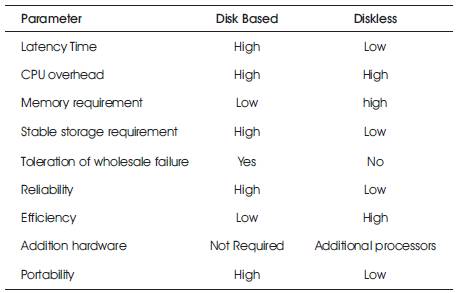
Table 1. On Disk and Disk-less Checkpointing for Parallel and Distributed System [7-20]
Checkpointing is a technique for inserting fault tolerance into computing systems. It basically consists on storing a snapshot of the current application state, and uses it for restarting the execution in case of failure. It is saving the program state, usually to stable storage, so that it may be reconstructed later in time. Checkpointing provides the backbone for rollback recovery (fault-tolerance), playback debugging, process migration, and job swapping. It mainly focuses on fault-tolerance, process migration, and the performance of checkpointing on all computational platforms from uniprocessors to supercomputers.
Checkpointing and restart has been one of the most widely used techniques for fault tolerance in large parallel applications. By periodically saving application status to permanent storage (disk or tape), the execution can be restarted from the last checkpoint if system faults occur. It is an effective approach to tolerating both hardware and software faults. For example, a user who is writing a long program at a terminal can save the input buffer occasionally to minimize the rewriting caused by failures that affect the buffer.
Checkpointing and Rollback techniques offer interesting possibilities to achieve fault tolerance without appreciable cost and complexity increment. It has useful feature for both availability and minimizing human programming effort.
A process may take a local checkpoint any time during the execution. The local checkpoints of different processes are not coordinated to form a global consistent checkpoint [24].
To guard against the domino effect [6], a CIC protocol piggybacks protocol specific information to application messages that processes exchange. Each process examines the information and occasionally is forced to take a checkpoint according to the protocol.
A useless checkpoint of a process is one that will never be part of a global consistent state [23] . Useless checkpoints are not desirable because they do not contribute to the recovery of the system from failures, but they consume resources and cause performance overhead.
A checkpoint interval is the sequence of events between two consecutive checkpoints in the execution of a process.
The system is then required to rollback to the latest available consistent set of checkpoints, which is also called the recovery line, to ensure correct recovery with a minimum amount of rollback.
The ability of a system to perform with a fault present, achieved through reconfigurations, passive fault tolerance, or graceful degradation.
An implementation of fault tolerance such that no action is necessary for the system to perform in the presence of a fault. An example of passive fault tolerance is multiple connections between a module and a backplane of the same signal. One of these connections may fail, and the system will still fully operate.
Action taken in response to a fault resulting in either a controlled loss of functionality or no loss of functionality.
A type of fault tolerance where the system is now operating in a mode with less than full functionality, but with some controlled level of functionality. An example of graceful degradation is the dynamic modification of an algorithm in response to a failure of the sensor.
A manner to implement reconfiguration in which some resources are kept as spares or backups, either hot, warm, or cold, so that they may be used in the event of a failure. Examples of redundancy range from simple spare modules to designing the system with more capability than is necessary so that the extra capability may be used in the event of a failure Dual (or Full) Redundancy.
This section describes the existing checkpointing schemes ([13];[17]; [18] ;[19]).
It is dominant approach for most large-scale parallel systems which requires the application programmer to insert checkpoint code to checkpoint library functions at appropriate points in the computation. It is mainly used to insert checkpoint in the computation when the “live” state is small, to minimize the amount of state that has to be stored [18].
It can save entire computational state of the machine and time, (which is determined by the large-scale system). It requires more saving state than application checkpoints, this means system can checkpoint any application at an arbitrary point in its execution, but allows programmers to be more productive [18].
System-initiated provides transparent, coarse-grained checkpointing, which is better to save the kernel level information and runtime policy whereas applicationinitiated provides more efficient, portable, fine-grained checkpointing, which is aware the semantics of data where application state is minimal and used for compiler optimization.
Cooperative checkpointing is a set of semantics and policies that allow the application compiler and system to jointly decide when checkpoints should be performed. Specifically, the application requests checkpoints, which have been optimized for performance by the compiler and the system can grant or deny these requests.
Application and system-initiated checkpointing each have their own pros and cons. Except transparency, Cooperative checkpointing confers nearly all the benefits of the two standard schemes. In the absence of better compilers or developer tools, however, transparency necessarily comes at the cost of smaller, more efficient checkpoints that are not an acceptable tradeoff for most high performance applications. This is useful to construct reliable systems [18] .
Checkpointing has two phases:
To save a checkpoint, the memory and system, necessary to recover from a failure is sent to storage. Checkpoint recovery involves restoring the system state and memory from the checkpoint and restarting the computation from the checkpoint was stored. When the time lost in computation is called overhead time that has to save a checkpoint and restore a checkpoint after a failure and the re-computation is performed after checkpoint but before the failure. However, this loss contributes to the computer unavailability so is better and beneficial, instead of restarting job after occurrence of a failure. It applies both to system and application checkpoint. Some of the basic action is given below.
Checkpoint saving steps
Checkpoint recovery steps
There are following types of checkpointing:
In checkpoint based methods, the state of the computation as a checkpoint is periodically saved to stable storage, which is not subject to failures. When a failure occurs the computation is restarted from one of these previously saved states. According to the type of coordination between different processes while taking checkpoints, checkpoint-based methods can be broadly classified into three categories.
In this checkpointing, each process independently saves its checkpoints for a consistent state from which execution can resume. However, it is susceptible to rollback propagation, the domino effect [6] possibly cause the system to roll back to the beginning of the computation. Rollback propagations also make it necessary for each processor to store multiple checkpoints, potentially leading to a large storage overhead.
It requires processes to coordinate their checkpoints in consistent global state. This minimizes the storage overhead, since only a single global checkpoint needs to be maintained on stable storage. Algorithms used in this approach are blocking [12] (used to take system level checkpoints and non-blocking (uses application level checkpointing) [3] . It does not suffer from rollback propagations.
In this checkpointing the processes works in a distributed environment where it takes independent checkpoint to prevent the domino effect by forcing the processors to take additional checkpoints based on protocol-related information piggybacked on the application messages from other processors [29].
It is a technique for distributed system with memory and processor redundancy. It requires two extra processors for storing parity as well as standby. Process migration feature has ability to save a process image. The process can be resumed on the new node without having to kill the entire application and start it over again. It has memory or disk space. In order to restore the process image after a failure, a new processor has to be available to replace the crashed processor. This requires a pool of standby processors for multiple unexpected failures [15].
The comparison between disk based and disk less checkpointing for distributed and parallel system in certain parameter is described in Table 1.
Table 1. On Disk and Disk-less Checkpointing for Parallel and Distributed System [7-20]
Double checkpointing targets on relatively small memory footprint on very large number of processors when handles fault at a time, each checkpoint data would be stored to two different locations to ensure the availability of one checkpoint. In case the other is lost using two buddy processors having identical checkpoints. It can be stored either in the memory or local disk of two processors. These are double in-memory checkpointing and double in-disk checkpointing schemes. In this scheme, store checkpoints in a distributed fashion to avoid both the network bottleneck to the central server[8]. The comparison between Disk-based and Memory-based Checkpoint in certain parameter is described in Table 2.
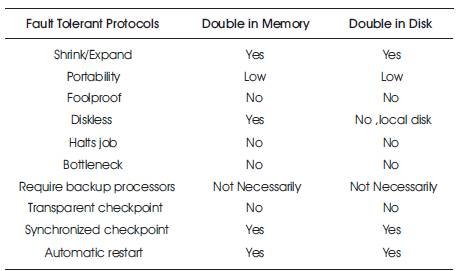
Table 2. Comparison of Disk-based and Memory-Based Checkpoint Schemes
In this checkpointing each process stores its data to memory of two different processors. It has faster memory accessing capability, low checkpoint overhead, and faster restart to achieve better performance than disk-based checkpoint. But it will increase the memory overhead and initiate checkpointing at a time when the memory footprint is small in the application. This can be applied to many scientific and engineering applications such as molecular dynamics simulations that are iterative.
It is useful for applications with very big memory footprint where checkpoints are stored on local scratch disk instead of in processor memory. Due to the duplicate copies of checkpoints it does not rely on reliable storage. It incurs higher disk overhead in checkpointing, but does not suffer from the dramatic increase in memory usage as in the double in-memory checkpointing. Taking advantage of distributed local disks, it avoids the bottleneck to the central file server ([1];[12];[15];[20];[24];[26]).
Based on the literature survey following comparisons have been made and is listed in Table 3.
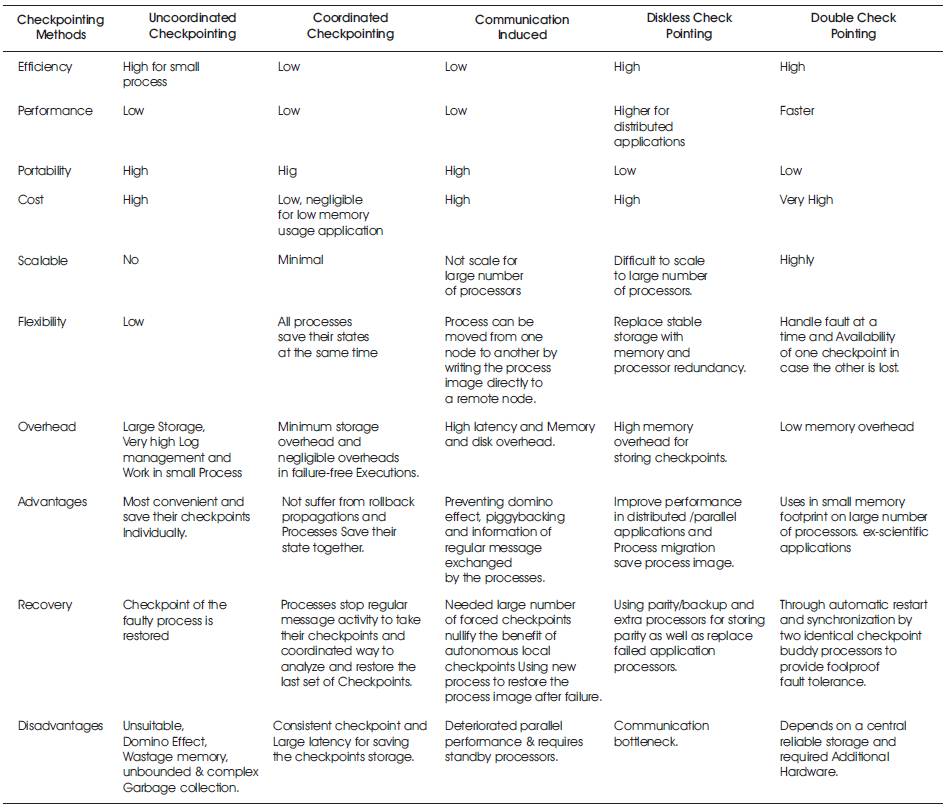
Table 3. Comparative Studies of Different Checkpointing Schemes [1-32]
This paper has stated issues related to Grid Computing, which is main focused on Architecture, Virtual organization, and Faults of grid. Starting with the introduction of fault tolerance definitions, middleware faults, mechanism and the factors that are to be considered while constructing the Alchemi.NET fault tolerance has been discussed. At last different types of checkpointing technique, phases, and types have been discussed. On the comparison basis a better checkpoint technique in different grid environment has been discussed. Research finding and problem formulation in brief has been discussed in future.