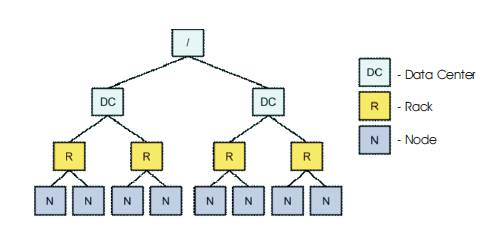
Figure 1. Hadoop Network Topology
Cloud computing and big data are changing today’s modern on demand video service.This paper describes how to increase the speed of video transcoding in an open stack private cloud environment using Hadoop Map Reduce. In this paper, OpenStack Juno is used to build the private cloud infrastructure as a service having map code executing on the node, where the video transcoding resides, to significantly reduce this problem. This practice, called “video locality”, is one of the key advantages of Hadoop MapReduce. This scheme describes the deep relationship of a Hadoop MapReduce algorithm and video transcoding in the experiment. As a result of Map Reduce video transcoding experiment in openstack Juno, outstanding performance of the physical server was observed when running on the virtual machine in the private cloud based on the metrics, in terms of Time Complexity and Quality Check using PSNR (Peak Signal-to-Noise Ratio).
The virtualization tools have been used as cloud technologies to increase the accessibility of high performance hardware computing resources in the cloud computing environment [ 15-16]. In addition, Hadoop Map Reduce software design model emerged as the distributed and parallel processing expertise in order to handle data effectively [ 17,18,19]. In [21], the author describes the correlation between the application attributes and the video transcoding through the performance analysis of Map Reduce Hadoop application for the distributed and parallel process that are conducted in the virtualized cluster environment. For this, the virtual machine instance is generated after configuring private cloud using OpenStack [20]. The results after conducting Hadoop application in the virtual machine instances were analyzed.
Hadoop map code must have the ability to read video “locally”. Some popular solutions, such as networked storage (Network-Attached Storage [NAS] and Storage- Area Networks [SANs]) will always cause network traffic, so in one sense, system might not consider this “local”, but really, it's a sense of perspective[ 1,2,3]. Depending on the situation, it might define “local” as meaning “within a single datacenter” or “all on one rack”.Hadoop must be aware of the topology of the nodes where tasks are executed. Task tracker nodes are used to execute map tasks, and so the Hadoop scheduler needs information about node topology for proper task assignment. HDFS (Hadoop Distributed File System) supports data locality out of the box, while other drivers (for example, Open stack Swift) needs to be extended in order to provide data topology information to Hadoop[4,5].
Hadoop uses a three-layer network topology. These layers were originally specified as Data-Center, Rack and Node, though the cross-Data-Center case isn't common, and that layer is often used for defining top-level switches [7].
In Figure 1, this topology works well for traditional Hadoop cluster deployments, but it is hard to map a virtual environment into these three layers because there is no room for the hypervisor. Under certain circumstances, two virtual machines that are running on the same host can communicate much faster than they could on separate hosts, because there is no network involved.
Figure 1. Hadoop Network Topology
Hadoop is an open source software based middleware on the basis of MapReduce [19]. Hadoop is broadly composed of the two components of HDFS, that is the distributed file system and MapReduce, which is a parallel programming model. MapReduce application of Hadoop is composed of Job, that is the unit of task conducted by clients. Job is composed of input data, MapReduce program and setting information. In addition, Job is executed as being divided into Map task and Reduce task.
The successor to the Ice house release of the OpenStack open source cloud computing platform is OpenStack Juno, debuted on October 16, 2014 as the tenth release of OpenStack. OpenStack Juno's most prominent additions are numerous new networking capabilities, including a Distributed Virtual Router (DVR), enhanced IPv6 support in the OpenStack Neutron networking project, improved Network Functions Virtualization (NFV) support, better visibility into network information, and better support for multiple networks for the OpenStack Nova project [22].
OpenStack Juno, the tenth release of the open source software for building public, private, and hybrid clouds has 342 new features to support software development, big data analysis and application infrastructure at scale. The OpenStack community continues to attract the best developers and experts in their disciplines with 1,419 individuals employed by more than 133 organizations contributing to the Juno release [23].
Figure 2 shows the Openstack Juno, which is an open and scalable operating system for building public and private clouds. It acts as a common authentication system across the cloud operating system and can integrate with existing backend directory services.

Figure 2. Openstack Juno
Openstack has 7 Major components , they are
Figure 3 shows the top Openstack to create a hadoop map reduce environment for performing fast video transcoding technique.
Figure 3. Openstack Cloud Operating System
Figure 4 presents all the major components of openstack Infrastructure as a service. These components are bound together to deliver an environment that allows the dynamic provisioning of compute and storage resources. From a hardware standpoint, these services are spread out over many virtual and physical servers. As an example, most organizations deploy one physical server to act as a controller node and another to serve as a compute node. Many organizations choose to parse out their storage environment onto a dedicated physical server, as well, which in the case of an OpenStack deployment would mean a separate server for the Swift storage environment [6].
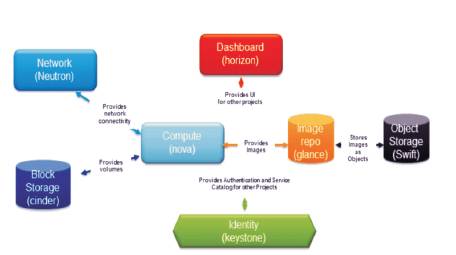
Figure 4. Openstack Components
Table 1 gives the detailed descriptions of all the components of Openstack and its functionalities. All the seven components play a vital role in Private Cloud Environment.
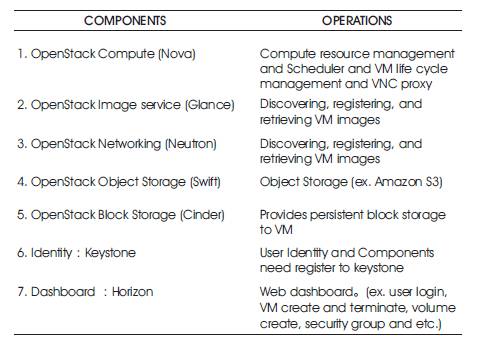
Table 1. Openstack Components
For those organizations looking for an advanced level of flexibility, scalability, and autonomy within their big data environment, they can leverage the native abilities of the open source offerings provided by Apache and Open Stack [8,9].
Open Stack Object Storage (Swift) is a scalable redundant storage system. Objects and files are written to multiple disk drives spread throughout servers in the data center, with the Open Stack software responsible for ensuring data replication and integrity across the cluster. Storage clusters scale horizontally by simply adding new servers. If a server or hard drive fails, OpenStack replicates its content from other active nodes to new locations in the cluster. Because OpenStack uses software logic to ensure data replication and distribution across different devices, inexpensive commodity hard drives and servers can be used [10,11,24].
MapReduce is a framework for processing parallelizable problems across huge datasets using a large number of computers (nodes), collectively referred to as a cluster (if all nodes are on the same local network and use similar hardware) or a grid (if the nodes are shared across geographically and administratively distributed systems, and use more heterogenous hardware)[ 12,13]. Processing can occur on data stored either in a filesystem (unstructured) or in a database (structured). MapReduce can take advantage of locality of data, processing it on or near the storage assets in order to reduce the distance over which it must be transmitted.
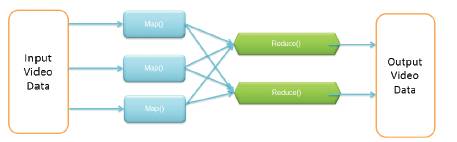
Figure 5. Hadoop Functions
These four steps can be logically thought of as running in sequence – each step starts only after the previous step is completed – although in practice they can be interleaved as long as the final result is not affected.
The proposed video transcoding technique uses JSVM (Joint Scalable Video Model) and deployed in Hadoop Mapreduce in the top of openstack platform. The JSVM software is the reference software for the Scalable Video Coding (SVC) project of the Joint Video Team (JVT) of the ISO/IEC Moving Pictures Experts Group (MPEG) and the ITUT Video Coding Experts Group (VCEG).
The operations are:
The proposed video transcoding uses a novel Prominent Matching Video Transcoding Protocol. The Pseudo of Prominent Matching Video Transcoding Protocol is,
Void Prominent_Matching_Video_Transcoding_Protocol()
{
ReadVideo(profile,videoName)
VideoSpilit()
Map() //Distributed JSVM Transcoding
Reduce() //Combine JSVM Transcoding
VideoMerge()
StoreVideo(newVideoName)
}
function map(Chunck s, Blob video):
begin
for each stream s in video:
encode (s, 1)
end
function reduce(Chunck s , Iterator partialCounts):
begin
for each s in partialCounts:
merge(s,video)
end
This protocol is used to perform the fastest video transcoding technique .
MapReduce achieves reliability by parceling out a number of operations on the set of data to each node in the network. Each node is expected to report back periodically with completed work and status updates. If a node falls silent for longer than that interval, the master node records the node as dead and sends out the node's assigned work to other nodes. Individual operations use atomic operations for naming file outputs as a check to ensure that there are not parallel conflicting threads running. When files are renamed, it is possible to copy them to another name in addition to the name of the task.
Figure 6 describes the step by step functions of fastest MapReduce in openstack. Video transcoding continues to function well as it (or its context) is changed in size or volume in order to meet a user need. So transcoding in MapReduce is scalable. Time complexity is commonly estimated by counting the number of elementary operations performed by the MapReduce algorithm, where an elementary operation takes a fixed amount of time to perform.
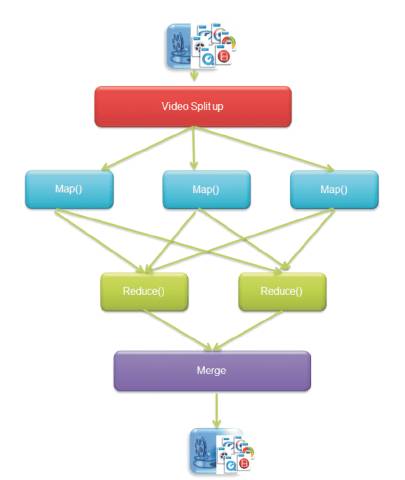
Figure 6. Proposed Video Transcoding
Figure 7 shows the testbed of video transcoding. The testbed comprises a cluster of three machines that run Hadoop and Swift, with one master that runs the Hadoop Job Tracker and NameNode, and the Swift proxy node and two workers that run the Hadoop Task Trackers and DataNodes, and the Swift storage nodes. The proposed system turned off replication to ensure that mappers for the same data partition are always launched on the same machine for HDFS and Swift. The micro benchmarks compare the execution time of file system operations such as 1s or open on HDFS and Swift, executed via the Hadoop API (Application Program Interface). The macro benchmark measures the completion time of MapReduce jobs on both storage systems.
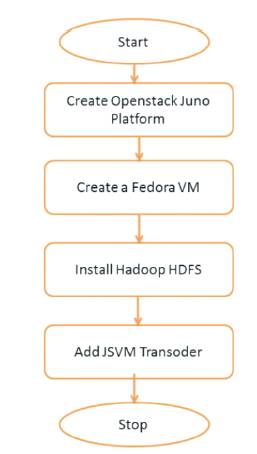
Figure 7. Testbed of Video Transcoding
Video is distributed across the workers in the same way for HDFS and Swift. Hadoop accesses data from the underlying storage system by providing a File System interface. The differences in job completion time are analyzed in more detail when changing the interface implementation. This allows us to identify the specific methods that take longer/are faster for the Swift file system implementation.
The performance of the proposed open stack hadoop merged method is tested by using the Time Complexity and PSNR metric and compared with traditional Physical server methods and individual Hadoop scheme.
Figure 8 shows the new open stack hadoop method proposed based on transcoding time estimation with transcoding servers' information, movie information and target transcoding bit-rate. In experiments, the proposed method produces the best performance scalability according to the increase of transcoding cloud servers.
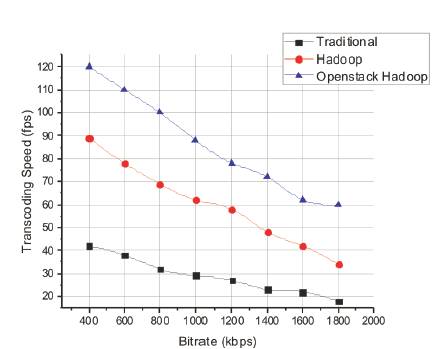
Figure 8. Time Complexity Measurement
The performance measure is the Peak Signal to Noise Ratio (PSNR). It is one of the parameters that can be used to quantify image quality. Compression schemes can be lossy or lossless. Lossless schemes preserve the original data. Lossy schemes do not preserve all the original data; so one cannot recover lost picture information after compression. Lossy schemes attempt to remove picture information, the viewer will not notice. PSNR is usually expressed in terms of the logarithmic decibel scale. The PSNR is most commonly used as a measure of quality of reconstruction of lossy compression codecs (e.g., for image compression). It is most easily defined via the Mean Squared Error (MSE), which for two m×n monochrome images I and K, where one of the images is considered a noisy approximation of the other and is defined as:
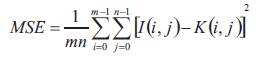
The PSNR is defined as:
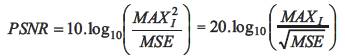
Here, MAXI is the maximum possible pixel value of the image. When the pixels are represented using 8 bits per sample, this is 255. For color images with three RGB values per pixel, the definition of PSNR is the same except the MSE, which is the sum over all squared value differences divided by thrice the image size. Typical values for the PSNR in lossy image and video compression are between 30 and 50 dB where higher is better. Acceptable values for wireless transmission quality loss are considered to be about 20 dB to 25 dB. When the two images are identical, the MSE will be zero. For this value, the PSNR is undefined.
In transcoding, there is a relationship between bit rate or coding rate (compression ratio) i.e. bits per pixel (bpp) and distortion which is shown in Figure 9. Distortion measurement is used to measure how much information has been lost when a reconstructed version of a digital image is produced from compressed data and it is usually measured as PSNR. The Open stack Hadoop Quality quite outperforms the traditional methods.
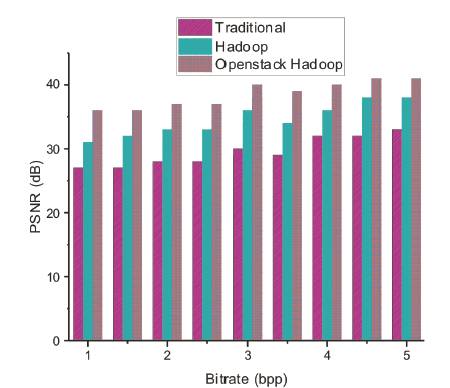
Figure 9. PSNR Comparision
Data processing on Hadoop in virtual environment is perhaps the next step in the evolution of Big Data. As clusters grow, it is extremely important to optimize consumed resources. Technologies like data locality can drastically decrease network use and allow the proposed system to work with large distributed clusters without losing the advantages of smaller, more local clusters. This gives the opportunity for nearly infinite scaling on a Hadoop cluster. This paper compared the physical cluster and the performance after conducting the required evaluation, after configuring a variety of virtual machine instances in the cloud, after configuring the private cloud using Open Stack. Hadoop video transcoding application could obtain the physical server performance of more traditional methods through this experiment, by utilizing the virtual machine. As a result, it was possible through the experiment to find out that the compute intensive application was the element causing a significant change for the performance at both physical environment and virtualized environment. Thus, it is the number of cores and the available memory that matters. The future plan is to increase the scale of our setup and look at different workloads, the impact of replication, and the implications of object size to data locality.