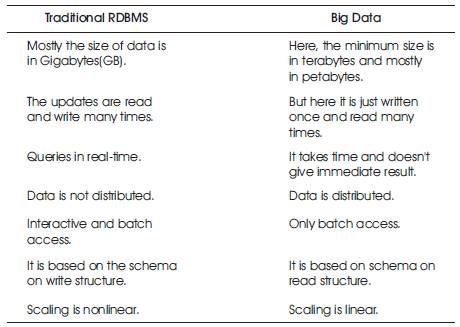
Table 1. Difference between RDBMS and Big Data
We live in the age of big data, where every data is linked to some data source. Digitally, it is difficult to calculate the amount of data. Big data refers to volumes of data in the range of petabytes and beyond. This amount of data exceeds the capacity of online storage and the processing systems. This data creation will cross the zettabyte/year range. The data mainly comes from twitter tweets, Facebook comments and so on. This type of data is normally in the form of images, video and different documents that are in unstructured form. For analysing this large amount of data, Hadoop platform is used which is fast and cost effective. In this paper, the authors have mainly focused on literature review and their challenges.
The term Big data is referring to the massive volume of unstructured data produced by various applications, blog posts and social networking sites.
The Big Data has four Dimensions: Volume, Velocity, Veracity and Variety.
The difference between RDBMS and Big Data is presented in Table 1.
Table 1. Difference between RDBMS and Big Data
The implementation of data analytics on massive data sets is known as big data analytics. Analytics means the processing of raw data to identifying and analysing the patterns of the data. For analysing the big data to The implementation of data analytics on massive data sets is known as big data analytics. Analytics means the processing of raw data to identifying and analysing the patterns of the data. For analysing the big data to minimise the limitation of traditional data processing system, Hadoop tool is used.
To perform analytics on big data, there are 5 steps:
a) Identifying the Problem: First, the problem that we are trying to solve is identified. It is necessary to find out which problem would create higher impact and is further focused.
b) Designing Data Requirement: After identifying the problem, data needs to be gathered from various data sources which will be useful for the analysis.
c) Pre-processing the Data: Pre-processing is performed to translate data into structured format before providing data to different algorithms.
d) Performing Analytics on Data: Different algorithmic concepts like regression, clustering, classification and model based algorithm are performed for analytics on the data.
e) Visualizing Data: For displaying the output of data analytics, Data visualization is used. Visualizing the data is an interactive way to represent the data insights.
The Apache Hadoop is a framework that enables the distributed processing of large data sets across clusters of computers. It is designed to scale up thousands of machines with local computation and storage. The basic idea is to allow a single query to find and collect results from all the cluster members. The biggest challenge in a software system is to provide mechanisms for storing, manipulating and information result in large amounts of data.
The Hadoop ecosystem is presented in Figure 1.
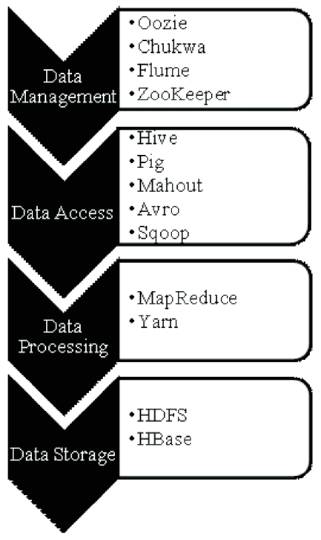
Figure 1. Hadoop Ecosystem
Oozie is an organized system for Hadoop jobs. It is designed to run multistage Hadoop jobs as a single job known as an Oozie job. These jobs can be configured to run on requests or periodically. These jobs running on demand called workflow jobs. Oozie jobs that running periodically are called coordinator jobs. A bundle job is a third type of job in which collection of coordinator jobs is managed as a single job.
For collecting data and monitoring large distributed systems, Chukwa is used which is an open source system.
Flume is a distributed, available and reliable service for powerfully collecting, aggregating, and moving large amounts of log data. Flume has a unique, simple and flexible design based on streaming data flows. It is robust and fault tolerant with reliability mechanisms and many failover and recovery mechanisms. It uses a simple, extensible data model that allows for online analytic application.
Zookeeper is a service, to maintain the services like configuration information, naming, providing distributed synchronization, and group services. All these services are used by distributing applications.
Hive is a data warehouse software that make easy querying and managing huge data sets settled in distributed storage. Hive provides a technique to project structure onto this data and query the data called Hive: HiveQL which is a SQL-like language. It also allows traditional map-reduce programmers to plug in their custom mappers and reducers when it is inconvenient to express the logic in HiveQL.
Pig is a platform to analyse the large data sets that consists of a high-level language (ex: PERL) to describe operations like the reading, writing, transforming, joining and filtering the data. It basically uses the MapReduce's library.
Mahout is an open source project that is used in producing scalable machine learning algorithms.
Avro is a data serialization framework developed. Primary use of Avro is that, Avro can provide both a serialization format for insistent data, and a wire format for communication between nodes of Hadoop, and from client programs to the Hadoop services.
To transfer the data between Hadoop and various relational databases, Sqoop is a tool used to import data from a RDBMS such as MySQL or Oracle into the Hadoop Distributed File System (HDFS), transform the data in Hadoop MapReduce, and then the data export back into an RDBMS.
HDFS is used to import the data from RDBMS such as MySQL and Oracle to Hadoop HDFS, and export from Hadoop file system to RDBMS.
Yarn is the architectural center of Hadoop, the resource management framework that enables the enterprise to process data in multiple ways simultaneously for batch, interactive and real-time data workloads on one shared dataset. YARN provides the resource management and HDFS provides the scalable, fault-tolerant, cost-efficients storage for big data.
MapReduce is a programming model, used for processing and generating huge data sets on nodes of computers. MapReduce runs on a large cluster and is highly scalable. The MapReduce has two parts: Map and Reduce. Map part allows different points of the distributed cluster to distribute their work. Reduce part reduce the final form of the clusters resulting into one output.
Hbase is the Hadoop database that runs on top of the HDFS. HBase provides real time read-write access to huge datasets. HBase scales linearly to handle huge data sets tablewise and it easily combines the data sources of different structures and schemas.
1. Highly Scalable: It is highly scalable because it can store and distribute the sets of data across hundreds of servers that operates in parallel.
2. Cost Effective: It also offers cost effective storage solution for massive data sets. It can store all of a company's data for later use, which saves the cost of storing the raw data in traditional database.
3. Flexibility: In Hadoop, it is easy to access the new source of the data and moving to different type of data to generate value from them. And that can be either structured or unstructured.
4. Fast: Hadoop is based on a distributed file system that 'maps' data wherever it is located on a cluster. The tools for data processing are on the same servers resulting in much faster processing.
5. Fault Tolerance: When the data is sent to a node, that data is replicated to other nodes in the cluster, which shows that at the time of failure, there is another copy available for future use.
The first paradox that the authors described is transparency. Big data guarantees that using this data make the world more transparent. But only collection is invisible while the tools and techniques are opaque. It is about the secrecy. Big data mainly depend on the trade secrets and sensitive personal information in database of big data counsels for security and privacy. Identity is the second paradox because big data threaten the identity while seeking identify. In this, we have our rights that who we are. While accessing the phone records, browsing history, social networking post or tweets and others, identity should be safe from others so that it becomes very risky that either you like that thing or you are that person itself. The Power is the third paradox that author tells about. In big data, power is referred to a tool that enables everyone to view the cleared picture of the world. This big data creates winners and losers which is beneficial for the institutions. Without the privacy, transparency, autonomy and identity, the power paradox decrease the big data's lofty ambitions.
In this paper, the authors describes about how the large data sets are managed which are unstructured in nature. For unstructured, NoSQL approach is used which is based on the key value stores. Data management and data storage are taking separately in NoSQL. Then he told about Hbase, NoSQL database system architecture and how to do analytics on unstructured data with HDFS which processed by MapReduce. Then he showed some benchmarks that reviewed Hadoop as well as several performance factors. In the end, his main aim is on scale out, capacity, and availability of large volumes of data.
In this papers, the author talks about the importance of effective data anonymization and the challenge breaches to achieving it. And also an overview on types of anonymization strategies. He described the area of privacy preserving data. In anatomy of an anonymization failure, data comes in four categories explicit identifiers, quasi-identifiers, nonsensitive attributes, and sensitive attributes. The basic idea behind the data anonymization and privacy implications.
In this paper, the authors talk about the era of big data yield with new management principles. Likewise, future competitive benefits may accrue to companies that can not only store more and better data but also use that data at scale. The executives will be 4 better able to recognize how big data could upend assumptions behind their strategies, as well as the speed and scope of the change that's now under way.
In this article, Ira S. Rubinstein told about the core privacy principles that related to the big data. How big data is a challenge to data protection and the privacy considerations raised by the big data. It also tells about how Regulation and consume for take in big data's privacy challenges including the new ideas for addressing the big data. And in the end, PDSes faces many problems ranging from technical security to the legal framework supporting personal information.
In this article, the authors describe the various aspects of the big data. They defined the big data and their parameters like 3 V's of big data. The authors looked at the process involved for data analytics and reviewed the security aspects of big data and proposed a new system for the security of big data
In this paper, the authors gave an overview of the state of the art and focused on the emerging trends to highlight the hardware, software and application landscape of big data processing. They also described the various Hardware platforms for data analytics followed by various software stack for analytics applications.
In this paper, they have provided an overview of state-ofthe- art research issues and achievements in the field of analytics over big data as well as the analytics over big multidimensional data. They also highlighted the open problems and actual research trends as Data source heterogeneity and incongruence, filtering out unrelated data, unstructured nature of bog data Sources, high scalability query optimization issues. And in the end, they describe how to analytics a big multidimensional data.
In this research paper, a framework is provided that identifies the evolution of various BI & A, their corresponding applications and emerging researches over them. BI & A has an impact of data related problems to be solved in the contemporary business organizations. Different version of Business Intelligence and Analytics are defined and described by their characteristics and capabilities. They also provide a report on critical BI&A publications, researchers and research topics based on related academic and industry publication.
In this article, Vivien Marx describes the big data problems associated with computers and biologists. Life scientists are starting to grapple with huge data sets, encountering challenges and handling, processing and moving the information. For biologists, we need extremely powerful computers to handle the big data jams. He tells about the idea of life of data rich in which, they virtually focus on cloud computing. After storing the data, he told about the highway which is needed to move the data. In the end, the challenges and opportunities are discussed.
In this paper, they explained the concept, characteristics & the need of big data. They also told about different vendors offering big analytic solutions to explore unstructured large data. They covered big data adoption, trends, entry and exit criteria for the vendors, customer success story and benefits of big data analytics. Their analysis illustrates that big data is fast growing and a key enabler for the social business. To solve the problem of big data variety, volume and complexity organizations need to reduce the amount of data being stored.
The chronological summary of description given by various authors is presented in Table 2.
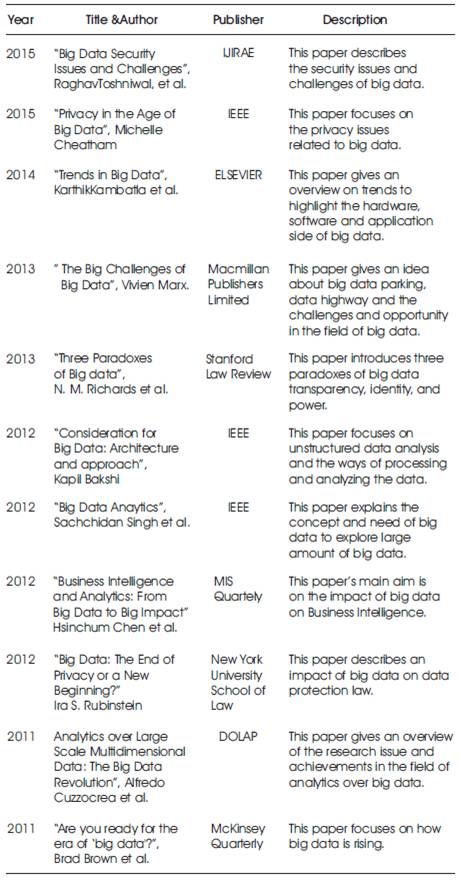
Table 2. Chronological Summary
This paper describes the term big data and analytics related big data. Firstly, the authors introduce the big data and their dimensions and how this big data concept is different from traditional relational database management system. Secondly, five major steps were mentioned on how to perform the analytics process over big data. Hadoop is a framework which is used for processing this data by different services in the Hadoop ecosystem and how this is effective with several advantages. The literature review of various research papers have been scrutinized which gives certain details on big data and Hadoop.
As we are in the age of big data, the volume of data is growing at a tremendous rate, posing different challenges. This survey paper shows how research is going on towards big data and the steps to perform analytics over big data with Hadoop framework and services to analyse the data in a distributed environment. Also, it helps the researchers to understand big data analytics and how this approach is useful in future for maintaining the large volume of data all over the web.