
Figure 1. Architecture
In the present scenario Internet has become an integral part of every one’s life, as many services like mail, news, chat are available and huge amounts of information on almost any subject is available. However, in most cases the bandwidth to connect to the Internet is limited. It needs to be used efficiently and more importantly, productively. Generally, bandwidth is distributed among groups of users based on some policy constraints. However, it turns out that the users do not always use the entire allocated bandwidth at all times. Also, some times they need more bandwidth than the bandwidth allocated to them. But when it is abundant then any kind of use can be permitted provided it is in consonance with the policy. The bandwidth usage patterns of users vary with time of the day, time of the year hence to stabilize this, a dynamic allocation of bandwidth that satisfies the requirements of the users is needed.
To maximize productive usage, a need to implement control access policies has to be implemented which prevents unproductive use but at the same time does not, to the extent possible, impose censorship. Squid proxy server is a an example of the same. Squid provides many mechanisms to set access control policies. However, deciding which policies to implement requires experimentation and usage statistics that must be processed to obtain useful data. The proposed architecture elaborated in this paper is based on machine learning to determine policies depending on the content of current URLs being visited. The main component in this architecture is the Squid Traffic Analyzer, which classifies the traffic and generates URL lists. The concept of delay priority will also be introduced which gives more options to system administrators in setting policies for bandwidth management.
Squid proxy server is generally employed at the end of a local network and the starting point of an Internet link [4][5]. Typically the allowed bandwidth on Internet links is limited, ranging from kbps to Mbps. So there is a need for better utilization of this resource and for finding better policies. In the context of limited bandwidth an organization would like to use it for productive purposes like data of academic relevance in an academic institution. However, Internet usage ranges from research, news, entertainment, sports, general information to downloading movies, music and pornography [6]. So there is a need for traffic analysis to find the shape of the traffic in terms of content and help system administrators in setting policies for shaping the traffic. Traffic analysis can categorize URLs and IP Addresses into categories like academic, sports, music etc [7]. This categorization can be used to allocate bandwidth according to policies adopted by the organization. Squid has a set of mechanisms for implementing policies based on many configuration parameters like source, destination, domains, time, and regular expression on URLs etc. Squid allows HTTP tunneling to support SSL and TLS. But, these provide a loophole for overcoming policies.
Generally, users use mass-downloaders or some other tools, which use HTTP tunneling [6] [3] to over come access control policies. So there is a need to find a way for enforcing policy strictly. The aim of proposed architecture is to find out and implement environment and usage sensitive policies in Squid proxy server that leads to better utilization of bandwidth and other resources. In the proposed architecture machine-learning techniques has been adopted to study the current environment and usage patterns. System administrators can then use this information to decide and implement policy by making use of the existing tools available in Squid to control access.
The system design has been shown in Figure 1. From an abstract point of view the problem can be seen as improving the performance of a proxy server (Squid) in a given environment [15]. For the measure of performance two parameters has been used:
Figure 1. Architecture
This problem will be treated in two parts. To improve bandwidth utilization, the concept of priority in delay pools will be introduced and to control traffic based on the content, the problem will be formulated as a machine learning task and learn appropriate class for a URL from given set of classes [16,17]. The log data and cache documents of Squid Proxy have been used for training purposes in the learning task (classifying the documents) [13,14]. The learning itself is done by using a naive Bayes Classifier on the collected data. Once classification is done, policies based on these categories are used to tune the Squid proxy server. This process is continuous and can be applied till the performance is improved to required levels.
The complete classification of Squid traffic is done in three different phases: data collection, learning and classification as shown in Figure 2. In the data collection phase the log data and documents from Squid proxy, which characterize the traffic, is collected. The learning phase includes some user/manual interaction. It includes two steps namely data cleaning and learning.

Figure 2. Phases in Squid Traffic Classification
The log files of Squid and documents from the cache file system are collected as shown in Figure 2a. The collection of documents was done with an external process. A Squid proxy server has been configured and enabled as store.log access.log and cache.log. As the sizes of the log files are in the range of 250MB - 500 MB, the log each day has been rotated. Squid renames the old log files with integer extensions. The log files have been zipped to solve the problem of space on the system. When users access Internet pages/data, Squid caches it based on the caching strategy and lifetime of the pages/data. Squid stores such cached pages in the cachefs and writes a log entry in store.log. An external process ("Data Collector") has been designed which uses the store.log and cachefs to collect the documents. The store.log record gives information about the "location" of the pages/data in the cachefs. The external process, Data Collector copies the pages/data to the local directory or disk space. The schematic diagram of data collector is as shown in Figure 2a.

Figure 2a. Data Collector
The traffic through Squid proxy can be classified into different categories: news, sports, entertainment, music, science and technology, chat, movies, academic and pornography [Tanenbaum S. Computer Networks (2003)]. The traffic is characterized by the log data and documents collected through the external process - Data Collector [8]. The Naive Bayesian Classification algorithms have been used on these documents to classify them. The category of a document is identified using the content in the document or page. For example, if a document contains research/educational information it is considered to be in the academic category.
The Bayesian Classification Algorithm performs better than almost all other competing algorithms [1] [Tom & Mitchell (1997)] in document classification. The Naive Bayes classifier can be applied to learning tasks where each instance x is described by a conjunction of attribute values and where the target function f (x) can take on any value from some finite set V. A set of training examples of the target function is provided by the tuple of attribute values
Bayes theorem is the basis of Bayesian learning methods because it provides a way to calculate posterior probability P(h|D) from prior probability P(h), together with P(D) and P(D|h). Here P(h|D) is the probability h that holds the given training data D (similarly, P(D|h). P(h) is priori probability that h holds and P(D) is a priori probability that data D will hold. Bayes theorem gives a formula to calculate P(h|D) provided we know the other three probabilities.
Bayes theorem:
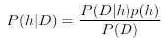
With the help of Bayes theorem VMAP can be rewritten as
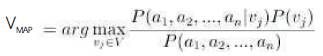
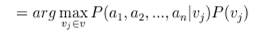
In the above equations, the two terms can be evaluated based on the training data. It is easy to estimate each of P (Vj) simply by counting the frequency with which each target value Vj occurs in the training data. However, estimating the different P (a1, a2, ..., an) terms in this fashion is not feasible unless a very large set of training data is available. The problem is that the number of possible instances times the number of possible target values. Therefore, there is a need to see every instance in the instance space many times in order to obtain reliable estimates. The Naive Bayes classifier makes one simplifying assumption: the attribute values are conditionally independent given the target value.
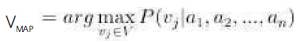
In other words, the assumption is, given the target value of the instance, the probability of observing the conjunction al, a2, ..., an is just the product of probabilities for individual attributes: P(a1, a2,, ..., an) = Пi P(ai|vj). Substituting this in the above equation, we get the following equation.
Naive Bayes classifier:
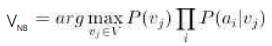
where VNB denotes the target value output by the Naive Bayes Classifier.
To summarize, the Naive Bayes learning method involves a learning step in which the various P(Vj) and P(ai|vj) are estimated, based on their frequencies over training data. The set of these estimates corresponds to the learned hypothesis. This hypothesis is then used to classify the new instance by applying the equation of Naive Bayes classifier.
As the documents collected are not directly amenable for learning, the documents need to be cleaned. Currently, only the documents with the following content types will be handled: text/html, text/plain, Application/*, etc. - essentially documents whose content has text in it. The structure of a typical document is as follows: meta data, HTTP Reply Headers, HTTP Reply Body. After that the plain text from the HTTP Reply Body will be extracted [9]. The information of interest is the URL and plain text. This plain text forms the content of our cleaned document[]. A cleaned document consists of the URL and the plain text extracted from HTTP Reply Body.
In a Bayes classifier the value of P (D|h) needs to be calculated. This means all the data used in learning must be pre-classified. Since the volume of training data is quite large, instead of classifying all documents manually, following technique has been used to come up with class labels for the training documents [1]. For each class or category, keywords for the URL and for the content will be identified as shown in Figure 3. The logic is if a keyword is present in the URL or if a subset of keywords is present in the document the category of the document is identified as the category associated with the keyword(s). Initial categorization is done using URL, document content and keywords. For verification purpose some classified documents have been randomly selected and verified manually.
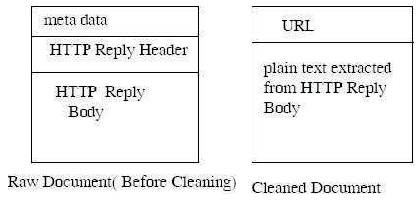
Figure 3. Document Structure
Algorithm for Initial Categorization:
The next phase in Squid traffic analysis is classification [12]. This is accomplished by the simple Naive Bayes classifier [1]. The Naive Bayes classifier performs well on many document classification problems and produces good results. The cleaned documents along with their category are taken as training data for the Naive Bayes classifier. For classifying others (documents not in the training set), this Bayes classifier is used to get the most likely category for the document. The words in a document are treated as attributes for that document.
The delay pools concept, which is a bandwidth management scheme, has some drawbacks. The major one is that the unused bandwidth of a Delay pool is wasted and cannot be utilized by other Delay pools. Dynamic Delaypools [18] solve this problem and allow utilization full bandwidth [19]. The dynamic delay pools implementation is speedy and simple. The algorithm for bandwidth adjustment works in two stages.
The algorithm uses the aggregate number of tokens in the delay pool as the criterion for whether the user's link bandwidth is fully utilized or it skips the networks settings entirely [11]. If number of tokens exceeds a cutoff value (presently 10% the aggregate delay pool size), indicating that there is some capacity being under-utilized, each individual user's bandwidth allocation is increased by a fraction. If the number of tokens is less than the cutoff value, indicating that the requests are backing up and link bandwidth is fully utilized, an individual user's bandwidth allocation is reduced by a fraction.
Using single delay pool allows bandwidth to be shared fairly among users. However, in many instances, the bandwidth needs to be distributed unequally among different classes of users [20]. This can be easily achieved by having several delay pools with different parameters. However, when several delay pools operate on the same server, some pools do not use all their allocated bandwidth while others are saturated, so the bandwidth. which is not being utilized is allowed to be transferred to another delay pool as depicted in Figure 4.
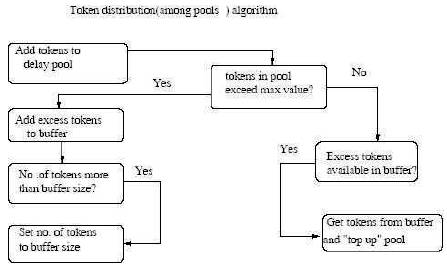
Figure 4. Transferring Bandwidth among Pools
The above algorithm checks the level of tokens in each delay pool after adding the token allocation available to that particular pool. If level of tokens is greater than the maximum allowed value, then excess tokens are transferred to a buffer and if a delay pool is encountered whose tokens are less than maximum permissible value, the tokens in the buffer are used to "top up" the pool to its maximum value or until the tokens in the buffer are exhausted. Accordingly, excess tokens that would be utilized by lightly loaded delay pools are distributed among the pools that are using their token allocation fully. The maximum size of the buffer is set to a few seconds worth of tokens.
A simple modification to the above dynamic delaypools has been proposed and introduces the concept of priority among the delay pools. As the unused bandwidth of delay pools is distributed among other delay pools, the priority imposes an order on the distribution of unused bandwidth among the other delay pools. The delay pool with highest priority gets the unused bandwidth before the lesser priority delay pools.The usage of such a priority is illustrated with a simple example. Suppose we have defined delay pools which accept different types of traffic based on the category say C1, C2,...,Cn. If we want the delay pool associated with C4 to get maximum bandwidth, then the priority setting of C4 to a high value can solve the problem.
The classification of traffic results in categories and a set of documents that belong to that category. As documents are related to the URLs, one can directly link the URLs with the categories.
(category, Set of Documents)→ (category, set of URLs), as each Doc(i) is related to URL(I).
The set of URLs along with the category forms the basis for formation of policies. An administrator can regulate traffic by suitably changing the policies. In Educational Institutions, administrators want most bandwidth should be used for academic purposes rather than movies, music other unrelated stuff. So this category names, URL lists help in forming the policies [21].
The traffic analysis helps in formulating bandwidth policies. The steps for creating policies based on URL lists of category is as mentioned below-
The traffic analysis results also help in tuning the Squid to cache hot pages and deny caching of unwanted traffic. The ACL Lists like no_cache can be used along with the named ACL elements defined above to tune the caching. For categories like news and academic the pages should be always cached and the pages of porn content should be denied [10].
The selection of performance generally depends on the problem, its understanding, and variables to be optimized. Here the aim was to improve the percentage of bandwidth for certain classes and reduce the bandwidth available to other classes. More formally (category, bandwidth usage) tuples form the measure. However, it should be noted that this case breaks down into two independent measures since categorization of URLs is handled by the Naive Bayes classifier and bandwidth utilization is managed independently by priority based dynamic delay pools [21,22]. So, first the traffic has been classified, and then formulates policies based on the classification results and finally set these policies in the Squid proxy. Performance is measured independently for classification and for bandwidth management.
Certain keywords has been taken for each category to identify the category of the document in initial categorization. Some of these keywords are as mentioned below-News: news, vaartha, timesofindia, cnn, eenadu, hindu ; Sports: sport, cricket, football, tennis, chess, athletic; Entertainment: greetings, dance, hero , celebrity, marriage, jokes; Music: music, song, audio, mp3, ram; Science & technology: Science, technology, breakthrough. For this category, manually some documents have been collected and added to this category for learning; Chat: chat, msg, messenger, notify, pager; Movie: movie, video, dat, asf, asx, mplayer, realplayer; Academic: research, .pdf, .ps, .gz,.bz, download, package, edu, university, exam , academic; Pornography: nude, porn, sex, adult, xxx, lesbian, blowjob, fuck, naked.The classification of traffic results in URL lists for each category. A simple method is to use the http _ access, url_regex_path to design policy. ac1 url_path_regex porn_url porn_url_lists # porn_ul_lists contains the URLs found in the classification. http_access deny par _url. # deny traffic for this category. These rules provide simple policies to deny some kinds of porn content through the proxy. But one should find more reasonable access controls.The keywords with maximum frequency in the URL lists has been found out and form another ACL element to complement the above.
The policies have been set based on the URL lists for categories. The log files and documents have been collected after setting the policies. Some of results in terms of performance measure for a day by taking average of a period of 7 days in as mentioned below shown in Table 1 and 2.
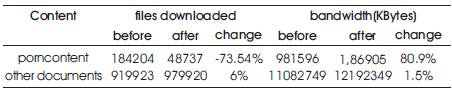
Table 1. Performance Measure (Two Categories)

Table 2. Performance measure (Documents)
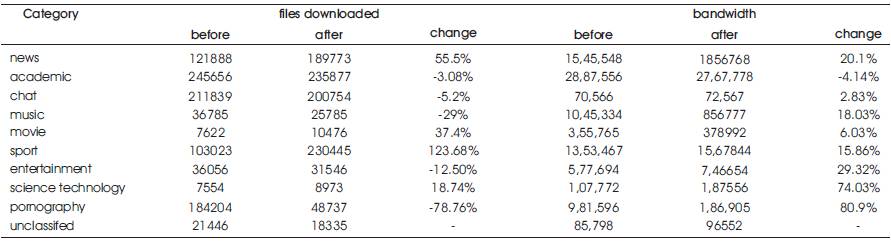
Table 3. Bandwidth Distribution (All categories)
The policies have been set to deny pornographic content using keywords and list of URLs. The bandwidth usage and number of files downloaded that belong to this category before and after setting the policies is compared Using.
The statistics (average values per day) for a period of a week, before and after setting policies. Downloading a page like www.google.com results in sending several requests for text, for all images in that page, banners etc. A file download corresponds to a single file, so for google it will result in multiple downloads. The URL entries in the access.log have been classified as follows:
Thirty thousand documents have been collected for a period of a day before and after setting policies. The Naive Bayesian classifier has been applied on these documents. The characteristic of the documents is that the content of the file is understandable like text/html or text/plain & the size of the document is at least 8Kbytes(before cleaning). So the bandwidth here will not signify much, as the images, song files like .mp3, .rm files etc. has not been considered.
Here the data collected from the access.log file has been classified into all nine categories. The high change in sports category is due to frequent visits to cricket and tennis. The cache hit rate for sport category is high.
Initially 30,000 cleaned documents have been collected. 5000 documents have been trained using initial categorization [22]. For each category we used around 200 - 400 documents in training. For pornography, chat and academic categories we used around 800 -1000 documents for training. Then 25000 documents have been classified using the Bayes classifier and found the frequency of URL along with documents [23]. A different document of the same URL which belongs to the same category of trained data has also been added. By this way, exactly 1000 training documents are obtained for each category. 20,000 more documents are collected and classified using the Naive Bayesian classifier. The accuracy of classification for the categories is as follows: The verification of results is done with the keywords manually. When the number of domains are less, the verification is performed manually. For the category like academic, the presence of the keyword .edu is good enough.
For other categories the accuracy as follows:
The HTTP Tunneling Policies results are in the form of entries in access.log and not in terms of percentages since it is not possible to measure such percentages.
Through this paper an approach has been presented for better management of access and bandwidth to an internet link through a proxy server. Access control is done by categorizing URLs into different static categories using a Naive Bayes classifier. Bandwidth control is done using priority based dynamic delay pools. Some methods to inhibit HTTP tunneling have also been tested. The initial results are encouraging. For example pornographic content reduced significantly and the bandwidth was well utilized for other categories. Policies using priority based dynamic delay were implemented and bandwidth utilization is improved. Log traces show that the methods to inhibit HTTP tunnelling, also manage to stop tunneling requests.