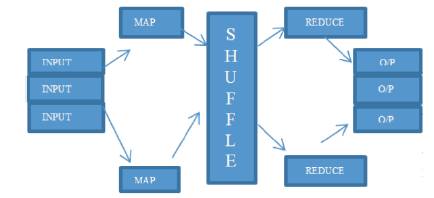
Figure 1. Working of MapReduce
Now-a-days, to achieve an optimized solution for hard problems is a big challenge. Scientists are putting their best efforts to introduce a best algorithm to optimize the problem to a great extent. Genetic Algorithm is one of the stepping stones in the challenge and is an evolutionary algorithm inspired by Darwin's theory of evolution. Using this algorithm, with MapReduce, makes it efficient and user friendly. Users can build more scalable applications with MapReduce, since it provides a better abstraction to the genetic algorithm in lesser time. To parallelize the process of any project, MapReduce plays a vital role on Hadoop platform. The platform may vary from Hadoop to cloud which affect the performance significantly. Parallelizing of a genetic algorithm is convenient with the help of MapReduce. The major objective of the study is to know the behavior of Genetic Algorithm under the paradigm of Hadoop MapReduce. The various applications show different trends influenced by this platform. Also literature review strongly depicts the advantages of Hadoop MapReduce platform over other platforms. Moreover, the difference between various paradigms of Parallelisation is given in the paper to make decisions regarding its implementation of future work.
Genetic Algorithm is a meta heuristic technique, which is being used for finding optimal solutions for hard problems [16, 42]. A genetic algorithm is a mimic of natural evolution [1,2,3]. Genetic algorithm is being used in many large scale problems, as traditional Message Passing Interface (MPI) based parallel genetic algorithm approaches required detail knowledge about the machine learning architecture [30]. So, to provide abstraction in the working of GAs, there is a platform which is known as MapReduce [40].
MapReduce provide a powerful platform for parallel GAs in which, it abstracts the internal working of GAs so that, the user can build scalable application. This feature is first introduced by Google [14, 41, 45].
This paper contains a literature survey on genetic algorithm using MapReduce and some applications related. Also it involves comparison of technologies used in GA. The last section comprises of future trends followed with conclusion.
Map Reduce is a programming model for processing large scale datasets in computer clusters. A Map is a tool or program which runs on datasets and generally divides datasets into various splits separately. Reduce is a programming portion where it is setup to split into logical pairs of data [6,7,18].
Map and reduce both acts as the function map () and reduce (). The major task of map () is to take a pair of input datasets and create it as a pair of key and value which is generally called as the intermediate key/value pair. Then its task of partioning arranges those key/value pair according to their intermediate set. The intermediate sets are sent to the reduce function and reduce () merges the keys and set of values to generate small set of values [8].
Both map () and reduce () is written by the user and the intermediate state is handled by Hadoop MapReduce framework [20, 49]. This working is also shown in Figure 1.
Figure 1. Working of MapReduce
A genetic algorithm is a series of five steps which include initialization, selection, crossover, mutation and termination criteria.
During initialization (a), the process of generating the individuals get started. For the selection process (c), fitness function (b) is evaluated for each individual and two individuals can be selected for further computations. Some information are getting exchanged in both the individuals in a crossover process (d), and finally one new individual is created by recombining the selected individual (e) [33,34,35]. Functioning of GAs is shown in Figure 2.
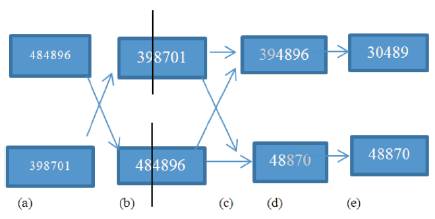
Figure 2. Working of GA [10]
Feature of map () in genetic algorithm implemented in Hadoop is to calculate the fitness function and keep the record of each individual's fitness function in decreasing order. The map function is also writing the new individual in the HDFS. It is task of map () to write the finals in one single file after all iterations. In reduce function, all the methods are described through which, selection and crossover process is carried out [8,9,10].
In this literature review, there is a survey of various applications of genetic algorithm implemented on MapReduce framework.
In 2009, Verma et al. introduced a genetic algorithm using map reduce for scaling. In the framework, genetic algorithm is distributed into various phases. To satisfied Amdahl's law, a separate map reduce function is used [4, 6]. In it, default partitioner is replaced by random partitioner that sends record to reduce randomly so that, it will not overload the reducers. Verma et al. critized this method in their next publication [17,50] and improved in [43,44]. In the improved version, access to HDFS is minimized in such a way that, the reducer function collects the output from the map function directly. It extracts the best individual among the population. Due to this improved version, the algorithm runs faster.
Milos Ivanovic et al. 24 represented a framework for optimization using a parallel Genetic algorithm. It was implemented over the grid and HPC resources. This paper was helpful in removing various shortcomings of static pilot-job framework. It provides complete abstraction of grid complexities and allowed the users to concentrate on the optimization problems. The results obtained by Milos's framework, focused on how the project speeds up when computation were quite high and expensive.
Chengyu Hu et al. was successful in making one of the wonderful applications of genetic algorithm which is called MR-PNGA, that is MapReduce based Parallel Niche Genetic Algorithm. This framework is helpful in determining the water containment resources in large water distribution network. This framework is opted because this project needs extremely high and real time computations. This framework is capable of producing accurate results, plus performance can be improved by exploring it using cloud services [25]. According to this research, other than the five series of steps it includes one more step into the series which is called a niche. The purpose of niche is screening of every individual so that, an individual with best fitness fiction comes out. MR-PNGA is able to find out the multiple possible containment sources fast and accurate.
Masha A. Alshammari proposed a framework through which, it is easy to find the shortest reduction in minimum time. The proposed framework of a genetic algorithm is inspired from the works of Keco and Subasi [12] in which, they used the I/O footprint to minimize the overhead. In the genetic algorithm framework, each instance is compared to other instance, which balance the load and GA population divide among the set of nodes. The optimization situation in this framework is to find the chromosome with the highest fitness level in less time [22]. It is observed by Alshammari that, by double the number of mapper, the performance degrades due to context switching in large clusters [26, 27].
Fei Teng and Doga Tuncay [48] applied the feature of parallel nature of genetic algorithm on Hadoop MapReduce framework and twister iterative MapReduce framework on a max problem to do performance analysis.
Filomena Ferrucci et al. described three models of main grain parallelism which are implemented using the MapReduce paradigm [10]. Those models are
This model is also famous as the, 'fitness evaluation model'. This model is entirely based upon the Master Slave methodology in which, Master computers the GA's series of steps, while Slave computes the Fitness function for each population [38,39]. Figure 3 shows the global parallelization model.
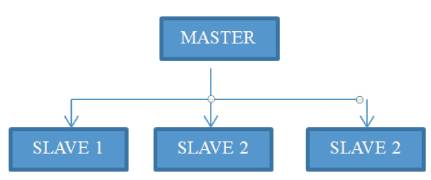
Figure 3. Global Parallelization Model
It is well known as an Island model in which, Population is present in different locations considered as an island and every time the individuals are migrating from one island to another. In this model, Number of reducers is more than a global parallelization model. Each reducer has partitioners which are helpful in implementing the genetic algorithm, parallel [31,32,37]. Figure 4 depicts the Coarse Grain Parallelization model. In the Figure, white oval represents the islands.
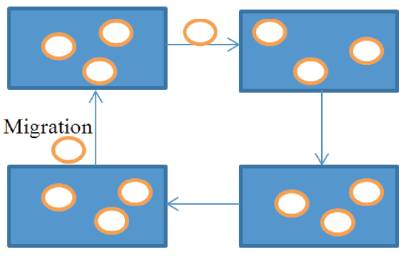
Figure 4. Island Model
This model is inspired by a grid model. In this model, the population is presented in a grid and GA is computed by evaluating the fitness function of a nearby neighborhood. Partitioners are used as a pseudo function [29]. Fine Grain Parallelization model is shown in Figure 5.
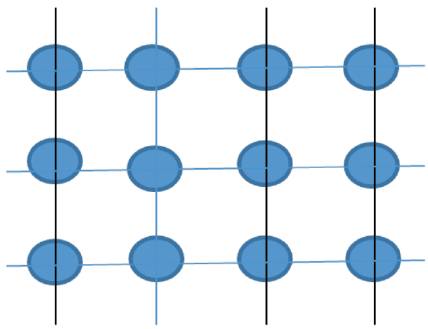
Figure 5. Fine-grain Parallelization Model
Saurabh Arora et al. surveyed the clustering techniques and genetic algorithm is one of such techniques which is used in Big Data Analytics [19, 23, 28].
Comparison between all these three Models of main grain parallelization is shown in Table 1.
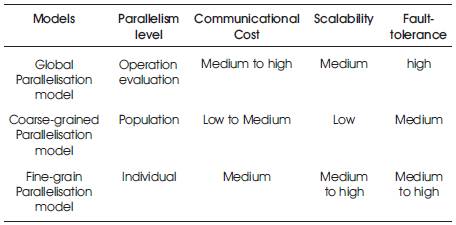
Table 1. Comparison of Main Grain Parallelization Models
Chao Juin and Rajkumar introduced MRPGA which is an extension of MapReduce for parallelizing the genetic algorithm framework. In this project, a Map is used for mapping a population. Only one reduce function is used for reducing the population locally. Sub-optimal individuals are produced by the selection algorithm. Second, reduce function from global selection. To do the second reduction phase, a co-coordinator is required. All the sets of sub-optimal individuals are collected, merge & sorted. MRPGA deploys a different policy that is different individual on the basis of their key are collected as per their locations [5].
Di-Wei Huang and Jimmy Lin implemented a framework in which the authors scale up the population for solving, the Job Shop Scheduling Problem (JSSP). The objective of this model is to schedule J jobs on N machines so that, the overall time to compute all jobs can be minimized. Each job contains an ordered list of operations, which is processed by the certain machine for a particular period of time. According to this project, map phase evaluates the fitness function and the schedule is built as per, chromosomes. In this phase, local search is performed for calculating makespan. Reduce phase do selection and crossover for generating the population as output. A new MapReduce job is also created. The whole process is repeated until JSSP found [15,21].
Iza'in Nurfateha Ruzan and Suriyati Chuprat helped the data scientists by proposing a method of the hybrid algorithm using genetic algorithm that uses Handoop MapReduce for optimizing the energy efficiency in cloud computing platform [11].
The issue mentioned in this paper is that, the rapid growth of demand of data centers increases the consumption of electricity. DVFS (Dynamic Voltage and Frequency Scaling) combined with DPM for reduction of voltage supply and clock frequency. This technique is used to lower the CPU performance ratio when it is not fully applying. During this run time, power consumption is controlled by switching in between the frequency and voltage. Hybrid metric is used to maintain the energy consumption. The GA involvement in this technique is:
Periasamy Vivekanandan and Raju Nedunchezian fixed up another application of mining data stream with the concepts of drift using genetic algorithm. In this paper, it is said that the Genetic algorithm is a strong rule based classification algorithm, which is used for mining static small data sets [36,44]. A scalable and adaptive online algorithm is proposed to mine classification rules for the data structure with the concept of drift. Conclusion given by Periasamy Vivekanandan and his co-author is that, instead of using a fixed data set for fitness calculation, the proposed algorithm uses the snapshot of the training data set extracted from the current port of data stream from fitness calculation. It builds the rules of all classes separately, which makes the rules to evolve quickly [14].
Atanas Radenski [13] brought up with a new idea of distributed simulating annealing application using MapReduce in which, MapReduce is an emerging distributed computing framework for large scale data processing on clusters of commodity servers [46,47]. GA+SA works in two job MP pipeline. In first job, GA is a basic multi-population GA and in second job, there is a general purpose simulated annealing SA.
Dino Keco and Subasi have suggested two models for parallel genetic algorithm using MapReduce [12]. In first model, there is only one map reduce used in one generation. For every new generation of the map reduce, we need new phase of map reduce. HDFS is responsible for transferring the data between each generation of GAS. This model has big IO footprints because each generation of the GA's full population is saved in HDFS. This is the only reason for process degradation. In the second model, only one map reduce function is used to solve each generation of the population. Most of the processing has been moved from reduce phase to map phase due to which, it reduces the amount of IO footprint because all processing are kept in memory instead of HDFS [12].
It is evident that the genetic algorithm provides best optimization in less time. Genetic algorithm has the potential of playing a key role in decision making. With the feature of optimizations, decision making in the business world could be better significantly. Moreover, Genetic Algorithm is showing its footsteps in predicting the effects of disease on brain anatomy. This framework may indulge in better and fast search of the genomic data. In the coming years of data science, this framework will play an important role in predicting health and better DNA combinations. Genetic algorithm and their applications could be able to do bandwidth minimization, latency minimization, fitness optimization, energy optimization, software specialization, memory optimization, software transplantation, bug fixing, and multi-objective SE optimization.