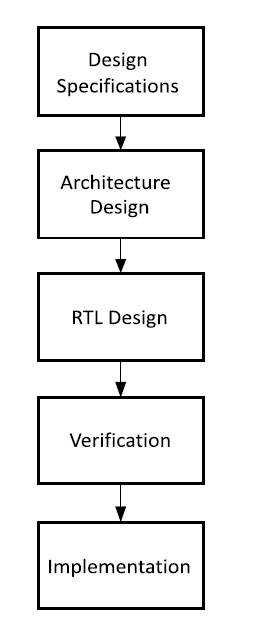
Figure 1. Flowchart of the Proposed Work
In this paper, a new architecture has been proposed for multiplier and Accumulator to increase the arithmetic operation. Multiplication and Accumulation will help in improving the performance of multiplier. The Radix-2 modified booth algorithm is used for the reduction of partial products. The parallel multiplier such as radix 2 modified booth algorithm is used to improve the computations and this can be achieved using fewer adder and steps. By using Radix-2 modified booth multiplier algorithm, high speed of operation can be achieved.
The basic operations performed in digital signal processing is the multiplication accumulation operation, which is used to compute the product of two numbers and then add that product to an accumulator. The hardware unit that performs the operation is known as a Multiplier- Accumulator (MAC or MAC unit). The operation itself is also often called a MAC or a MAC operation [7]. The MAC operation modifies an accumulator as,
An advancement in communication systems, multimedia and real-time signal processing, such as video processing, signal processing and capturing of large data occur in recent times. The multiplier and Multiplier and Accumulator elements play a very important role, such as filtering, convolution, etc., in digital signal processing [3]. The digital signal processing modules are having a huge application, whereas in wireless sensor network, number of battery operated sensors are used to sense the data. The multiplier unit is used mostly in the circuits to perform these types of operation. The multiplier in digital signal processing plays a very important role. The operation like addition, subtraction, etc., in digital signal processing is based on two elements, such as delay element and the multiplier [16]. A repetition of addition operation leads to multiplication. Basically two operands are required to perform multiplication, such as multiplier and multiplicand. Each addition step generates a partial product. The multiplier is split into two sections. The first section is used to produce partial products and the second section will collect the data and by adding it produces the final result [12]. The booth multiplier algorithm is used to improve the speed of multiplier by encoding the number which is to be multiplied. In conventional multiplier, the number of partial products is obtained [1]. The multiplier is added with the multiplicand to obtain this partial product for long division multiplication technique [10]. Previously, due to the use of accumulator in the chip design, the chip becomes more complicated. Since the accumulator has a number of delay elements, large data processing requires more time to obtain the product. To reduce the partial product of the multiplication operation, booth multiplier algorithm obtains a better result. This algorithm also improves the speed of binary multiplication operation. As the radix increased, the partial product produced will become more complicated [4].
In this paper, the authors propose a method to design a multiplier by using Radix-2 Modified Booth Algorithm.
An algorithm was proposed to perform arithmetic operation in high speed. This is a hybrid architecture formed by the combination of multiplication and accumulation obtaining a Carry Save Adder (CSA), to improve the performance of the system [8]. An accumulator has a large delay in multiplier and the accumulator are joined with Carrying Save Adder (CSA), so that the overall performance can be easily evaluated. The modified array structure is used to improve the density of the operands for the sign bits [11]. The propagation delay is another issue of the parallel adder. As the number of bits increase, the propagation delay also increase. So in order, to reduce this delay a look ahead carry is inserted in the Carry Save Adder (CSA) tree, which will reduce the number of bit requirements [6]. A new algorithm MAC architecture was proposed to obtain multiplication accumulation operation, which is used to perform the basic operation of digital signal processing [15]. In this paper, the accumulation is removed so that the problem of delay can be reduced. Instead of using accumulation, the compression process is used along with partial products. By this process, the speed of operation can be improved [13]. In this proposed work, the multiplication operation can be done on both signed and unsigned number. This multiplier is known as AMBE multiplier which is used to multiply 32*32 bit[9]. A new algorithm is proposed for improving speed, power consumption, etc., where a number of fast adders are used so that better result can be obtained [9]. The flow chart of the proposed work is shown in Figure 1.
Figure 1. Flowchart of the Proposed Work
The architecture block diagram of the proposed work to design an adder is shown in Figure 2.
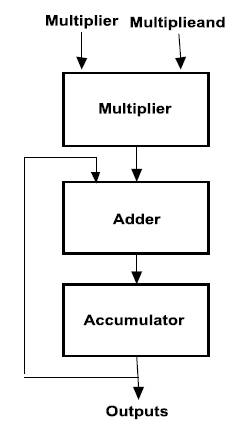
Figure 2. Block Diagram
The multiplier is an important operand of the multiplication operation, which is utilized in low power consumption, high speed of operation, where a large amount of information is required to process. The modified booth multiplier algorithm reduced 50% of the number of partial products [5].
In this multiplier, two signed binary number is multiplied, but in 2's complement notation. Booth multiplier algorithm also reduces the number of partial products which are obtained by addition of multiplier and multiplicand to the obtained final products. Booth encoding reduces the number of partial products to 50%. The functional operation of Radix-4 based booth multiplier algorithm encoder is shown in Table 1 [2, 14]. The radix-4 multiplier consists of eight different states, which will help in obtaining the results, i.e. the multiplication of multiplicand with 0, -1, and -2, respectively.
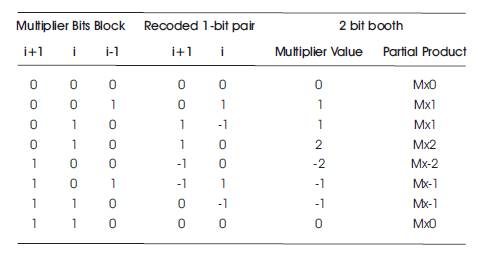
Table 1. Truth Table
The partial products are obtained due to parallel multiplication which is done by using booth multiplier algorithm, is based on the group of 0's and 1's. This algorithm obtains efficient partial products which carry large numbers of bits than input bits. The width of this partial product is based on the radix scheme. Since the partial product is reduced on the multiplication by using booth multiplier and due to less partial products, the power requirements get reduced. Basically, two algorithms are used for this booth multiplier, i.e. Radix-2 and Radix-4 to generate efficient partial products.
• The sign bit is extended to 1 position to obtain n as an even number. The zero is appended to the right of the LSB bit of the multiplier. As per the value of each of the vectors, the Partial Product will be 0, +y, –y, +2y, or –2y.
To obtain negative values of y, the number is complemented by 2's complement.
The multiplication process between multiplier and multiplicand is done by shifting y by one bit to the left since only half of the partial products are obtained by using booth multiplier. Table 1 is a booth recoding table for radix-4.
The design of this adder consists of the three ripple carries adder and five multipliers. The ripple carry is used to pass the carry from one stage to the other stage. The most of the delay problem is associated with this ripple circuit which is known as Propagation delay. This carry is passed by using a multiplexer. A multiplexer is a device which contains a number of inputs to obtain a single output. In this paper, the authors use 2x1 multiplexer.
The accumulator is a special purpose register used in the Central Processing Unit (CPU) to perform a specific task. This register is a default register which is used to store the result temporarily. The operations, include addition, subtraction, multiplication, etc.
Multiplier and Accumulator are mostly used in the digital signal processing applications.
It performs various operation, such as filtering, convolution, etc., in digital signal processing.
In this paper, a new MAC architecture is proposed so that the multiplication- accumulation operation can be executed, which is the basic operation for digital signal processing, audio, and video signal processing efficiently. An accumulation process which contains a large number of delay can be combined with compression process of the partial products. Due to this process, an overall MAC performance can be improved.
It can be used in digital filters. A huge amount of data that needs to be transferred, quickly affects the throughput in DSP applications. A number of bits considered may be increased in the encoding scheme• Power can be reduced by improving the partial product compression ratio.
Expression of giving thanks are just a part of those feelings which are too large for words but shall remain as memories of wonderful people with whom I have got the pleasure of working during the completion of this work. I am grateful to Shri Shankaracharya Institute of Professional Management and Technology, Raipur which helped me to complete my work by giving encouraging environment. I would like to express my deep and sincere gratitude to my supervisor, Assistant Professor Upendra Soni. His/her wide knowledge and his logical way of thinking have been of great value to me. His/her understanding, encouraging and personal guidance have provided a good basis for the present work.