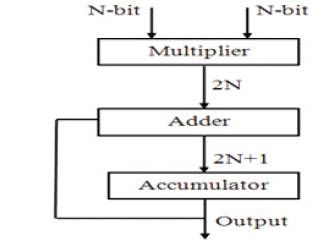
Figure 1. Basic MAC unit
The Multiplier-and-Accumulator (MAC) unit is the basic element of the digital signal processing(DSP) applications such as filtering, convolution, transformations and Inner products. So the MAC should provide high speed multiplication and multiplication with accumulative addition. The most effective way to increase the speed of a multiplier is to reduce the number of the partial products. The objective of the paper is to reduce the power consumption using Modified Booth Algorithm and Spurious Power Suppression Technique. And also to increase the speed of operation by decreasing the number of MAC stages. By using radix-4 Modified Booth Algorithm, partial products are reduced by half and then by using Spurious Power Suppression Technique power has been reduced. In this architecture, multiplication and accumulation have been combined with a hybrid type of Carry Save Adder (CSA). In booth multiplication, when two numbers are multiplied, some portion of the data may be zero. By neglecting those data, power has been reduced. For this purpose, Spurious Power Suppression Technique (SPST) is used to remove ineffective portion of the data in addition process. The modified MAC operation is coded with Verilog and simulated using Xilinx ISE 12.1.
Demand of high speed signal prosessing is mainly focused by researchers. Digital Signal Processing (DSP) applications like Fast Fourier Transform (FFT), Finite Impulse Response (FIR) filters, convolution etc… need high speed and low power MAC. The multiplier and Multiplier and Accumulator (MAC) [1] are the important blocks of the processor and have a great impact on the speed of the processor.
Parallel MAC is used in digital signal processing and video/graphics applications. Fast multipliers should be essential parts of digital signal processing systems. The speed of multiply operation is important in digital signal processing as well as in the general purpose processors today, especially since the media processing took off. The MAC provides high speed multiplication and multiplication with accumulative addition.
An efficient multiplier should have the following characteristics [2]: Accuracy- A good multiplier should give correct result, Speed-Multiplier should perform operation at high speed. Area-multiplier should occupy less number of slices and LUT's, Power-Multiplier should consume less power. Basically Multiplier consists of three basic steps: Booth Encoding, Partial product generation and final addition. For MAC additionally accumulator is used [3] .
Modified Booth Algorithm (MBA) [4] is the method commonly used for achieving high speed multiplication and also reduce the number of partial products.Also by using radix-4, radix-8, radix-16 and radix-32 booth Encoding technique, the partial products are further reduced, which increases complexity and improves the performance [1]. By using MBA algorithm, speed has been increased. For this purpose, many parallel multiplications have been analyzed. [2]-[4].
The inputs for the MAC are fetched from memory location and fed into multiplier block of the MAC, which will perform multiplication and give the result to adder which will accumulate the result and then will store the result into a memory location [3], [6]. Then Spurious Power Suppression Technique has been used to achieve less power consumption. Whenever two numbers are multiplied, some of the rows will be zero. By neglecting those datas, power has been reduced.
The basic operation performed in digital signal processing is multiplication and accumulation shown in Figure 1. The MAC unit provides the operations such as high speed multiplication, multiplication with cumulative addition and subtraction [5], [11].
Figure 1. Basic MAC unit
While MAC is working under high speed operation, it can be able to support multiple operations. MAC comprises of three important sections: 1.Adder, 2.Multiplier, 3.Accumulator [4], [10].
Basic arithmetic steps of multiplication and accumulation have been given in Figure 2. In this, operation is performed as multiplication of two N–bit numbers and it accumulates into a 2N-bit number. Here the critical path is determined by the 2N-bit accumulation operation. Since accumulation is carried out using the result from step 2 instead of that from step 3, step 3 does not have to be run until the point at which the result for the final accumulation is needed [8], [9].
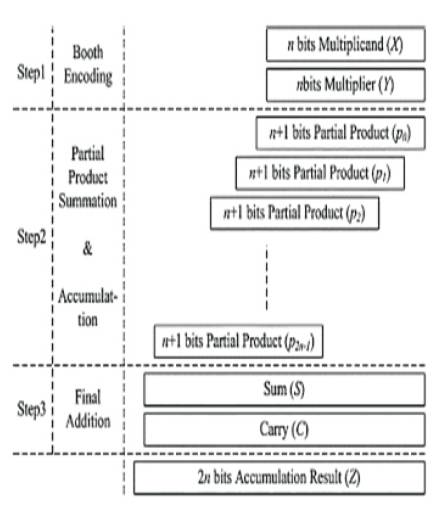
Figure 2. Basic arithmetic steps of multiplication and accumulation (3 stages)
In this modified architecture, Radix-4 Modified Booth Encoding (MBE) method is used to produce the partial products. In booth multiplication, when two numbers are multiplied some rows of the data may be zero [5]. By eliminating those data, power has been reduced. For this purpose, Spurious Power Suppression Technique (SPST) is used to remove ineffective portion of the data in addition process. In this modified architecture, the accumulation is comprised with partial product summation as shown in Figure 3, so that number of stages will get reduced. Multiplier (N bits) and multiplicand (N bits) will be given to the Radix-4 Modified Booth Encoder.
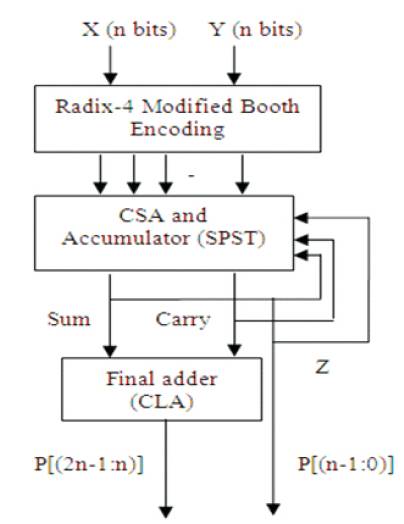
Figure 3. Block diagram of Proposed MAC
The multiplication of multiplier and multiplicand has been done by the following steps. Radix-4 booth algorithm starts by grouping of bits [7].Grouping has been done by three bit each from multiplicand. Then it will be encoded with the terms of (-2,-1, 0, 1, 2) as shown in Table 1.(i.e). Then these three bits will be converted into single bit. Here 4 rows of partial products will be generated. By using Spurious Power Suppression Technique (SPST) power has been reduced. Whenever the number of input bits applied to the final adder is low, the performance will be increased.
Steps:
In order to reduce this number of input bits, the multiple partial products are compressed into a sum and a carry by CSA. A 2-bit CLA is used to add the lower bits in the CSA. In addition, to increase the output rate when pipelining method is applied, the sums and carries from the CSA are accumulated instead of the outputs from the final adder in the manner that the sum and carry from the CSA in the previous cycle are input into CSA.
Booth multiplication is a technique that allows for smaller, faster multiplication circuits, by recoding the numbers that are multiplied. It is possible to reduce the number of partial products by half, by using the technique of radix-4 Booth recoding. The basic procedure is that, multipliying multiplier term by 1 or 0. To multiply multiplier and multiplicand, Radix-4 booth algorithm is used.
It follows the grouping of three bits. It starts from grouping of multiplicand by three bits and encoding them into one of (-2,-2, 0, 1, 2) as shown in Figure 4. Then these three bits will be converted into single bit. Here n/2 rows of partial products will be generated instead of n.
Radix-4 Booth Recoding has been illustrated in Table 1.
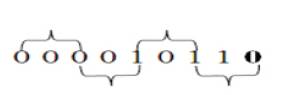
Figure 4. Grouping of bits from the multiplier term
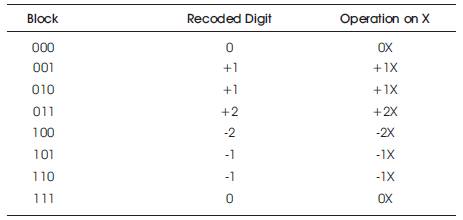
Table 1. Radix-4 Booth Recoding
The SPST technique basically depends on the Radix 4 Modified Booth Algorithm which is shown in Figure 5. It will reduce the number of intermediate stages in the multiplication operation. The SPST uses a detection logic circuit to detect the effective data range e.g., adders or multipliers. When a portion of data does not affect the final results of any architecture, the data controlling circuits of the SPST latch this portion to avoid ineffective data transitions occurring inside the arithmetic operations.
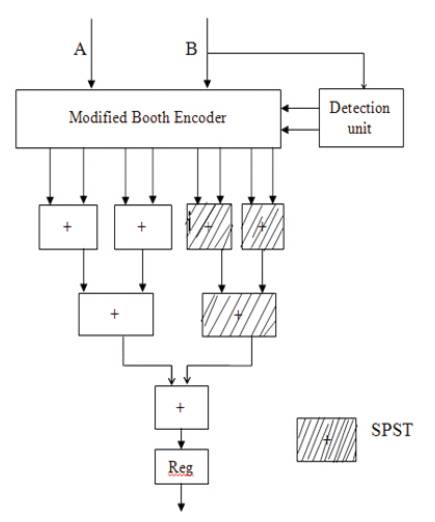
Figure 5. Spurious power suppression technique
Hybrid type of CSA architecture works with the help of proposed MAC as shown in Figure 6. It performs 8*8 operation (i.e) 8 bit operation. In this architecture, Ni is used to compensate 1's complement number. Then Si is used to simplify the sign extension. From Booth encoder, partial products are generated. Partial products are P0 [7:0], P1 [7:0], P2 [7:0], P3 [7:0].Only four rows of partial products are generated instead of eight rows. By using this architecture, five FA adder rows are needed. One more row is for accumulation process [11].

Figure 6. CSA and Accumulator architecture
For any N*N bit operation, the total number of CSA is (n/2+1) levels. In Figure 6, for Full Adder operation, White Square box is used, the gray square box is used for Half Adder operation and rectangular symbol is used for 2 bit carry Look ahead Adder operation. This CLA contains five inputs with carry input.
This stage is also crucial for any MAC because the stage addition of large size operands is performed. So in the modified stage, fast carry propagate adders like Carry-look Ahead adder or Carry Skip Adder or Carry Select Adder and other adders such as Carry Save Adder can be used as per requirement. But analyzing all the adders, Carry Look Ahead adder gives low power and speed of operation. Also it provides least area-delay product [10]. This adder is based on the principle of looking at the lower order bits of the augends and addend if a higher order carry is generated.
Figure 7 shows the output of 8 bit Multiplier and Accumulator using Radix-4 Modified Booth Algorithm simulated using Xilinx 12.1.

Figure 7. 8 bit Multiplier and Accumulator using Radix-4 Modied Booth Algorithm
High speed and low power multiplier adopting the SPST design has been successfully simulated using Xilinx 12.1 ISE design suite. By using Radix-4 Modified Booth Algorithm, the number of partial products has been reduced by half , which improves the speed of operation. By removing independent accumulation process that has the largest delay and merging it to the compression process of the partial products, the overall MAC performance has been improved. By using Hybrid Carry Save Adder, partial product summation has been combined with accumulation. So it reduces the number of stages as three instead of four. Also by using Spurious Power Suppression Technique, power has been reduced by eliminating ineffective portion of data.