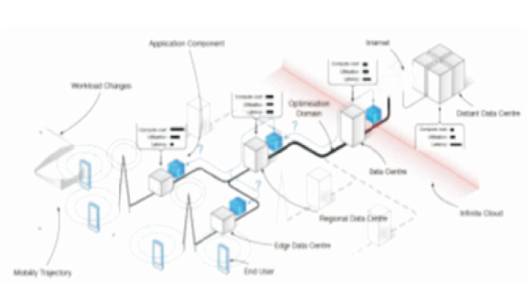
Figure 1. Placement of Resources in Infinity Computing
Due to the huge use of data made available in cloud computing, cloud computing challenged with issues of security on demand application resource management and self-monitoring without latency. This paper explores supervised and unsupervised learning methods on resource provisioning, monitoring, and management topics in cloud computing and examines a number of methods which propose to make use of machine learning to either allow for more self-monitored on demand application resource management or used to know the work level of resources in infinity cloud computing. The authors have also compared regular techniques in resource management in cloud computing like FIFO, VMs cluster management, etc., with machine learning methods.
As cloud computing has become more demanded due to the efforts of top enterprise name companies, such as Amazon, IBM, Google, and Microsoft, it has allowed for the amount of high available data to increase throughput [9], leading to increased chances for utilization. As a result, cloud computing and Machine Learning (ML) have formed a partnership, of sorts, in which both benefit from the other's advancement and refinement.
The highly distributed and heterogeneous environment of the elastic cloud computing introduces many interesting independent resource provisioning management challenges arising from a highly demanded workload, non-homogeneousre sources, user mobility, heterogeneous energy efficiency, and multi-component applications [11].
The complete objectives of an Infinite computing is to ensure that it persistently meets the SLAs of the applications and on demand to it hosts, while minimizing its total resource usage, including energy, latency. It should do so proactively by dynamically placing and scaling applications primarily by means of feedback input of principal foreground network track, resource utilization levels, application workload, and user location changes [3],as in Figure 1. One of the foremost challenges in the Infinite Computing paradigm is how to manage the highly non homogeneous and decentralized resources in a complex system.
Figure 1. Placement of Resources in Infinity Computing
The size of the infrastructure and the number for management parameters renders a fully centralized resource allocation strategy infeasible [9]. As a result, a decentralized collaborative resource management approach needs to be considered. When reassessing an application placement decision, the systems needs to determine if the energy, compute, network, and latency cost fall short of any of the possible placement possibilities that qualify, for a certain period of time.
The systems rate of modification determines the duration under which a decision is valid. The number of possible placement combinations and the rapid rate of change mean discrete placement decisions need to rely on workload, resource availability, and user location prediction. The system needs to be distributed and collaboratively re-evaluate the placement of application components, whenever workload changes for an application, when new applications arrive or are terminated, when applications scale up or down, or when foreground track volumes change [4]. The triggers and decisions need to be at the granularity of individual application components, thus arguably distributed. The propagation of the collaborative reports will thus be bounded by the network's topology and of each application's possible placement alternative.
Based on the enterprise application needs, resource provisioning, management and self-monitoring are classified as below.
For enterprise applications that have expected and generally unchanging demands/workloads, it is possible to use “static provisioning effectively” [2], [3], [5]. With advance provisioning, the customer contracts with the vendor for services and the vendor prepares the appropriate resources in advance to provide services.
In cases where demand by applications may adjustment, “dynamic provisioning techniques” [3] have been recommended whereby Virtual Machines may be transferred same to provide job to new compute nodes within the cloud [3]. With dynamic provisioning, the vendor allocates more resources as they are needed and removes them when they are not. Cloud computing is a feature with pay per use model so for dynamic resource provision customer is billed [7].
With user self-provisioning [2], [3] (also known as cloud selfservice), the customer purchases resources from the cloud provider through a web form, creating a customer account and paying for resources with a credit card. The provider's resources are available for customer use within hours, if not minutes.
In cloud computing to provision the resources, there are different scheduling algorithms which are addressing various challenges [6]. There are machine learning pseudo methods in which the job to Virtual Machine mapping is produced in advance or at the time of execution. Once mapping is executed, such plan cannot be altered during runtime and the workflow engine must predict to what the status of the resources and the tasks is. This rigidity it does not allow them to adapt to changes in the underlying platform and makes them extremely sensitive to execution delays and inaccurate task runtime estimation; a slight miscalculation might lead to the actual execution failing to meet the user's QoS requirements [2], [4]. To meet the user's QoS requirements and to predict the status of the resources, the work flow requisite to adhere machine learning methods in changed circumstances is shown in following Figure 2.
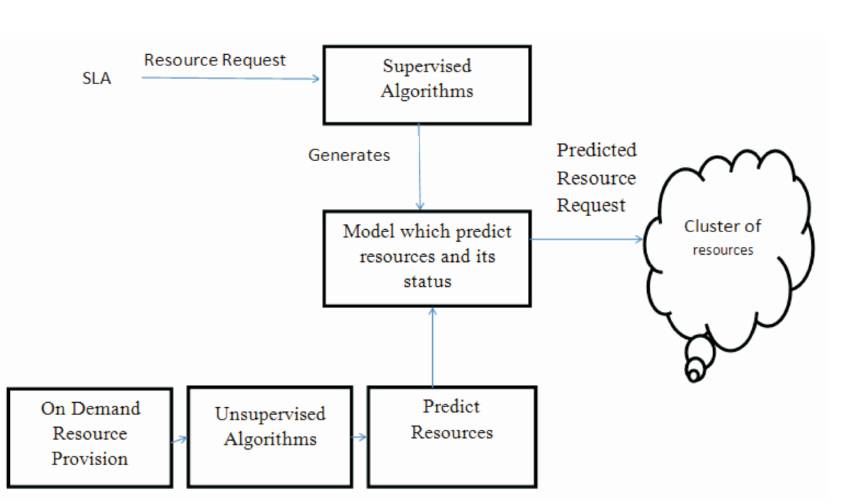
Figure 2. Resource Self-Monitoring using ML Methods
According to Wang and Summers [13], machine learning is the study of algorithms that run on computer system which can learn complex relationships or patterns from distributed data and make accurate decisions.
For efficient use of resources and to implement self-monitoring, several methods are defined by many researchers. For applications that have predictable and unchanging resources demand during execution, it is possible to use static provisioning. In most of the frameworks like ANEKA, Deadline-driven provisioning of resources [13] method is used. To improve the deadline violation rate failure aware, resource provision [5] was proposed by another researcher. To improvise the QoS, user's requirement and to know the work level of resources, we can apply machine learning algorithms model.
Reinforcement Learning (RL) is another type of automatic decision making model which can be applied to resource provision. Dutreilh, X. et al. used the Q-learning algorithm for their work as the Q-function is easy to learn from experience. The approach is; given a controlled system, the learning agent repeatedly observes the current state, takes an action and then a transition to a new state occurs. The new state and corresponding reward is then observed [12]. However, because defining the policy from which decisions can be chosen can take a long time because of iterative methods.
To reduce more number of iterations, LR model is used to predict how the input affects the output and it finds numeric prediction of target class.
A Linear regression model assumes that the regression function E (Y|X) is sequential in the input X1, …,Xp.
The linear regression model has the form:
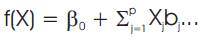
The βj's are the unknown parameters or coefficients, and the variables Xj are the quantitative inputs or attributes. Typically, the parameters β are estimated from a set of training data (x1, y)… (xN, yN). Each (xi1, xi2,…, ip)T is a vector of feature measurements for the ith case [8], [13].
This paper proposed LRP (Linear Regression to predict Priority) model on unchangeable VM mapping with resources.
Procedure to execute job of predicted priority.
Input: New job, all jobs running in host
Output: Execution of all jobs submitted to the host
Begin
Arrival of New job
If (New job. Deadline< all jobs running in host)
High priority job =Predict Priority Using LR (New job)
if (Predict Status Using LR (VM))
allocate High priority job to that VM
else
Suspend job to Selection of Job for execution of high priority job ();
Suspend (Suspend job)
allocate High priority job to VM from which a job was suspended
end if
Execution of all jobs running in the VM
if (completion of a job which is running in VM)
resume (Suspend job)
allocate the resumed job to that VM
end if
Execution of resumed job
End
Using Sample data with cloudsim, the authors have simulated a datacenter with two hosts. These VMs are allocated as hosts based on number of resources available in the host and number of resources required by the VM. Jobs are given to the VMs for execution [5], [11]. The first two jobs are allocated to the VMs based on FIFO basis. The deadline of the next job is predicted. If it has low deadline than the first two jobs then it is predicted as a priority job. Otherwise, the job is suspended. Based on the parameters they have compared RL with LRP. Figure 3 shows the Response Time and Latency Analysis.

Figure 3(a) Response Time, (b) Latency Analysis
Designing new machine learning algorithms to predict minimizing cost and maximizing performance in cloud computing is an active research topic. The scale of infinity cloud-hosted services is huge, encouraging individuals to develop on demand scalable applications at minimal cost that attract large user and enterprise bases. Despite the great potential for developing innovative applications, choosing an appropriate resource allocation is always a difficult task. Autoscaling a multitier Web application hosted on the cloud requires a great deal of domain knowledge and knowledge of the application's performance on the specific infrastructure, making it difficult. In this paper, Machine Learning algorithms were used to monitor and manage resources for a given workload level. Machine Learning methods were presented for predicting online autoscaling policy learning Web applications.
The authors are currently investigating the use of longterm exploration necessary to redesign existing methods under dynamically changing workload distributions, introducing policy learning for scale-down actions, and planning more sophisticated experiments with real-time varying workloads.