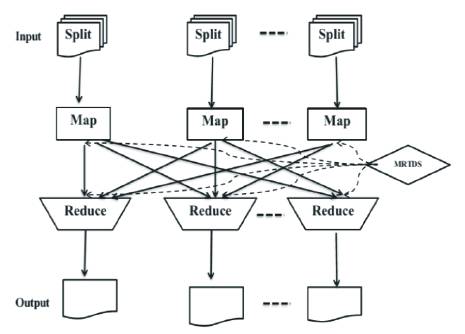
Figure 1. The working of MRTDS anonymization algorithm on MapReducing framework.
In big data applications, data privacy is one of the most important issues on processing large-scale privacy-sensitive data sets, which requires computation resources provisioned by public cloud services. refers to the commercial "aggregation, mining, and analysis" of very large, complex and unstructured datasets. Due to its large size, discovering knowledge or obtaining pattern from big data within an elapsed time is a complicated task. The cloud and the advances in big data mining and analytics have expanded the scope of information available to businesses, government, and individuals. The internet users also share their private data like health records and financial transaction records for mining or data analysis purpose. For which, data anonymization is used for hiding identity or sensitive intelligence. This paper investigates the problem of big data anonymization for privacy preservation from the perspectives of scalability and cost-effectiveness. Anonymizing large scale data within a short span of time is a challenging task. To overcome that, Enhanced Top –Down Specialization approach (ETDS) can be developed which is an enhancement of Two –Phase Top Down Specialization approach (TPTDS). Accordingly, a scalable and cost-effective privacy preserving framework is developed to provide a holistic conceptual foundation for privacy preservation over big data which enable users to accomplish the full potential of the high scalability, elasticity, and cost-effectiveness of the cloud. The multidimensional anonymization of MapReducing framework will increase the efficiency of the big data processing system.
Cloud computing and big data, two disruptive trends at present, offer a large number of business and research opportunities, and likewise pose heavy challenges on the current information technology (IT) industry and research communities [1]. Cloud computing provides promising scalable IT infrastructure resources like massive computation and storage to support various processing of big data applications such as data mining, analyzing and sharing, without major investment in infrastructure up front. Privacy is one of the most important issues in cloud computing. Personal data like financial transaction records and electronic health records are extremely sensitive, although they can be analyzed and mined by the organization. Data privacy issues need to be addressed urgently before data sets are shared on a cloud. Data anonymization refers to hiding sensitive data for owners of data records. Large-scale data sets are generalized using two phase top-down specializations for data anonymization. This process is split into two phases. At first, MapReduce is applied to the Top Down Specialization (TDS) and deliberately designs a group of innovative MapReduce jobs to accomplish the specialization in a highly scalable fashion. In the second one, again the two-phase top-down specialization is applied to multiple data partitions to improve scalability and privacy. The big data is the term given to datasets so large and complex that it becomes difficult to process using normal database management tools or traditional data processing applications. Big Data processing is performed through a programming paradigm known as MapReduce. It is now broadly recognized that advances in big data mining and analytics have expanded the scope of information available to business, government, and individuals by orders of magnitude, facilitating datadriven decision-making and inspiring promising new products [2], and a highly scalable two-phase TDS approach for data anonymization based on MapReduce on a cloud. To make use of the parallel capability of MapReduce in the cloud, classification required in an anonymization process is split into two phases. In the first one, original datasets are partitioned into a group of small datasets, and those datasets are anonymized in parallel, creating intermediate results. In the second one, the intermediate results are aggregated into one, and further anonymized to achieve consistent k-anonymous data sets. It leverages MapReduce to accomplish the concrete computation in both phases. A group of MapReduce jobs are deliberately designed and coordinated to perform specializations on data sets collaboratively. It evaluates the approach by conducting experiments on real-world data sets. Experimental results [3] show that with the approach, the scalability and efficiency of TDS can be improved. It evaluates the approach by conducting experiments on real-world data sets. The major contributions of the research are two fold. Firstly, it creatively applies MapReduce on cloud to TDS for data anonymization and deliberately designs a group of innovative MapReduce jobs to concretely accomplish the specializations in a highly scalable fashion. Secondly, it proposes a two-phase TDS approach to gain high scalability via allowing specializations to be conducted on multiple data partitions in parallel during the first phase.
Data encryption is a straightforward and effective mechanism for privacy protection as it ensures confidentiality. To address the Privacy-Preserving Data Publishing (PPDP) problem, an idealistic and ambitious solution is to utilize the Fully Homomorphic Encryption (FHE) scheme which theoretically allows performing computation on encrypted data and produces the same results as the intended computed values, if performed on the original data [4]. In this way, data users can conduct their data mining or analysing operations on encrypted data published or shared by data holders, without learning the exact individual information. However, FHE incurs high computational overheads for general applications requiring various operations, and is therefore rather slow and time consuming [5]. An efficient fully homomorphic cryptosystem would have great practical implications on private computations in the context of cloud computing.
A theoretically perfect privacy model named differential privacy has been proposed and extensively studied in recent years [6]. For any two close data sets with at most one element difference, an algorithm is said to be differentially private if it behaves approximately the same on both data sets. So, the privacy model guarantees that the presence or absence of an individual will not affect the results of the algorithm significantly. Originally, differential privacy was widely adopted in database query processing with strong privacy preservation [7] . Due to its strong mathematical foundation, researchers began applying differential privacy to various privacypreserving, releasing, or sharing applications, e.g., microdata [7], set-valued data [8] , trajectory data [8], sequential data [8] and search logs [9]. However, differential privacy itself still has some drawbacks as pointed out in [10]. For instance, differential privacy loses trustfulness, guarantees at the data record level because it produces noisy results to hide the impact of any single individual, which is intolerable in some medical and healthcare research [11]. Thus, it is still a challenge to apply differential privacy in privacy-preserving data publishing and sharing. In this thesis, the authors focus on syntactic anonymisation techniques that are more attractive for privacy-preserving big data publishing and sharing at present.
Unlike FHE or differential privacy, data anonymisation is a practical and widely-adopted technology to achieve privacy-preserving data publishing in non-interactive scenarios through releasing or sharing anonymous data to data users. It refers to transforming original data into a form that hides identity and/or sensitive information of individuals [11]. Then, the privacy of an individual can be preserved effectively while certain information is exposed to data users for diverse data mining or analysing tasks. To achieve data anonymisation, explicit identifiers such as name and social security number are removed, while sensitive attributes like disease and salary, and some nonsensitive attributes like age and zipcode, are retained for data mining or analysis. But the non-sensitive attributes can still disclose privacy-sensitive information if they are linked with some external data sources. Such nonsensitive attributes are called quasi-identifiers. Thus, the problem of privacy-preserving data publishing via anonymisation is how to transform quasi identifiers and/or sensitive values to hide privacy-sensitive information.
This paper focuses on the privacy-preserving data publishing problem via anonymisation. This is the scope of the research. More specifically, the generalization operation is adopted for anonymisation due to its semantic consistency and compatibility with existing data mining and analytical tools.
Here, three research challenges of privacy-preserving big data publishing in cloud computing are pointed out, from perspectives of scalability, monetary cost and compatibility.
Big data poses several challenges on privacy-preserving data publishing, with the scalability issue on the top. The huge-volume characteristic of big data deters most of the traditional anonymisation approaches from being applied directly to defend privacy attacks, as they will suffer from the scalability problem. Most traditional approaches are inherently sequential or centralized, and assumes that the data can fit into memory [12]. Unfortunately, the assumption often fails to hold in most big data applications in cloud nowadays. Even if a single machine with huge memory could be offered, the I/O cost of reading/writing very large data sets in a serial manner will be quite high. Hence, parallelism is not just an option but, by far the best choice for big data anonymisation, in order to address the scalability challenge [13]. At present, parallel and distributed paradigms like MapReduce are widely adopted in big data processing applications. Thus, there is still a research gap between traditional data anonymisation approaches and such parallel and distributed paradigms. It is time to take the scalability issue as a firstclass citizen in privacy preserving data publishing. However, it is a challenge to design scalable solutions to big data anonymisation problems due to their intrinsically sequential characteristics. When performing privacypreserving big data publishing in cloud, the monetary cost of computation and storage should be taken into consideration substantially. Due to the pay-as-go characteristic of cloud computing [14], data publishers have to pay for the computation and storage incurred by the big data publisher in proportion to how much cloud resource they consume. Saving monetary cost is a premier driver of cloud computing, which attracts quite a few enterprises to migrate into the cloud. Most traditional anonymisation approaches rarely consider this factor, as there is an assumption that all computation and storage are conducted on their own premises. Hence, it is interesting and beneficial to keep cost-effectiveness in mind when developing anonymisation solutions. However, it is a challenge to figure out [15] where one can save monetary cost in privacy-preserving data publishing in the cloud. Another research gap is between traditional anonymisation approaches and current big data processing platforms and tools. MapReduce, a parallel and distributed data processing paradigm, has become the de facto standard for big data processing. Accordingly, an increasing number of data mining or analytical tools and platforms are built on top of MapReduce, e.g., scalable machine learning library Apache Mahout [28]. However, none of the traditional anonymisation has been built on such a paradigm, while the published or shared data are usually consumed by big platforms or tools mentioned above. As a result traditional anonymisation approaches lack the compatibility [16] to be integrated with the state-of-theart big data mining or analytical tools and platforms seamlessly. Especially, workload-aware data publishing, i.e., the purpose of publishing or sharing data is known in advance, which will be affected heavily by the incompatibility. Therefore, it is interesting and urgent to revise traditional anonymisation approaches [17] in terms of the MapReduce paradigm. However, due to the simplicity of the programming models and the intrinsic complexity of data anonymisation, it is still a challenge to build data anonymisation approaches on top of MapReduce.
The TPTDS method which is used to conduct the computation are required in TDS in a highly scalable and efficient way. The two phases of method are based on the two levels of parallelization conditioned by MapReduce on cloud. Generally, MapReduce on the cloud has two levels of parallelization i.e, job level and task level [18]. Job level parallelization means that multiple MapReduce jobs can be executed concurrently to make a full use of cloud infrastructure resources. Combined with cloud, MapReduce becomes more powerful and stretches, as cloud can offer infrastructure resources on requirement, for example, the Amazon Elastic MapReduce service [22]. Task level parallelization refers to that multiple mapper/reducer tasks in a MapReduce job which is executed concurrently over data splits [19]. To achieve high scalability, multiple jobs on data partitions are parallelized in first phase, but the resultant anonymization levels are not the same. To obtain finally consistent anonymous data sets, the second phase is important to integrate the intermediate results [20] and further anonymize entire data sets.
Firstly, an original data set D is partitioned into smaller units and a subroutine is run over each of the partitioned data sets in parallel to make full use of the job level parallelization of MapReduce. The subroutine is a Map Reduce edition of centralized TDS (MRTDS) [21] which concretely conducts the computation essential in TPTDS. MRTDS anonymizes data partitions to generate intermediate anonymization levels. There are 3 components present in the TPTDS approach, i.e.
When the Data is partitioned [22], the Data is cut into number of pieces required that the distribution of data records in DI is similar to D. A data record here can be treated as a point in a m-dimensional space, where m is the number of attributes. Random sampling technique is adapted to partition. The number of Reducers should be equal to 'p', so that each Reducer handles one value of the brand, exactly producing ‘p’ resultant files. Each file contains a random sample of D.
All middle anonymization levels merge into one in the second phase. The merging of anonymization levels [22] is completed by merging cuts. For the case of multiple anonymization levels [23], one can merge them in the same way in an iterative fashion.
An original data set D is concretely specialized for anonymization [24] in a one-iteration in Map Reduce job. When ‘I’ obtains the merged intermediate anonymization level AL*, run MRTDS Driver (D, k, AL*) on the entire data set D, and get the final anonymization level AL*. Then Reduce function simply aggregates these anonymous records [24] and counts the number of those particular records. An anonymous record and its count represent a QI-group.
This section details about the MRTDS. MRTDS Driver plays an important role in the two-phase TDS approach, as it is invoked in these phases to concretely conduct calculation. Basically, in practice, Map-Reduce program includes a Map and a Reduce function, and a Driver that coordinates the macro execution of jobs which came from this stage. MRTDS Driver, a single Map-Reduce job is insufficient to accomplish a difficult task in many applications. A group of MapReduce jobs are orchestrated in a driver program to achieve such a goal. There are 2 types of jobs in MRTDS Driver i.e., IGPL [Information Gain per Privacy Loss] Initialization and IGPL Update [25]. The MRTDS driver manages an execution process of jobs. MRTDS produces the same anonymous data as in the centralized TDS.MRTDS mainly differs from centralized TDS on calculating IGPL values. But, calculating IGPL values dominates the scalability of TDS approaches [24], as it requires TDS algorithms to count the statistical information of data sets iteratively. MRTDS exploits Map-Reduce on cloud to make the computation of IGPL parallel and scalable.
The important task of IGPL is to initialize the information gain and privacy loss for all the specializations in the initial anonymization level AL. At first, collect the values for each input key [26]. If a key is for computing the information gain, then the equivalent statistical information is updated in this step. Then the reducer just needs to keep statistical information for one specialization at a time, which makes the reduce method which is highly scalable. By this method, ‘I’ initializes job.
The IGPL Update job dominates the efficiency and the scalability of MRTDS [27], when it is executed iteratively as given in this method. So far, iterative Map Reduce jobs have not been well supported by the standard Map Reduce framework like Hadoop. Thus, Hadoop variations [28] like Hadoop and Twist have been proposed recently to support efficient iterative Map Reduce computation. This method is based on the standard Map Reduce framework to facilitate the discussion. The IGPL Update job is little bit similar to IGPL Initialization, except that it requires less computation and consumes less network bandwidth [24]. Therefore, the former is more efficient than the latter. The Reduce function is the same as the IGPL Initialization, which is already given in this IGPL Algorithm.
For the explanation of how data sets are being processed in MRTDS, the framework based on standard MapReduce is explained in Figure 1. The solid arrow shows data flows in canonical MapReduce framework. The iteration of the Map Reduce is controlled by the AL (Anonymization Level) driver [1]. For handling the iterations, the data flows are shown by the curved arrow. AL is dispatched from Driver to all workers including Mappers and Reducers via the distributed cache mechanism.
Figure 1. The working of MRTDS anonymization algorithm on MapReducing framework.
Input: Data set D, anonymity parameters k, k' and the number of partitions p.
Output: Anonymous data set D*.
The value of AL varies in Driver according to the output of the IGPL Initialization or IGPL Update jobs. The amount of such data is extremely small compared with data sets that will be anonymized; and the data can be efficiently transmitted between Driver and workers.
Hadoop [29] is used as an open-source implementation of MapReduce, for the implementation of MRTDS. Since most of the Map and Reduce functions need to access current anonymization level AL, distributed cache mechanism is used to pass the content of AL to each Mapper or Reducer node as shown in Figure 1. Hadoop provides the mechanism to set simple global variables for Mappers and Reducers. The division of hash function in shuffle phase is modified because the two jobs require that the key-value pairs with the same key:p field, rather than that the entire key should go to the same Reducer. To reduce communication traffic [30], MRTDS exploits combiner mechanism that aggregates the key-value pairs with the same key into one, on the nodes running Map functions. To further decrease the traffic, MD5 (Message Digest Algorithm) is employed to compress the records transmitted for anonymity.
Here, a scalable MapReduce based approach for multidimensional anonymisation over big data sets is [30] proposed as shown in Figure 2. The basic and intuitive idea is to partition a large data set recursively into smaller data partitions using MapReduce, until all partitions can fit in the memory of a computation node. Then, traditional multidimensional anonymisation algorithms can be executed on each single node in a parallel fashion, improving the scalability and time efficiency.
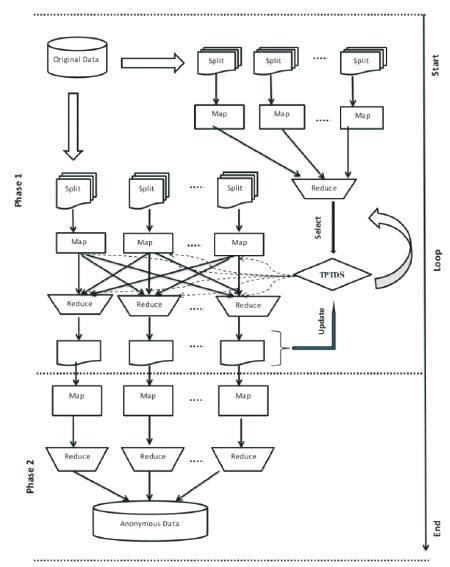
Figure 2. The working of MRTDS anonymization algorithm on multidimensional MapReducing framework
After that, traditional Mondrian algorithms can be executed on each single node in a parallel fashion. Multidimensional anonimyzation with three mapreduce framework was proposed with seed initialization and seed updation algorithm [31]. But in this paper, the multidimensional anonimyzation with three mapreduce framework on MRTDS anonimyzation algorithm as shown in Figure 2, was proposed.
Privacy preserving data analysis and data publishing are becoming serious problems in today's ongoing world. That's why different approaches of data anonymization techniques are proposed. To the best of knowledge, TPTDS approach using MapReduce are applied on cloud for data anonymization and deliberately designed for a group of innovative MapReduce jobs to concretely accomplish the specialization computation in a highly scalable way. The investigation of scalability problem of large-scale data anonymization by TDS presents a scalable two-phase TDS approach using MapReduce on cloud. The data set are divided and anonymized in parallel in the first phase, producing intermediate results. With this approach, the scalability and efficiency of TDS are improved significantly over existing approaches.
There are possible ways of data anonymization in which the current situation may be improved and next generation solutions may be developed. As future work, a combination of top-down and bottom up approach generalization could be contributed for data anonymization in which, data generalization hierarchy is utilized for anonymization. Preserving privacy for analysis of data, mining and distribution is a very challenging issue for research as huge data sets requires search. The data anonymization investigation generalizes a bottom-up algorithm on the large data set.