Figure 1. Emergence of Cloud Computing
High-Performance Computing (HPC) has evolved into a tool that is essential to every researcher's work. The vast majority of issues that arise in contemporary research may be simulated, explained, or put to the test through the use of computer simulations. Researchers often struggle with computational issues while concentrating on the issues that arise from the study. Because the majority of researchers have a minimal or nonexistent understanding of low-level computer science, it tends to view computer programs as extensions of the thoughts and bodies rather than as fully independent systems. As a result of the fact that computers do not function in the same manner as people do, the typical outcome is lowperformance computing in situations where high-performance computing would be expected.
The delivery of computing services is shifting to mimic that of other utilities like water, electricity, gas, and telephones, creating a model in which computing is just another commodity. In this paradigm, customers gain access to services according to their needs rather than the location of the hosting infrastructure. This utility computing vision has been a goal of several computing paradigms, such as grid computing. The next paradigm shift, cloud computing, holds the greatest potential to finally make the concept of computing utilities a reality. One of the founding scientists of the Advanced Research Projects Agency Network (ARPANET), the forerunner of the Internet, Leonard Kleinrock, predicted in 1969 that computer utilities, similar to today's electric and telephone utilities, would spread across the country as computer networks matured.
In the twenty-first century, the entire computing industry is expected to undergo a radical transformation, and this vision of computing utilities based on a serviceprovisioning model predicted that these services would be readily available on demand, much like water, electricity, telephone, and gas are today. In a similar way, customers only need to pay service providers when they really use the computer resources. Furthermore, customers no longer have to make costly investments or struggle with constructing and maintaining sophisticated Information Technology (IT) infrastructure. Service consumers under such a paradigm would get access to the services they need, regardless of the physical location of the service providers. Historically, this approach has been known as utility computing, but more recently (after 2007), it has been referred to as cloud computing. The latter phrase often refers to the underlying infrastructure in the form of the cloud, through which consumers and companies may access apps on demand from any location on the globe. Thus, cloud computing may be defined as a new paradigm for the on-demand delivery of computer services hosted in highly sophisticated data centers that make use of virtualization technologies to maximize efficiency and resource usage. In the cloud, resources such as servers and software can be rented on a pay-as-you-go basis. Large companies' Chief Information Officers (CIOs) perceive an opportunity to scale their infrastructure on demand and tailor it to their operations' specific requirements.
Users that take advantage of cloud computing services may get to their files at any time, from any place, and via any Internet-connected device. There are many different perspectives on cloud computing, which may be summed up as follows,
For all intents and purposes, a computer program with High-Performance Computing (HPC) can complete a task more quickly than a person can. However, this is erroneous since computers and humans' approach problem-solving in fundamentally different ways (Buyya, 1999). Studying, developing, and creating a multi-task nature instrument may be difficult due to people's tendency to be "mono-task" focused, especially when considering the approach paradigm. This paper draws heavily from the work done at the Indian Standard Time (IST) Gravity Group's Baltasar Sete S'ois Computer Cluster and the related experiences and use cases done there. Professor Vitor Cardoso has been given a "DyBHo" Employee Retention Credit (ERC) Starting Grant to investigate and better comprehend dynamical black holes, and Baltasar is a member of this effort. Baltasar is an implementation of Cactus that was made to assist in the resolution of a particular issue. The targeted infrastructure included 4GB of Random-Access Memory (RAM) per core, 200 cores or more, and 500MB/s of network storage speed. It was intended for a particular use case, but it performed so well that the team is now considering it a general-purpose cluster. This examination begins with a discussion of the fundamental computer concepts necessary for grasping the parallel processing paradigms. It also outlines a few of the key resources needed for an effective HPC process. Finally, it makes an effort to simplify using a shared computer cluster by providing illustrative instances.
Cloud computing is the practice of virtually providing hardware, runtime environments, and resources to users in exchange for monetary compensation. There is no necessity for an up-front commitment when it comes to using these things for as long as the user desires. In order to deploy devices without incurring maintenance costs, the entire collection of computer hardware is converted into a set of utilities that can be delivered and put together in a matter of hours rather than days all at once. The long-term goal of a cloud computing system is to have information technology services exchanged on an open market like utilities without the involvement of technological or other regulatory restrictions.
A worldwide digital market that provides services for cloud computing will make it feasible to automate the processes of discovery and integration with the software systems that are already in existence. A digital cloud trading platform is already accessible, which will allow service providers to not only increase their income but also their profits. A cloud service could also be the customer service that a rival offers in order to fulfill its consumer promises.
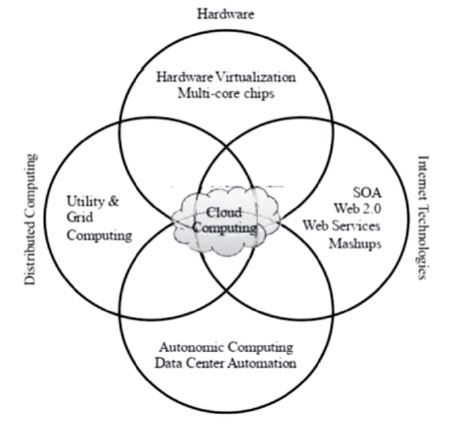
Both company and personal data are readily available in a variety of organized formats across the board, which enables access and interaction on an ever-expanding scale. The security and reliability of cloud computing will continue to advance, making it increasingly safer via the implementation of a broad variety of new strategies. The cloud is the most significant technology since its primary focus should be on the kind of services and applications it supports. When wearable technology, the "bring your own device" (BYOD) movement, cloud computing, and the Internet of Things (IoT) all come together, cloud computing will no longer be seen as an enabler in both personal and professional life (Buyya et al., 2009). Figure 1 shows the emergence of cloud computing as a result of the convergence of several innovations.
Figure 1. Emergence of Cloud Computing
"Cloud computing" is a relatively new catchphrase in the information technology industry. Its inception followed several decades of technological advancements in areas such as virtualization, utility computing, distributed computing, networking, and software services. The cloud is an information technology system that was developed to remotely deliver measurable and scalable resources. It has developed into a contemporary paradigm for the sharing of information and the provision of internet services. Customers benefit from services that are more secure, versatile, and scalable as a result of this. It is utilized as a service-oriented architecture that lessens the amount of information that is burdensome for end users.
Data storage necessitates cloud computing in most businesses. Businesses are responsible for the generation and storage of a massive amount of data. As a result, it faces many security concerns. Establishments would be included as companies in order to simplify, improve, and optimize the process, as well as to enhance cloud computing administration. The risk and difficulties associated with cloud computing are,
It is essential that the cloud data repository maintains both privacy and safety. Customers are extremely reliant on the cloud service provider. In other words, the cloud provider is obligated to implement essential safety precautions to protect the data of its customers. Customers are also liable for the security of the company's assets since it is required to have a strong password, refrain from disclosing the password to anyone else, and change it on a regular basis. If the data are located outside of the firewall, then a number of potential issues may arise, all of which may be resolved by the cloud provider. Because it might harm a large number of clients, hacking and malware count as one of the most significant challenges. It is possible for there to be a loss of data, as well as disruption to the encrypted file system and a number of other concerns.
The customer will receive cloud migration services both into and out of the cloud. Because it might be difficult for the clients, there should be no bond time allowed. The cloud will have the ability to provide facilities for onpremises use. One of the challenges presented by the cloud is remote access, which eliminates the possibility of the cloud provider accessing the cloud from any location.
Customers of cloud services face a challenge in achieving reliability and flexibility, which can prevent data sent to the cloud service from being leaked and provide the consumer with trustworthiness. Monitoring services provided by third parties and keeping an eye on the performance, resiliency, and dependability of businesses are necessary steps in overcoming this obstacle.
The most common problem with cloud computing is known as downtime, which occurs because no cloud provider can guarantee a platform which is always available. Connection to the internet is another factor that plays a significant role since it may be problematic for a business to have an unreliable internet connection, which can result in downtime for the business.
The cloud sector aims to hire experienced staff to address a shortage of resources and skills. This employee will not only assist in finding solutions to the problems that the firm is facing, but it will also provide training to other employees so that the organization can profit. At the moment, a large number of IT professionals are working to improve cloud computing capabilities; however, this presents a challenge for the Chief Executive Officer (CEO) because the employees have limited qualifications. It suggests that organizations gain more from employees with experience in the latest technology and innovations.
According to the findings of a survey compiled by RightScale, over 84 percent of businesses utilize a multicloud strategy, and 58 percent of those businesses utilize hybrid cloud strategies that include both public and private cloud components. In addition, companies take advantage of five distinct public and private cloud computing environments. When it comes in making longterm projections regarding the development of cloud computing technologies, the IT infrastructure teams have a harder time than usual. Experts have also proposed various techniques for addressing this issue, such as redesigning procedures, educating staff, utilizing the appropriate technologies, actively managing vendor relationships, and doing research.
Fog computing is an expansion of cloud computing, but it is more like a technology that works with the Internet of Things data. Fog computing acts as a mediator between the cloud and end devices (Yi et al., 2015). This is achieved by moving storage and networking resources, as well as computation, closer to the end devices. As a result of the localization of the fog nodes, it offers reduced latency and improved location awareness. Cloud computing offers a dynamically virtualized interface for the provision of services like storage, computing, and networking between client computers and the usual data centers. The list of qualities is as follows,
Computing acts as a link between the devices on the edge and the cloud. It is a network that combines devices linked at the edge with those in the cloud. The design of three layers is one of the most prevalent architectures. Layers are broken down into different levels, Layer 1 is the most fundamental level, and it comprises all Internet of Things devices that are able to store and transfer raw data to higher layers of the network.
Layer 2, known as the "middle layer," is made up of a variety of network devices such as routers and switches that are able to process and temporarily store information. These devices are connected to the network in the cloud, and thus constantly upload data to the cloud at predetermined intervals.
Layer 3 is the topmost layer, and it consists of a large number of servers and data centers that are able to store a large quantity of data and also have the capability to handle it.
The ownership of the fog infrastructure and the underlying features may be used to differentiate between different types of fog models. It has four distinct sorts of fog models.
The term "Big Data" has emerged as a popular phrase in recent times. It is utilized by almost everyone, including academics and professionals in various fields of endeavor. The idea of big data can be traced all the way back to 2001, when Laney presented 3Vs (volume, variety, and velocity) model as a solution to the problems caused by the growing volume of data.
The term "big data" was coined by Apache Hadoop in 2010, and it refers to "datasets that could not be acquired, handled, and analyzed by normal computers within an acceptable scope". In 2011, the McKinsey Global Institute defined "big data" as "datasets whose size is beyond the capabilities of standard database software tools to acquire, store, manage, and analyze". According to the definition provided by the International Data Corporation (IDC), "big data technologies" are a "new generation of technologies and architectures, designed to economically extract value from very large volumes of a wide variety of data by enabling high-velocity capture, discovery, and/or analysis".
Big data was classified according to the following dimensions, which were frequently referred to as the 3V model.
The digitization of material produced by many businesses has become the primary source of data. The development of new data at a rapid rate is another effect of advances in technology.
Data mining can turn a large collection of data into knowledge that can help to solve a problem that affects the entire world.
Although data mining is only a crucial phase in the process of knowledge discovery, the majority of people consider data mining to be synonymous with another phrase that is often used, which is known as Knowledge Discovery in Databases (KDD).
The development of information technology inevitably led to the creation of new opportunities, such as data mining. The database and data management sector evolved via the development of various essential features, including data gathering and the building of databases, data administration (including data storage and retrieval as well as database transaction processing), and enhanced data analysis (involving data warehousing and data mining). The early development of methods for data gathering and the building of databases served as predecessors for the subsequent development of efficient mechanisms for the storage and retrieval of data, as well as the processing of queries and transactions. A large number of database management systems provide query and transaction processing as standard operating procedures.
A significant portion of the art of machine learning consists of simplifying a wide variety of distinct issues into a set of prototypes that are quite restricted. The majority of the research that goes into the field of machine learning is then focused on finding answers to these difficulties and providing solid assurances for the results.
Machine learning is currently coming together from a variety of different directions. Many traditions contribute to its unique strategies and vocabularies, which are currently being integrated into a more coherent discipline in order to make it more accessible (Jordan & Mitchell, 2015). The following fields have contributed to machine learning,
A wide range of various computational architectures includes,
The term "Artificial Intelligence" (AI) refers to a category of computing technologies that have become increasingly advanced in recent years.
In order to have meaningful and productive arguments regarding Artificial Intelligence (AI), greater accuracy is essential because AI may relate to such a wide variety of methods and circumstances. For instance, arguments regarding simple "expert systems" used in advisory roles need to be differentiated from those regarding complex data-driven algorithms that automatically implement decisions about individuals. This distinction is necessary because complex algorithms automatically implement decisions about individuals. In a similar vein, it is essential to differentiate between arguments concerning hypothetical developments in the distant future that may never come to pass and those concerning existing AI that already has an impact on society in the present day.
Symbolic AI works best in small, controlled situations that do not change much over time, where the rules are clear and unambiguous and the variables can be measured (Haefner et al., 2021). The present resurrection of Artificial Intelligence may be attributed in large part to the more recent development of "data-driven" techniques, which are part of the second wave of AI and have seen remarkable growth over the past two decades. This eliminates the need for human specialists and is necessary for the initial wave of AI by automating the learning process of algorithms. The capabilities of the brain have served as a model for the development of Artificial Neural Networks (ANNs). The inputs are first converted into signals, which are then sent through a network of artificial neurons in order to create outputs. These outputs are then interpreted as reactions to the inputs. ANNs are able to solve increasingly complicated issues when they have been given additional neurons and layers. Deep learning refers to the use of ANNs that have many layers. The term "Machine Learning" (ML) refers to the process of modifying a network in such a way that its outputs are seen as helpful or intelligent responses to the information provided by the inputs. This learning process may be automated by Machine Learning algorithms, either by making modest changes to individual ANNs or by applying evolutionary concepts to large populations of ANNs in order to provide progressive gains.
The delivery of computing services is shifting to mimic that of other utilities like water, electricity, gas, and telephones, creating a model in which computing is just another commodity. In this paradigm, customers gain access to services according to their needs rather than the location of the hosting infrastructure. This utility computing vision has been a goal of several computing paradigms, such as grid computing. The next paradigm shift, cloud computing, holds the greatest potential to finally make the concept of computing utilities a reality. Instead of focusing on the problems that need to be solved, researchers often get stuck on computational problems where High-Performance Computing (HPC) might be expected, Low-Performance Computing (LPC) is typically the consequence since computers do not function like people.