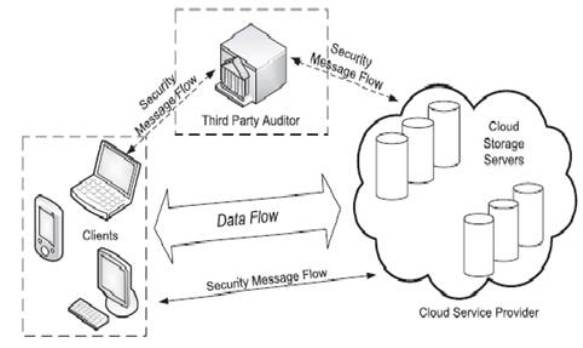
Figure1. Cloud Storage Architecture
Cloud Storage also known as data storage as a service, is one of the most popular cloud computing services. It allows the clients to release their burden of storing and maintaining the data locally by storing it over the cloud. Cloud storage moves the client's data to large data centers, which are remotely located, on which user does not have any control. If multiple providers cooperatively work together, the availability of resources can be increased. But still clients worry that whether their data is correctly stored and maintained by the cloud providers without intact. Hence, there is need of checking the data periodically for correction purpose which is called data integrity .In this paper we will discuss data integrity techniques that has been proposed so far, along with their pros and cons, like Proof of Retrievability (PoR), Provable Data Possession ( PDP) and a High Availability and Integrity Layer for cloud storage(HAIL).
Cloud computing is defined [20] as a model for enabling ubiquitous, convenient, on-demand network access to a shared pool of configurable computing resources (e.g., networks, servers, storage, applications, and services) that can be rapidly provisioned and released with minimal management effort or service provider interaction. Cloud computing provides different types of services, including Software as a Service (SaaS), Platform as a Service (PaaS) and Infrastructure as a Service (IaaS). In addition to these services cloud computing also offers many services, and among those Cloud Storage is an important one, which allows data owners to move data from their local computing systems to the Cloud. Now a day's most of the data owners start choosing to host their data in the Cloud because for small and medium sized businesses it is very cost effective. In this environment Data owners can avoid the initial investment of expensive infrastructure setup, large equipments, and daily maintenance cost, by hosting their data into the cloud and they have to pay for the space they actually use.
Even though Cloud Computing provides many advantages more interesting than ever, it also brings new security challenges towards user's outsourced data.
Sometimes, the cloud service providers may be dishonest and they may discard the data which has not been accessed or rarely accessed to save the storage space or keep fewer replicas than promised [1]. Moreover, the cloud service providers may choose to hide data loss and claim that the data are still correctly stored in the Cloud. As a result, data owners need to be convinced that their data are correctly stored in the Cloud. So, one of the biggest concerns with cloud data storage is that of data integrity verification at untrusted servers. In order to solve these problem researchers have proposed different techniques like POR, PDP and HAIL.
This paper focuses on two core integrity proving schemes in detail along with different methods used for data integrity in both the schemes. Moreover, we have described other data integrity proving techniques. The rest of the paper is organized as follows: Section 1 explains principles of data integrity verification that cover system model and third party auditing. Section 2 reviews different data integrity proving schemes. Final section provides the conclusion.
Storage as a service in the cloud computing offers, client (data owner) the opportunity to store, backup or archive their data in the cloud storage network. So, the main objective of this service is, it should be able to ensure data integrity and availability on a long term basis. This objective requires developing appropriate remote data possession verification. The cloud storage architecture is illustrated in Figure 1. As shown in Figure1, there are three different network entities Client, Cloud Service Provider (CSP) and Third Party Auditor (TPA). Here Client refers to the Users, who stored their data in the cloud and they rely on the cloud for data computation. Cloud service provider (CSP) manages the cloud storage server to provide data storage service. Third Party Auditor (TPA) is optional, usually, TPA has expertise and capabilities that users may not have, clients trust the TPA to assess and expose risk of cloud storage services. To check the correctness of the data stored in the cloud, Verifier may be either a User (Data owner) or third party auditor. The job of the verifier fall into two categories: Private Auditability: It allows only data owner for checking the integrity of the data file stored on cloud server. Public Auditability: It allows anyone, not just the client (data owner), to challenge the cloud server for correctness of data.
Figure1. Cloud Storage Architecture
Trusted TPA is honest-but-curious. The whole auditing process is done honestly by the TPA but it is curious about the received data. Thus, for the storage of secured data, there is also a privacy requirement for the third party auditing protocol. That is, no data will be leaked out to the third party auditor during the auditing procedure. But the server is dishonest and may conduct the following attacks:
Suppose the Server discarded a challenged data block mi or its metadata ti, in order to pass the auditing, it may choose another valid and uncorrupted pair of data block and metadata (mk, tk) to replace the original challenged pair of data block and metadata (mi, ti).
The Server generates the proof from the previous proof or other information, without querying the actual Owner's data.
The Server may forge the metadata of data block and cheat the auditor.
These techniques are used to check the integrity of the data that is stored on the cloud server. These techniques are used by the client to ensure that their data is secure on the server or not. It includes the following techniques to perform integrity check on the data.
In this technique client will compute the hash value for the file F and having key K(i.e. h(K,F))after that it will send the file F to the server. Whenever client wants to check the file, it release key K and sends it to the server, which is then asked to recompute the hash value, based on F and K. Now server will reply back to the client with hash value for comparison. If the response is same as that of the hash value computed by the client then they are sure that data is secure.
In this technique, client can process the data file to generate meta data before sending it to the server. And that can be stored locally for the verification purpose. After that file is sent to the server, and the client delete the local copy of the file. To check the possession of the file, client uses a challenge response protocol and at that time server will respond with the data. Now the client will compare the reply with locally stored meta data. In this way client will ensure that the data is stored securely or not.
Ateniese et al. [3] were the first to take public auditability into account in that they defined “provable data possession” model for ensuring possession of files on untrusted storages. For auditing outsourced data they utilize Homomorphic Verifiable Tags. However, in their scheme they do not consider the case of dynamic data storage, but the direct extension of their scheme from static data storage to dynamic case may suffer from design and security problems. In their subsequent work [4], Ateniese et al. proposed a dynamic version of the PDP scheme to solve prior PDP problems. However, this scheme requires a priori limitation on the number of queries and does not support fully dynamic data operations, i.e., it only allows very basic block operations with limited functionality, and block insertions cannot be supported. In [6], Wang et al. proposed challengeresponse protocol; it determines possible errors and also correct those errors. Similar to [4], this scheme also supports only partial dynamic operations. Erway et al. [5] were the first to consider constructions for dynamic provable data possession. They extend the PDP model in [7] to support dynamic data files using rank-based authenticated skip lists. This scheme is really a fully dynamic version of the PDP solution. To provide the support for dynamic operations, especially for block insertion, it uses authenticated skip list data structure to authenticate the tag information of challenged or updated blocks first before the verification procedure, by eliminating the index information in the “ tag” computation in Ateniese's PDP model [3] . However, it's computational and communication complexity is very high. Narn-Yih Lee et.a l[14], used hybrid cryptography technique to develop a protocol for data integrity verification, which also supports public verifiability. Feifei Liu [7] proposed an improved dynamic model that reduce the computational and communication complexity to constant by using Skip-List, Block, Tag and Hash method. He-Ming.Ruan et.al[15] proposed a framework to enable the remote data integrity verification for online co working scenarios using Bi-linear maps and Merkle hash tree method. Venkatesh et.al[16] in their work they improved public auditability through RSA based Storage Security(RSASS) method.
Scalable PDP is an improved version of PDP. The main difference is that it uses Symmetric key encryption while PDP technique uses Public key encryption to reduce the computation overhead. All the challenges and corresponding response are pre computed in this technique.
Dynamic PDP supports full dynamic operations like insert, update, modify, delete etc. Here the dynamic operation enables the authenticated insert and delete functions with rank-based authenticated directories and with a skip list.
Table1 shows comparison of different Methods used in the PDP Schemes.
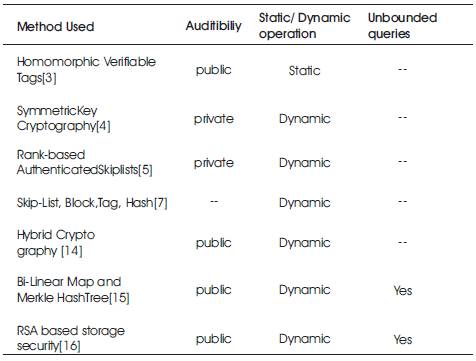
Table 1. Various methods used in PDP
In POR Scheme a cloud server proves to a data owner that a target file is intact, in the sense that the client can retrieve the entire file from the server with high probability. Hence, POR guarantees not only correct data possession but it also assures retrievability upon some data corruptions. POR for huge size of file blocks that named as sentinels. The main purpose of sentinels is, cloud needs to access only a small portion of the file (F) instead of accessing entire file.
Figure 2 shows the data file which is having 5 data blocks and these entire 5 data block contain individual sentinels. In this technique user have to store only a key, that is used to encode a file F, it gives the encrypted file F'. This procedure leaves the set of sentinel values at the end of the file F'. And those sentinel values are identical to regular and they are stored randomly in the file F', so the Server doesn't know that where the sentinel value are stored. Here server stores encrypted file only.
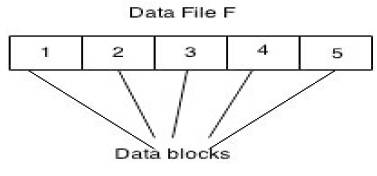
Figure 2. A Data file with 5 blocks
Author of paper [17] proposed a Schematic view of a proof of retrievability based on inserting random sentinels in the data file. Semantic view of POR is shown in Figure 3.
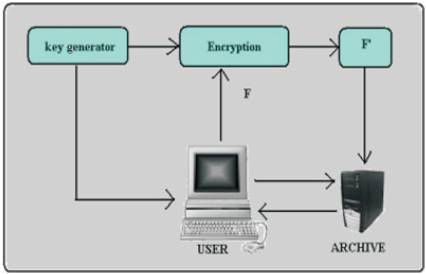
Figure 3. Schematic view of a POR [17]
Figure 3 describes that; user (cloud client) likes to store a file (F) in the cloud server (archive). Before storing the file to the cloud, client needs to encrypt the file in order to prevent from the unauthorized access. Juels and Kaliski [8] proposed a scheme called Proof of Retrievability (POR).
This technique uses challenge response protocol for the integrity verification. For that client send the challenge to the server, at that time server will return a subset of sentinels in F' as a response. If the data is tampered or deleted, the sentinels may get corrupted or lost and so the server is unable to generate the proof of the original file. In this way client can prove that server has modified or corrupted the file.
Juels and Kaliski [8] describe a “proof of retrievability” model, where spot-checking and error-correcting codes are used to ensure both “possession” and “retrievability” of data files on the server. But this scheme does not support public auditability. Shacham and Waters [9] design an improved PoR scheme with full proofs of security in the security model defined in [8]. They use publicly verifiable homomorphic authenticators built from BLS signatures [10], based on which the proofs can be aggregated into a small authenticator value, and public retrievability is achieved. Still, the authors only consider static Data files. Yan Zhu et.a l[18] give dynamic audit service for verifying the data integrity on untrusted and outsourced data based on techniques fragment structure, random sampling and index hash tables. Shu Ni-Na et.a l[19] improved the PoR scheme by using Merkle Hash Tree(MHT) construction for the authentication.
Table 2 shows comparison of different Methods used in the PoR Scheme.
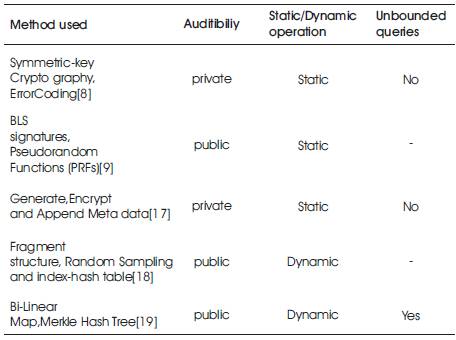
Table 2 .Various methods used in POR
HAIL is unique, apart from the other techniques those have been discussed so far. HAIL supports redundancy of the data by allowing the client to store their data on multiple servers. And the clients can store only small amount of data in their local machines. The threats that can be attacked on HAIL is mobile adversaries, which may corrupt the file F.
HAIL uses the pseudo random function, message authentication codes (MACs), and universal hash function for the integrity process. [11] [12] [13]
Table 3 shows the summary of various data integrity proving techniques proposed so far.
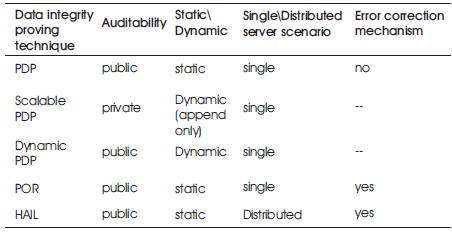
Table 3. Data integrity proving techniques
From this survey, we can conclude that data integrity is emerging area in cloud computing for security purpose. Here, PDP technique supports dynamic operation where PoR technique is not, also PDP scheme does not include error correcting codes where PoR includes it. So implementation of PoR has more overhead than that of PDP due to error correcting codes. Other data integrity techniques are also proposed but many of them are not supported with public auditability and unbounded queries which are basic requirements of data integrity verification. So, developing an efficient, secure and fully dynamic remote data integrity technique is still in open area of research.