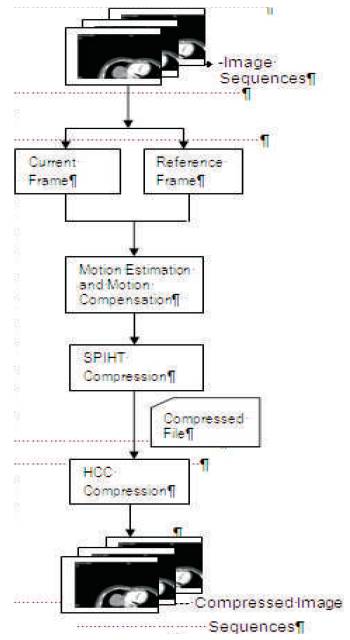
Figure 1. Flow chart for the encoder side of the proposed method
Medical image sequences are produced in enormous amount which requires a large storage capacity. These image sequences are of great importance, hence it is necessary to develop a system that produces high degree of compression while preserving the medical information. Lossless compression Technique is required to reduce the number of bits to store these image sequences and take less time to transmit over the network. This paper proposes a method that combines SPIHT with HCC to enhance the compression ratio. Inter-frame coding is used to exploit the correlation among image sequences. Initially SPIHT is applied with fast block matching process, Diamond Search. To enhance the efficiency of compression ratio a new scheme Head Code Compression is introduced. Results are compared in terms of Compression Ratio and Peak Signal-to-Noise Ratio with other state of art coding. Experimental results of our proposed methodology achieves 25% more reduction than the other state-of-the-art algorithms.
Medical Science grows very fast and hence each hospital, various medical organizations need to store high volume of digital medical image sequences that includes Computed Tomography(CT), Magnetic Resonance Image(MRI), Ultrasound and Capsule Endoscope(CE) images. As a result hospitals and medical organizations have high volume of images with them and require huge disk space and transmission bandwidth to store this image sequences [1]. The solution to this problem could be the application of compression. Image compression techniques reduce the number of bits required to represent an image by taking advantage of coding, inter-pixel and psycho visual redundancies. Medical image compression is very important in the present world for efficient archiving and transmission of images. Image Compression can be classified as lossy and lossless. Medical imaging does not require lossy compression due to the loss of useful information and the original image is not recovered exactly. Hence efficient lossless compression methods are required for medical images. Lossless compression reproduces the exact replica of the original image without any quality loss [2]. Lossless compression includes Discrete Cosine Transform, Discrete Wavelet Transform, Fractal Compression, Vector Quantization and Linear Predictive Coding (LPC).
Nowadays Discrete Cosine Transform and Discrete Wavelet Transform (DWT) are important techniques for image compression. Discrete Cosine Transform has low processing power and there is loss of information. But Discrete Wavelet Transform gives better compression ratio and this is suitable for image compression [3]. In recent years wavelet based image coding algorithms are very popular because wavelet transform provides an efficient multi resolution representation of the signal. Wavelet transform is an optimal tool to represent the image [4]. Wavelet transform has gained extensive acceptance in signal and image compression. Wavelet can be used to reduce the image sequence without losing much of the resolution computed [5].
Several lossless image compression algorithms like Lossless JPEG, JPEG 2000, PNG, CALIC, JPEG-LS and Super- Spatial Structure Prediction were evaluated for compressing medical images. Among the various lossless image compression algorithms Set Partitioning in Hierarchical Trees (SPIHT) is a extensively used compression algorithm for wavelet transformed images. SPIHT has many advantages than other compression techniques. SPIHT makes compression more efficient and has good image quality with high Peak Signal-to-Noise Ratio (PSNR). SPIHT process represents a very valuable form of entropy-coding [6].
Most of the lossless image compression algorithms take only a single image independently without utilizing the correlation among the sequence of frames of MRI or CE images. Since there is too much correlation among the medical image sequences, The authors can achieve a higher compression ratio using inter-frame coding. The idea of compressing sequence of images was first adopted in [7] for lossless image compression and was used in [8] [9][10] for lossless video compression. The compression ratio was significantly low (i.e.) 2.5 which was not satisfactory. Hence in [1] they have combined JPEG-LS with inter-frame coding to find the correlation among image sequences and the obtained ratio was 4.8. Super- Spatial Structure Prediction algorithm proposed in [11] has outperformed JPEG-LS. The proposed scheme includes SPIHT with Motion Estimation and Motion Compensation (MEMC). The efficiency of SPIHT is enhanced using Head Code Compression (HCC). HCC scheme is used to compress code words [14]. This paper compares the compression ratio and PSNR with other state of art coding. The Compression Ratio (CR) can be calculated by the equation (1) and PSNR by equation (2)
| CR = Original Image Size / Compressed Image Size | (1) |
| PSNR = 20 * log10(255)sqrt(MSE) | (2) |
A universal characteristic of the medical image sequences is correlation. The aim of the proposed algorithm is to improve the compression ratio using SPIHT with MEMC and HCC. Figure 1 illustrates the encoder side of the proposed method.
Figure 1. Flow chart for the encoder side of the proposed method
Given an image sequence, the first image will be compressed by SPIHT coding since there is no reference frame. Now the second frame will be the current frame and the first frame becomes the reference for the second frame and the process continues. Then Motion Estimation and Motion Compensation (MEMC) are done for two images. Block matching algorithm helps to find Motion Vectors (MV) of each block. After MEMC is done the difference of images is processed for compression. This difference is also compressed using SPHIT compression. The motion vectors derived from motion estimation will also be compressed. Then the flag bits and the encoded bits for one image frame are concatenated into single bit stream. This processing will be repeated for the next image frame until the end of image sequence. HCC is applied to the SPIHT output code to enhance the compression ratio.
Motion estimation is the estimation of the displacement of image structures from one frame to another in a time sequence of 2D images. The displacement vector at location r in frame at time t, describe the motion from frame at t to frame at t+Δt, as
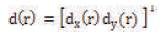
Where r=[x,y]T, the continuous spatial coordinates and superscript T denotes vector transposition. The dependency of the displacement vector on spatial coordinates for each location r at frame t, a displacement vector can be defined as in Figure 2.
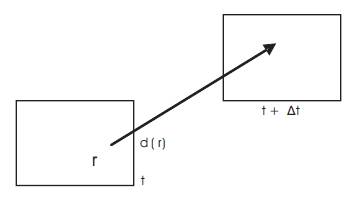
Figure 2. Structure of motion estimation
The steps in MEMC is stated as
Figure 3 illustrates the block diagram of motion compensated coding.
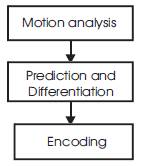
Figure 3. Block diagram of motion compensated coding
Motion estimation can be very computationally intensive and so this compression performance may be at the expense of high computational complexity. The motion estimation creates a model by modifying one or more reference frames to match the current frame as closely as possible. The current frame is motion compensated by subtracting the model from the frame to produce a motion-compensated residual frame. This is coded and transmitted, along with the information required for the decoder to recreate the model (typically a set of motion vectors). At the same time, the encoded residual is decoded and added to the model to reconstruct a decoded copy of the current frame (which may not be identical to the original frame because of coding losses). This reconstructed frame is stored to be used as reference frame for further predictions. The inter-frame coding should include MEMC process to remove temporal redundancy. Difference coding or conditional replenishment is a very simple inter-frame compression process during which each frame of a sequence is compared with its predecessor and only pixels that have changes are updated. Only a fraction of pixel values are transmitted. An inter-coded frame will finitely be divided into blocks known as macro blocks. After that, instead of directly encoding the raw pixel values for each block, as it would be done for an intra-frame, the encoder will try to find a similar block to the one it is encoding on a previously encoded frame, referred to as reference frame. This process is done by a block matching algorithm. [12]. If the encoder succeeds on its search, the block could be directly encoded by a vector known as motion vector, which points to the position of the matching block at the reference frame.
Motion estimation is using a reference frame in a video, dividing it in blocks and figuring out where the blocks have moved in the next frame using motion vectors pointing from the initial block location in the reference frame to the final block location in the next frame. For Minimum Value (MV) calculation they use Block matching algorithm as it is simple and effective. It uses Mean Square Error (MSE) for finding the best possible match for the reference frame block in the target frame. Motion vector is the key element in motion estimation process. It is used to represent a macro block in a picture based on the position of this macro block in another picture called the reference picture. In video editing, motion vectors are used to compress video by storing the changes to an image from one frame to next. When motion vector is applied to an image, they can synthesize the next image called motion compensation [7],[12]. This is used to compress video by storing the changes to an image from one frame to next frame. To improve the quality of the compressed medical image sequence, motion vector sharing is used. [10].
The block-matching process during the function MEMC taken from [1] takes much time hence they need a fast searching method and they have taken Diamond Search (DS) method [12] which is the best among methods both in accuracy and speed. This determines the displacement of a particular pixel 'p' at frame at time t, and a block of pixels centered at 'p' is considered. The frame at time t + Δt is searched for the best matching block of the same size. In the matching process, it is assumed that pixels belonging to the block are displaced with the same amount. Matching is performed by either maximizing the cross correlation function or minimizing an error criterion. The most commonly used error criteria are the Mean Square Error (MSE) as stated in equation (3) and the Minimum Absolute Difference (MAD) as stated in equation (4). The MSE is the cumulative squared error between the compressed and the original image whereas PSNR is a measure of the peak error.
.jpg)
.jpg)
The diamond search algorithm is based on MV distribution of real world video sequences. It employs two search patterns in which the first pattern, called large diamond search pattern (LDSP) comprises nine checking points and form a diamond shape. The second pattern consists of five checking points and make a small diamond pattern (SDSP). The search starts with the LDSP and is used repeatedly until the minimum Block Distortion Measure (BDM) point lies on the search centre. The search pattern is then switched to SDSP. The position yielding minimum error point is taken as the final MV.DS is an outstanding algorithm adopted by MPEG-4 verification model (VM) due to its superiority to other methods in the class of fixed search pattern algorithms.
SPHIT is a wavelet-based image compression coder. It has become the benchmark state-of-the-art algorithm for image compression. It converts the image into its wavelet transform and then transmits information to wavelet coefficients. SPIHT generates excellent image quality and performance due to numerous properties of the coding algorithm. The method deserves special attention because it provides the following:
Discrete Wavelet Transform (DWT) passes a signal to image through a pair of filters, a low pass filter and a high pass filter. The low pass filter yields low resolution signal and high pass filter yields difference signal. The outputs of these filters are down sampled and these have the same number of bits as the input signal. The down sampled outputs have the same number of bits as the input signal. When the up sampled output of the low pass filter is added to the up sampled high pass filter, the original signal is reproduced [13]. The decoder uses the received signal to reconstruct the wavelet and performs inverse transform to receive the image. The inverse transformation will yield a better quality reconstruction of the original image.
SPIHT incorporates two concepts-ordering the coefficients by magnitude and transmitting the most significant bits first. It consists of three passes Insignificant Pixel Pass (IPP), Insignificant Set Pass (ISP), Significant Pixel Pass (SPP) and three lists Lists of Significant Pixels (LSP), List of Insignificant Pixels (LIP) and List of Insignificant Sets (LIS). LSP is a list of significant pixels containing those pixels which are significant when compared with certain threshold. LIP is a list of insignificant pixels which stores those pixels which are insignificant when compared to certain threshold. LIS is list of insignificant sets having those sets whose each pixel is below some certain threshold. A pixel is significant if its value is greater than or equal to certain threshold [4][5].
The algorithm takes two stages for each level of the threshold the sorting pass and the refinement pass. SPIHT algorithm works with tree structure called Spatial Orientation Tree (SOT) which defines the spatial relationships among wavelet coefficients in different decomposition sub bands. Figure 4 shows how the SOT is defined in a pyramid constructed with recursive four sub bands splitting.
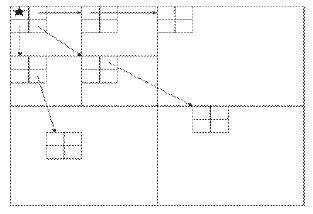
Figure 4. Parent-offspring dependencies in SOT
The authors also propose HCC scheme to further compress the code-words. The main concept is to utilize the nature of image sequence to perform compression. The first bit of each code-word is termed as the head code and the remaining bits are termed as tail codes that are identified to remove head codes. The head code is either 0 or 1, and this indicates that whether the current pixel is identical to the previous pixel. The code- word containing equal pixels has only the head code that is ready for compression. The first bit is a flag bit which contains all 0 or 1. The second will be 0 or 1 depending on the Best Run Length (BRL) codes which contains 0 or 1. Otherwise they get the original codes.
The decompression phase is simpler than the compression phase. The first frame is decompressed using HCC decoder followed by SPIHT decoder. Once the first frame is reproduced the difference image of the rest of the frames are decompressed.
The proposed methodology has been simulated in MATLAB (R2011b). To evaluate the performance of the proposed methodology they have tested it on a sequence of MRI images. Medical video is taken from Sundaram Medical Foundation (SMF). Input image sequences are taken from these videos. More than 100 image sequences are taken and tested for compression. Figure 5 shows ten MRI Image sequences. The images in these sequences are of dimension 514×514. Motion Estimation and Motion Compensation is applied to these image sequences using Diamond Search algorithm and SPIHT compression is applied. The output code of SPIHT is then taken and HCC is applied to increase the efficiency of compression ratio. Figure 6 shows the compressed image sequence.
Figure 5. MRI Image Sequences
Figure 6. Compressed Image Sequence
The results of this proposed methodology are compared with the existing methodology and are shown in Table 1. Table 1 shows the compression ratio for ten image sequences among the tested image sequences. The result of this algorithm is graphically compared and shown in Figure 7.
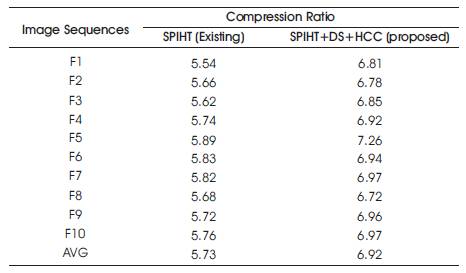
Table 1. Compression Ratio for MRI Image Sequences
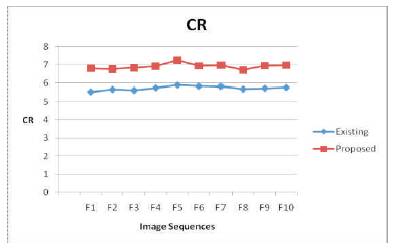
Figure 7. Compression Ratio of Existing Vs Proposed
From Table 1 and Figure 7 it is easily identified that the proposed methodology has a better compression ratio than the existing one. On the average the proposed has the compression ratio of 5.8 and existing has 4.39. Experimental results of the proposed methodology gives 25% more reduction than the prior arts.
Table 2 shows the PSNR values for MRI image sequences. The PSNR values are also compared with the existing system. Proposed methodology gives an average PSNR of 44.26 and existing gives an average of 37.42. From Table 2 and Figure 8 it is identified that the proposed yields better results.
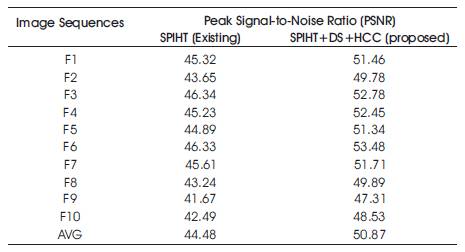
Table 2. PSNR for MRI Image Sequences
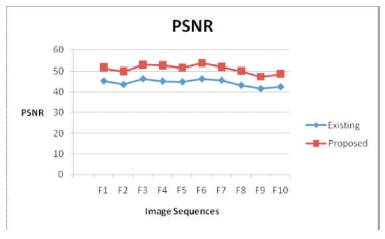
Figure 8. Peak Signal-to-Noise Ratio of Existing Vs Proposed
The SPIHT compression presented in this paper makes use of the lossless image compression which includes wavelet transform to achieve higher ratio. Fast block matching algorithm Diamond Search is used which is best in terms of accuracy and speed. This paper also exploits the interframe correlation in the form of motion estimation and motion compensation. To enhance the compression ratio HCC is combined with SPIHT. Results are compared in terms of CR and PSNR with other existing algorithms. From the results and discussion it is analyzed that the proposed methodology is much better than other existing algorithm.