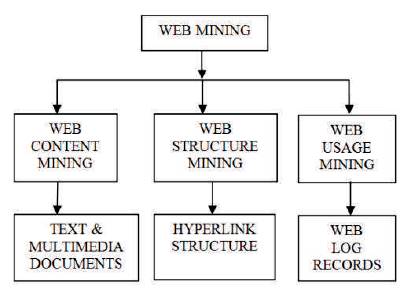
Figure 1. Web Mining Taxonomy
World Wide Web is a huge repository of web pages and links. It provides abudance of information for the Internet users. Web mining is the use of Data mining frameworks to actually discover and concentrate data from web archives and administrations. Web mining is three sorts: Web use Mining, Web content Mining, and Web structure Mining. Web utilization mining is the process of finding information from the cooperation created by the clients in the types of access logs, program logs, intermediary server logs, client session information, treats. A huge amount of user request data is generated in a web log. Predicting user's requests based on previously visited pages is important for the web page recommendation, reduction of latency, and online advertising. The web server log document is naturally made and kept up by a server comprising of a rundown of exercises it performed. The proposed framework is intended for website page forecast in suggestion framework and also it is useful for the investigation of web mining calculation to get incessant consecutive access design from the web log document on the web server. After cleaning, and applying the longest common subsequence and Apriori algorithm, the outcomes of the effective calculation of web log access are inaccurate.
The Internet is a vast resource of data of different sorts: text, pictures, sound, and video. With the continuous growth and abundance of data available on the Internet, the World Wide Web has become a huge repository of information. Web mining is the application of data mining to large web data repositories. Web Mining is the use of information mining techniques to automatically discover and extract information from web documents and services. In the web mining, it runs the process of web server log file in order to web link predict with the prediction model [12-15]. The web is huge, diverse and dynamic extraction of data from web data has become more popular and as an outcome of that web mining has attracted lots of attention in recent time. The goal of web mining for patterns in collecting the web data and analyze the information in order to gain insight into trends and users in general. The taxonomy of web mining has been illustrated in Figure 1.
Figure 1. Web Mining Taxonomy
The major issue in web mining is :
Web Mining comprises of three classes – Web Content Mining, Web Structure Mining, and Web Usage Mining.
Web content Mining is also known as text mining. Content mining is the extraction of data and mining of content, pictures and charts on a web page to determine the relevance of the content to the search query. Web content mining is differentiated from two views:- Agent based or Database Approach.
Agent based approach centers with respect to seeking significant data from the world wide web.
The database approach comprises of databases which contain properties, tables, and outline with characterized areas. It focused on techniques for arranging the same organized information on the web into more collections of resources, and utilizing standard database questioning system and data mining techniques to examine it, for example multilevel database and web questioning framework.
Web structure mining, one of three categories of web mining for data, used to identify the relationship between web pages linked by information or direct link connections. It mines the structure of hyperlinks within the web itself. The structure represents the graph of the link on a site or between the sites.
Web Usage mining is the third category in web mining. It is categorized into three main tasks:
Web navigation, mining is present to improve the web services by removing useful data and knowledge of the web information [6].. Web link prediction is the process to predict the web pages visited by the user based on the previously visited pages by the other users. The web pages may not only contain textual content, but also other types of web data which may also include audio files, video files, and images. The importance of web prediction from the search and recommendation systems can be made more effective through the use and the improvement of web prediction.
In this Paper [1], the web server log document information is used for the research work of web access forecast. The information gave by the data sources can be used to build up a little data to be particular customers, online visits, click-streams, and server sessions. This procedure is used to bunch practically identical moves directly to improve the adequacy of forecast. Figure methods were associated exploitation of every cluster and exploitation of all information sets [1].
Preprocessing of web log record is the central walk for web usage mining. Cleaned information within the wake of preprocessing is that the base of representation, mining and case examination. Some pre processing methodology is related to improve the method of pre processed data [2].
Prediction of user's behavior using web log in web usage mining for next page prediction based on previous history and data of the user. For higher content prediction, supported previous history and data of the user. Most of the information required for web log analysis resides on web server proxy server and web clients. Web page prediction is used to predict the next set of web page that are required by users [4].
Web usage mining predicts the user in accessing the web page exploitation novel algorithms and user navigation patterns using Clustering & Classification from web log data in order to predict user's navigation [5].
In the examination, data cleaning is performed by emission of error demands and movie demand. A session has identical information science address with as way as an attainable half hour between back to back solicitations [7].
Successive access conduct for the clients can be utilized to enhance the execution of future access and also the preaching a lot of time, a page needs to enhance the inertness time [10].
In paper [11], the web server stores all the files to show the web pages. It also provides the concept of creating an extended log file of the user behavior. An internet log file in the web server writes data when a user requests an internet website from the actual server.
We understand that website improvement is regularly dynamical, various Prediction capacities need not consider the direct of repeat, however, rather the web page structure to the burrow web course plans for course needs [3]. The dynamic mining system depends upon the past mining comes to about and framed new examples of the web data.
Clearly, improved information quality can improve the quality of any analysis on it. On the web log, documents with thousands of entries have been recorded by the server. Some of the issues connected with the number of log records has the unnecessary information. The unnecessary information can be minimized or reduced by data preprocessing of the web log data. When the Big data, information, log files are loaded on a web page, then it takes more time to clean the data. On the website page, the log information is not cleaned properly, then the results are not given accurately, and it takes more run time complexity in the web page.
The solution of this problem is to clean and remove the unnecessary entries in web log files. The data cleaning mainly aims to remove log entry images, audio and video files. Using this methodology, cleaning covers outline pages, but all irrelevant pages and leaves only essential pages for experimental studies. It filters the web log data size and improves the access of users.
After the study of literature review, the authors concluded that the Apriori Algorithm is used in combination of longest common subsequence and it gives better result of accuracy in web mining. Prefetching and Prediction are done by the preprocessed data to access the user log to achieve the accurate web page prediction. In their work, they have used the longest common subsequence and an Apriori algorithm to give the best result. The proposed model is shown in Figure 2.
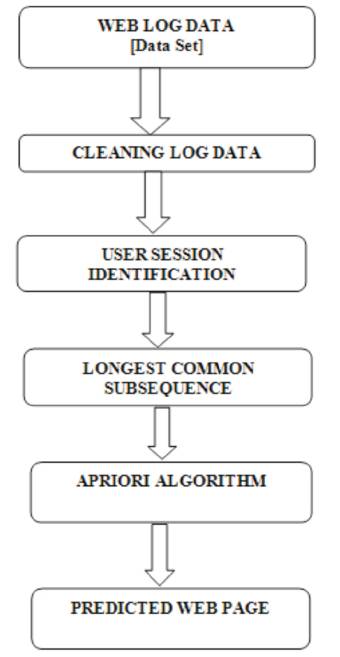
Figure 2. Proposed Model
The log files are maintained by the web server by the activity of the client who access the web server for a website through the browser. The sample log data is shown in Figure 3.
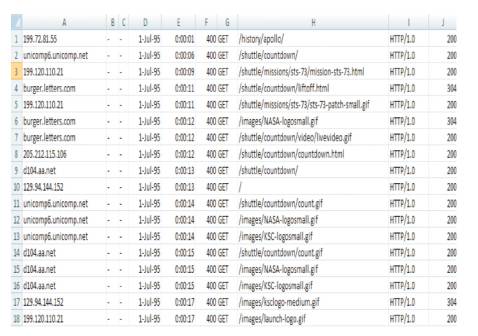
Figure 3. Sample Log Data
There are three kinds of irrelevant or redundant data needed to clean: accessories resources embedded in an HTML file, robots requests and error requests. The steps in cleaning are shown in Figure 4.
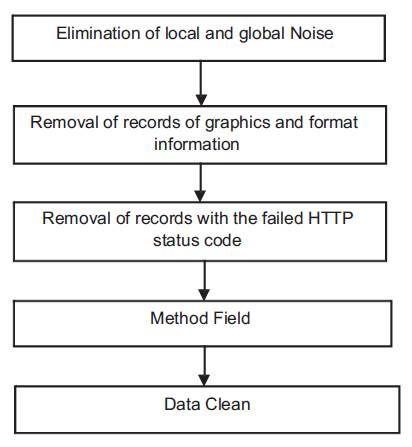
Figure 4. Steps for Cleaning the log Data
User identification is to identify who accesses the website and which pages are accessed. It splits all the pages accessed by a user into the different session. Session identification encodes the navigational behavior of the users, and is very important in web usage mining. A user session is a series of web pages that the user visits in a single website access.
The Longest Common subsequence problem is the problem of finding the longest subsequence common to any or all sequences in a set of sequences. It differs from issues of finding common substrings: unlike substrings, subsequence is not required to occupy consecutive positions within the original sequences. The longest common subsequence problem is a classic computer science problem, the basis of data comparison programs such as difficulty and has applications in Bioinformatics.
Apriori is a calculation of frequent item set mining and association rule learning over value based database. The frequent item sets determined by Apriori can be utilized to decide association rules which highlight general trends in the database.
Prediction data techniques were applied using each cluster and using the whole dataset [8, 9]. Web Page Prediction is improving the accuracy of web page access prediction. By predicting the web pages, we can improve the browsing speed and navigation path.
An analysis performed on the log file information on NASA web log files on July 1995 has been chosen for further analysis. In this research, first we take log file, then we apply preprocessing step on it and remove the unwanted data to clean the file. The raw log file has 15000 web log files, and after cleaning, there were 5891 web log file. Our log file has 321 unique web pages and 214 unique users.
The number of records resulted after the cleaning is represented in Figure 5.
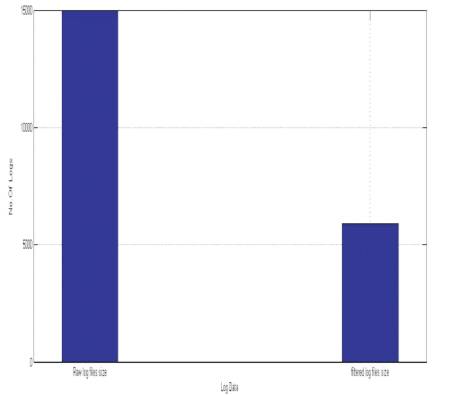
Figure 5. Comparison of Data Cleaning Before and After
For the test session, the corresponding cluster is chosen and that clustered web page is predicted which has the highest probability. In these, we use support and confidence in association rule:
Support (X) = Number of X transactions / Total Transactions and
Confidence (X, Y) = Support (X, U Y) / Support (X)
where Support (XUY) means that the support of the union of the items in X & Y.
From Figure 6, Accuracy in Support is 28.17% and confidence is 61.078%.
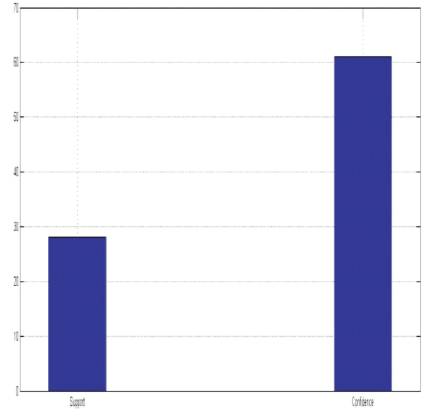
Figure 6. Accuracy of Web Page Prediction
The problem predicts the user's access to the net server. Website Prefetching has been widely used to reduce the user access latency drawback on the internet; its success mainly depends on the accuracy of website prediction. Net usage mining permits the collection of web access information for the web page prediction. Data processing techniques like association rules, Sequential patterns, and clustering can be used to discover the exact patterns. The result of the proposed work shows that the performance of those works are helpful in predicting the user is next page.
In future, the proposed work can be applied to various types of log information to evaluate for page prediction. There are various problems in preprocessing of log information. Analyzing web user access log files helps to improve the design of web components and web applications.