzz Revisited: A Reexamination of the Reliability of UNIX Utilities and Services”. Computer Sciences Department, University of Wisconsin.
[4]. Dartigue, C., Hyun Ik Jang, Wenjun Zeng, (2009). “A New Data-Mining Based Approach for Network Intrusion Detection”, 7th Annual Communication Networks and Services Research Conference (CNSR), 11-13 May.
[5]. Eugene H Spafford. (1989). “The Internet Worm Program: An Analysis”. In ACM Computer Communication Review, 19(1), pages 17-57, Jan.
[6]. G. Qian, S. Sural, Y. Gu, and S. Pramanik, (2004). "Similarity between Euclidean and cosine angle distance for nearest neighbor queries", in Proc. SAC, pp.1232- 1237.
[7]. Gudadhe, M., Prasad, P., Wankhade, K., “A new data mining based network Intrusion Detection model” International Conference on Computer and Communication Technology (ICCCT), 17-19 Sept
[8]. Guyon and A. Elisseeff, (2003). “An Introduction to Variable and Feature Selection”, Journal of Machine Learning Research 3, 1157-1182.
[9]. Jack Timofte and Praktiker Romania, (2007). “Securing the Organization with Network Performance Analysis”, Economy Informatics, 1-4.
[10]. Jiawei Han and. Micheline Kamber, (2011). “Data Mining: Concepts and Techniques”, Morgan Kufmann, 2nd edition, 3rd edition.
[11]. M. Hossain “Data Mining Approaches for Intrusion Detection : Issues and Research Directions ” , http://www.cse.msstate.edu/~bridges/papers/iasted. pdf.
[12]. Mohmood Husain, “Data Mining Approaches for Intrusion Detection: Issues and Research Directions”, Department of Computer Science, Mississippi State University, MS 39762, USA.
[13]. P. Dokas, L. Ertoz, V. Kumar, A. Lazaevic. J. Srivastava, and P. Tan, (2002). “Data Mining for Network Intrusion Detection”, http://minds.cs.umn.edu/papers/nsf_ngdm_ .pdf.
[14]. P. Kumar, M.V. Rao, P.R. Krishna, and R.S. Bapi, (2005). "Using Sub-sequence Information with kNN for Classification of Sequential Data", in Proc. ICDCIT, pp.536- 546.
[15]. P. Kumar, P.R. Krishna, B. S Raju and T. M Padmaja, (2008). “Advances in Classification of Sequence Data”, Data Mining and Knowledge Discovery Technologies. IGI Global, pp.143-174.
[16]. P. Kumar, R.S. Bapi, and P.R. Krishna, (2010). "A New Similarity Metric for Sequential Data", presented at IJDWM, pp.16-32.
[17]. S. Axelsson, (2000). “Intrusion Detection Systems: A Survey and Taxonomy”. Technical Report 99-15, Chalmers Univ. Marc h. http://citeseer.ist. psu .edu/viewdoc/summary?doi=1 0.1.1.1.6603.
[18]. S. Mukkamala et al. (2002). “Intrusion detection using neural networks and support vector machines”, IEEE IJCNN.
[19]. S. Terry Brugger, (2004). “Data Mining Methods for Network Intrusion detection”, University of California, Davis. http://www.mendeley.com/research/dataminingmethods- for-network-intrusion-detection/.
[20]. S.J. Stolfo, W. Lee. P. Chan, W. Fan and E. Eskin, (2001). “Data Mining – based Intrusion Detector: An overview of the Columbia IDS Project” ACM SIGMOD Records Vol. 30, Issue 4.
[21]. Steven E Smaha. (1988). Haystack: An Intrusion Detection System. In Fourth Aerospace Computer Security Applications Conference, pages 37-44, Tracor Applied Science Inc., Austin, Texas, December.
[22]. Weili Han, Dianxun Shuai and Yujun Liu, (2004). “Network Performance Analysis Based on a Computer Network Model”, Lecture Notes in Computer Science, Volume 3033/2004, 418-421, DOI: 10.1007/978-3-540- 24680-0_69.