(1)
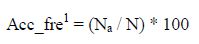
Scalability is an important criterion which is not taken into consideration in the design of most Mobile Ad hoc Network (MANET) protocols. However, requirements of a scalable protocol are different from the ones for small or meso-scale networks. Therefore, MANET protocols exhibit poor performance when the network size is scaled up. Novel approaches that consider the requirements and performance bottlenecks of large-scale networks are needed to achieve better performance. Data replication, as one of the popular services in MANETs, is used to increase data availability by creating local or nearly located copies of frequently used items, reduce communication overhead, achieve fault-tolerance, and load balancing. Prior replication protocols proposed in the literature for MANETs are prone to the scalability problems due to their definitions and/or underlying routing protocols they are based on. In this work, the authors have proposed a data replication framework called extended DREAM. This data replication model considers all replication issues related to Mobile Ad-hoc Networks and provide better solutions to these issues compared to other data replication models available for MANETs.
Everyday, wireless devices, such as Bluetooth-enabled cell phones, PDAs, and laptops become more popular and indispensable for several computer applications. Wireless Local Area Networks are a necessity in our daily lives due to the increasing number of personal wireless electronic devices. However, in some situations, it turns out to be impossible or too costly to deploy permanent infrastructures (i.e. wireless routers, satellite links, cellular systems) for a wireless network, and networking the mobile or static nodes with wireless links in an ad hoc manner can be necessary and effective. The idea behind networking wireless nodes in an ad hoc manner dates back to the DARPA packet radio network research [4]. During 1970s, the ALOHA project used broadcasting nature of radio signals to send and receive data packets in single hop domain. Later, multi-hop communications over Packet Radio Network (PRNET) started in Advanced Research Project Agency (ARPA) [10], which would form the basis of ad hoc networks. In 1990s, Institute of Electrical and Electronic Engineering (IEEE) renamed PRNET to ad hoc network. Consequently, the Mobile Ad hoc Networking (MANET) working group was formed within the Internet Engineering Task Force (IETF) to standardize the necessary protocols and specifications.
A Mobile Ad Hoc Network (MANET) is a self-organizing, infrastructure less, dynamic wireless network of autonomous mobile devices (nodes). The network is adhoc, because there is no fixed and known network structure that every other node forwards data. Thus, the decision of forwarding data among nodes is made dynamically based on the network connectivity. In a MANET, each node is not only an end system, but also a router in the network's multi-hop communication structure. Laptop computers, Personal Digital Assistants (PDAs) and mobile phones can construct mobile ad-hoc networks. MANETs are adaptive networks, which mean they are reconstructed in the case of network changes due to mobility. Generally, nodes forming a MANET are battery powered devices and have energy and bandwidth constraints [2]. Broadcasting and multicasting in MANETs should be carefully implemented due to possible flooding of unnecessary information. Since devices are batter y powered, inefficiency of communication protocols can shorten the active lifetime of these devices. Possible application areas of MANET network structure are military communication systems, Personal Area Networks (PAN), wireless peer-to-peer networks. Furthermore, Vehicular Ad-Hoc Networks (VANETs), which aim to create a dynamic communication structure among vehicles, become a promising research field for MANETs.
In a distributed database system, data are often replicated to improve reliability and availability. However one important issue to be considered while replicating data is the correctness of the replicated data. Since nodes in MANET are mobile and have limited energy, disconnection may occur frequently, causing a lot of network partitioning. Data that is available in mobile hosts in one partition cannot be accessed by mobile hosts in another partition. The issues related to data replication in MANET databases are as follows:-
This section reviews the replication techniques developed for MANETs. A detailed survey on MANET replication techniques is done and that are described as follows.
In [3], the author proposes three replica allocation methods; each method has been studied for both updateless and periodically updated systems. In these replia allocation methods, the main parameter for replication decision is the access frequencies of data items. These techniques make the following assumptions:
For network environments without any update mechanism for data items, following three replica allocation methods are proposed. First is Static Access Frequency (SAF) Method. In SAF, each mobile host gives the replication decision based on only its own access frequencies to the data items. SAF creates low message traffic and low processing overhead, second is Dynamic Access Frequency and Neighborhood (DAFN) method. DAFN method suggests that if there is duplication of replicas between neighboring nodes, then the neighbor with the lowest access frequency changes its replica to another data item. Third is Dynamic Connectivity based Grouping (DCG) method. DCG method shares replicas among larger and stable groups of nodes. DCG method creates bi-connected components of a network.
In [8], the authors proposed another data replication method for MANETs known as Replication Technique for Real-Time Ad Hoc Mobile Databases (DREAM). It focuses on the balancing of energy consumption among the mobile nodes and aims to increase the data availability in the network. Basically, DREAM gives high priorities to the data items that are accessed frequently by the transactions that have time limitations or deadlines. In other words, data transaction classification based on their time limitations (soft or firm) or read/write status, plays an important role during the selection of replicated data. However, differently, this technique extends the replication decision with new decision parameters: link stability, transaction types, data types, and remaining power.
In [6], the authors proposes Collaborative Allocation and Deallocation of Replicas with Efficiency (CADRE) method for replication of data. CADRE [6] tries to achieve fair replica allocation among the mobile nodes in the network and makes the deallocation decisions in mobile nodes collaborative. By doing allocation and deallocation decisions jointly among nodes in the network, CADRE can protect the network from the multiple reallocations of the same data item, which can lead to a trashing condition, that mobile nodes spend more resources on re-allocation of data items than replying other nodes' requests. Most of the data replication techniques developed for MANETs give replication decisions based on the access frequencies and read/write ratios of replicas. As a result of this, if a data item is accessed very frequently in the network, then it is replicated with high priority, even if it is accessed by only a small group of nodes in the network. However, for the sake of the entire network (or fairness in serving the needs of multiple nodes), this kind of replication decisions should be avoided. CADRE suggests fairness among replicated items by assigning a score to each data item d. is the parameter that measures the importance of data item to the whole network. Thus, should be higher for the data items that are preferred in larger number of nodes in the network. CADRE constructs a hierarchical network structure, in which some of the mobile nodes act as a Gateway Node (GN). GNs act as super-peers that are selected among the mobile nodes in the network with higher available bandwidth, higher energy, and higher capacity. They are responsible for replication and query propagation in the network. Unfortunately, if every node in the network has similar capabilities (with respect to bandwidth, energy, memory) than the nodes that are elected as GN will be affected from this situation in an unfair manner. This unfairness can cause increase in the network delay when serving data requests, due to overload in GNs.
In [5], the authors use another mechanism Consistency and Load Based Efficient Allocation of Replicas (CLEAR). CLEAR [5] considers node loads, data sizes, consistencies of replicas, and user schedules during replication decision. CLEAR assumes that the cost of maintaining a desired level of consistency for the replicas of a data item d can be estimated from the percentage of change in the value of an attribute of d. Similar to CADRE [6], CLEAR is based on a hierarchical network structure. In this hierarchy, Cluster Heads (CHs) are responsible for the data validation and replica allocation decisions of their own clusters. Similar to other cluster-based schemes, CH is selected among the mobile hosts in the cluster with the best capabilities (in terms of features, such as energy, memory space, and bandwidth). In this kind of network structure, every node in the cluster sends its update logs and replica lists to their CHs. After collecting these data, a CH decides the data items that should be replicated. Data size and access frequency of an item plays a vital role in this decision. After the candidate data item is selected, CH determines candidate mobile hosts in which the data item can be replicated. Load, access frequencies, memory and energy constraints of a mobile host are used for the replication decision. This technique calculates the cost-effectiveness of the replication for data item d in mobile host M function to give the final replication decision.
In [8], the authors discuss EcoRep [7], a data replication scheme for mobile peer-to-peer systems that is based on an economical model during replica allocation and query requests. For this purpose, EcoRep system puts a price for every data request in the network, and requires the requester to pay this price to the node that serves this request. Price of a data item is calculated by the access frequency, number of users accessed, number of existing replicas of that item and consistency (if it is a replica of the original item). Using a pricing system for every query in the system, EcoRep tries to minimize the number of free-riding nodes. Free-riding nodes are those that do not participate in replication of data items. In EcoRep, this kind of free riding will be discouraged because every node needs some money (authors called currency) for sending query requests to the network. At the same time, nodes analyze the system and replicate the data items that provide the most revenue for themselves. EcoRep also considers energy, load and network topology as replication criterion (factors that affect the price of a data item). For example, if the serving node has a high load during a request, then the price of that request will decrease, because the serving node cannot give a high quality service by means of response time. EcoRep does not consider scalability in terms of message overhead.
In [9], the authors proposed an algorithm Expanding Ring replication technique to increase data availability in pullbased information dissemination environments. In pullbased access methods, mobile nodes query the server for data they need. In this work, server is assumed to be static and known by every node in the system. By this way, the mobile ad hoc network constructed and data request type are different from the previously discussed techniques. In this technique, decision to replicate data is handled by the central static server. Server manages the replicas of the demanded data in such a way that probability of every node finding the data within its close neighborhood increases. This reduces the energy spent by nodes due to packet transmissions. In this scheme, the data server maintains a set of hop count values for every data item. Each time, the access frequency of a data item exceeds a certain threshold; the server selects a set of hop count values for that data item and starts the process of replication on each of the nodes in selected hop set.
In [1], the authors Chen et al. proposes an integrated data lookup and replication scheme for the concept of group data access. Group data access means a group of nodes hosts a set of data items for all other members' usage in the group. Group members can communicate with each other via an underlying routing protocol. Every node broadcasts a periodic ad message, in which a list of data items replicated in that node is carried. Data lookup is achieved by local data lookup tables, which was filled with the incoming ad messages. In [1], they use a predictive data replication scheme, which predicts the partitioning in a network and replicates selected data items in each partition. In this part, they assume that node movement behavior is predictable and with the help of location information and velocity of a node, system can predict the upcoming partitioning. It is stated that this information is taken from the routing layer, which implements a predictive location-based routing protocol. Routing protocol is also defined as part of the cross-layer design given in [1]. In order to spend energy efficiently, this scheme places more replicas at the nodes that have higher capabilities (a combination of free memory, energy and processor workload). Moreover, in order to make data advertising scalable in large scale networks, they adapt the rate of message sending to the number of ongoing messages. This work (like all other replication approaches) is a proactive approach in which data is replicated on nodes explicitly. Finally, this work is similar to previous one in terms of the services it offers, namely data lookup and replication. However it may not be a scalable solution due to periodic flooding of ad messages. It is also a complicated cross-layer design, which may be hard to apply in real life scenarios.
In [11], Yu et al. proposes an optimistic replication scheme based on clustering of nodes into hierarchical groups. It is optimistic because it tolerates replicas to be independently read or modified while data updates are in progress. It uses a distributed hash table for quicker data lookups in a mobile network. DHTR exploits the communication simplicity of a cluster-based hierarchical network structure and claims to decrease the communication overhead of the network. Communication complexity is an important scalability constraint for large scale ad hoc networks. DHTR creates a network architecture that consists of non-overlapping cluster groups that each of these groups is managed by a Cluster Head (CH). CHs are responsible for controlling query and update processes in the network. Every mobile node in a cluster is registered to its group over a CH. Number of CHs is constant and assumed that it is known by all of the nodes in the network. In DHTR architecture, there are also Replica Managers (RM) responsible for holding replicas, replying to the replica requests and informing CHs about the state of their replicas. Also for every data item in the system, a Replica Keeper (RK) is associated. Every CH uses a common hash function to map a data id to the cluster id of that item's RK. One of the important advantages of DHTR over flooding or gossiping based query and update propagation techniques is that DHTR constructs tree-like communication architecture in which every query and update message is directed over CHs and RKs. Yu et al., does not provide a detailed replica management protocol or any details of which data to replicate where. Generally, it targets a scalable query and update propagation technique that can be used in a cluster-based replication algorithm. They also do not define a limited memory space size for replicating nodes, and in their simulation results, they do not investigate data accessibility of the system. Instead, they show improvements on update propagation delay and consumed energy. DHTR also depends on an underlying routing protocol, which we believe could cause scalability problems in large network sizes. Another critic about DHTR is that constructed clusters may not be equally sized and even in the worst case, all other nodes other than CHs can be a member of a separate cluster. Although DHTR suggests a scalable solution for data replication, it may not be the case mostly due to the problems explained above.
In [8], the authors have found some problems, DREAM data replication model is considered as a complete technique because it focuses on all issues of data replication in MANETs and provides better solutions to them. But DREAM suffers with some common problems and they are described as follows:
First of all, DREAM suffers with the problem of data redundancy between neighbor servers, that is two or more data items get the same access frequency at neighbor servers. Let us consider two servers s1 and s2 , these are neighbor servers and there is data item dx, that gets the same access frequency at both servers s1 and s2, thus this data item dx should be replicated at both the servers and data redundancy occurs. If all requests to data item dx at server s1 is fulfilled through server s2 or all requests to data item dx at server s2 is fulfilled through server s1, then there is no need to keep the same data at neighbor servers. To remove the data redundancy at neighbor servers, Redundancy Elimination mechanism is applied, which is based on link reliability ratio between two neighbor servers. If the number of redundant data items and servers are higher in the network then this redundancy elimination mechanism may take a long time to remove the redundancy between neighbor servers.
Second problem in DREAM is that, during write transactions if the co-ordinating server is connected to the primary copy of the requested data item, then the update transaction is forwarded to the primary copy server of that data item, but if the co-ordinating server is not connected to the primary copy server, then the update is made on the local copy of data item at coordinating server and further synchronization is done at the time of relocation period. But at the time of synchronization, if the most updated server (not primary copy server) is disconnected from the network just before the synchronization occurs, then no data items is updated at primary copy server and data became inconsistent for the whole time period until the next relocation occurs. So we can say that DREAM suffers with the problem of data inconsistency between primary and secondary servers.
The problems of DREAM are solved by extending the DREAM model. The Extended DREAM model is incorporated with some changes like the way to calculate the access frequency of the data items at each servers otherwise working of both replication model is same.
The first problem is solved by changing the formula, which computes the access frequency of data items at different servers. As for as DREAM is concerned, the Accesss Frequency is calculated by the number of time data d item (d) is accessed at server (s) and based on this value we further calculate weighted access frequency of d at s. They do not consider other servers that hold this d and other data items kept by s in calculation of access frequency.
Now, a new formula to calculate access frequency of data item (d) at server (s) by calculating access frequency of d first based on all the data items kept by server s and second based on all the servers that hold data item d has been proposed.
First, the access frequency is calculated by considering the percentage number of time d accessed at server s with respect to number of times all other data items that get accessed at server s, by following formula:
N = total number of times data d is accessed at server s.
N = total number of times all data items are accessed at server s.
Secondly, the access frequency is calculated by considering the percentage number of time d is accessed at server s with respect to number of times data item d is accessed at all servers that hold data item d, by following formula:
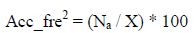
N = total number of times data d is accessed at server s.
X = total number of times data d is accessed at all server s that hold it.
After calculating the above access frequency, access frequency of data d at server s is calculated as follows:
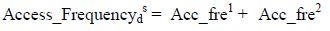
Now this value of Access_Frequency is used for d computing weighted access frequency in the formulae of DREAM technique. For each data items, the access frequency is calculated by above methods. Thus using these formulae, we can get different access frequencies of each data item between neighbor servers and the problem of redundancy is solved during the start of the relocation period by applying Redundancy Elimination Mechanism and the whole process of replica distribution would take very less time in comparison to DREAM.
Second problem which is related to data inconsistency is solved by making new rule. This rule says that if the coordinating server is connected to the primary copy server of data item (d) then all the update transactions on d are forwarded to the primary copy server of d. But if the coordinating server is not connected to the primary copy server of d then update transaction on d is executed with the help of secondary copy server and the local replica of this server is updated. After updating local replica of d, secondary copy server broadcasts the updated value of d with a special message to all other servers until it gets a positive acknowledgment. Whenever a server receives this broadcasted value with special message and this server also has d then it updates its local replica of d and sends back a positive acknowledgment to that server who started this process of broadcast.
By applying the above rule, there are two or more servers in the network that have the most updated value of data item (d). So at time of synchronization if one server is get disconnected from the network that has the most updated value of d then other server is also there with updated value of d for the synchronization and thus data item d is synchronized in both primary copy server and secondary copy servers.
After considering the various open source database servers and clients based on their application requirements, the authors have chosen MySQL [12] server on Linux as the framework for the server database and DALP (Database Access Libraries for PDA) on Windows CE as the framework for the client database system. They have also modified the OLSR routing protocol in Linux to route packets and broadcast additional information like the energy and position of each mobile host. A Global Positioning System (GPS) is also used to track the locations of mobile hosts that are used for both routing packets and for efficient transaction processing. They have modified MySQL and DALP to include the algorithm, DREAM and Extended DREAM and also used this prototype to compare Extended DREAM with the replication technique proposed in [8], which we call the DREAM model and the "No Replication" baseline model. Sections 3.1.1 and 3.1.2 describe the client and the server transaction workflow in the prototype, respectively, and Section 3.1.3 describes the test database application. The deadline of a transaction is computed based on its run time estimate and slack factor. A soft transaction's second deadline is twice as that of its first deadline. The performance is measured in terms of the percentage of transactions successfully executed, energy consumption of servers and clients, and the average difference in energy consumption between two servers. This third metric measures the balance of energy consumption distribution among servers.
Various parameters and fixed values were used in the simulation design model. The static and the dynamic parameters used in this prototype model are shown in Tables 1 and 2, respectively.
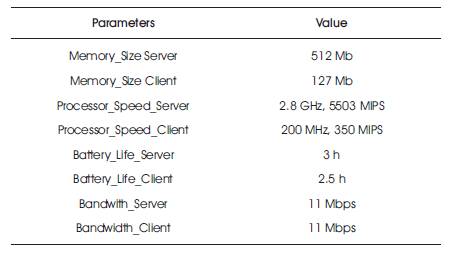
Table 1. Static Parameters
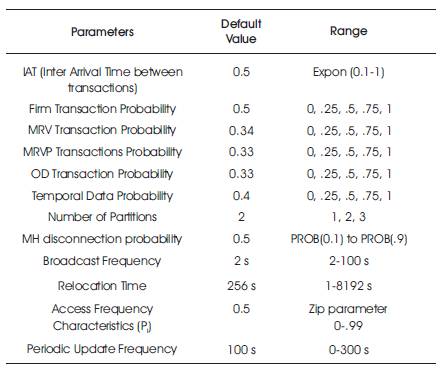
Table 2. Dynamic Parameters
3.1.1 Client Side
Each client is provided with an easy to use interface to generate real time transactions and associate appropriate deadlines to them. DALP provides a set of application programming interfaces that allows handheld devices to connect to MySQL databases. The client sends its firm transactions to the nearest server that has the least workload for processing to minimize the chance of missing their deadlines, while it sends its soft transactions to the highest energy server that has the least workload for professing so that a balance of energy consumption of mobile nodes can be achieved. When the transaction execution is completed, the client receives the transaction results and displays them to the end user.
3.1.2 Server Side
The database server after receiving a transaction f determines if it is a global transaction using its global conceptual schema. Distributed transaction processor functionality has been added to the MySQL database server, which divides transactions into subtransactions and forwards these subtransactions to appropriate participating server(s) that holds the required data. The local transaction processor then forwards these transactions to the real time scheduler that were built into the MySQL server. The real time scheduler schedules transactions with shorter deadlines for execution before those with longer deadlines. The MySQL server has also modified to include a commit protocol that decides to abort or commit the transaction after communicating with the participating servers. After executing the commit protocol, the MySQL server sends the results back to the client.
3.1.3 Test Database Application
The data and transaction requirements were obtained for a military database application from the Reserve Officers Training Corps (ROTC). Relational database tables were created for this application, populated each table with one million rows of data, and generated transactions to retrieve and update the data in the tables.
The impacts of the following four dynamic parameters are reported in this paper: firm/soft transaction ratio, probability of mobile host disconnection, transactions inter-arrival time, and number of network partitions.
3.2.1 Impact of Firm/Soft Transaction Ratio
The impact of the firm/soft transaction ratio on the percentage of successfully executed transactions and the server energy consumption is shown in Figures 1 (a) and 1(b). More transactions miss their deadlines as the ratio of firm to soft transactions increases. Transactions with longer deadlines have more time to be processed and, hence, the probability of successfully executing such transactions is high. Extended DREAM gives more priority for data items that are accessed frequently by firm transactions than those that are accessed frequently by soft transactions. Hence, Extended DREAM has more successfully executed transactions. Consequently, the power consumption of servers in Extended DREAM is the highest. However, the difference in server energy consumption between Extended DREAM and the other two models is considerably lower compared to the difference in the number of successfully executed transactions.
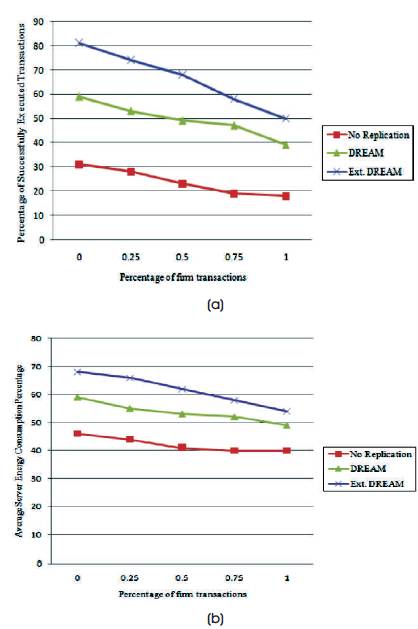
Figure 1 (a) and (b). Impact of Firm/soft Transaction Ratio
3.2.2 Impact of Disconnection Probability
In this experiment, the impact of mobile hosts' disconnection is studied by varying the mobile hosts' disconnection probability. When the disconnection probability is 0.5, the servers are kept out of each other's transmission ranges for 50% of the entire experimental run. When the probability for disconnection increases, the probability for nodes to be in different network partitions also increases.
Thus, some servers might not be able to provide data services to clients that are in a different partition. Hence, the number of successfully executed transactions decreases with the increase in the probability of mobile hosts' disconnection as seen in Figures 2 (a) and 2 (b). As expected, the power consumption of clients is the maximum in Extended DREAM as it successfully executes the most transactions among all the three models. But DREAM yields the most balance in energy consumption distribution among servers.
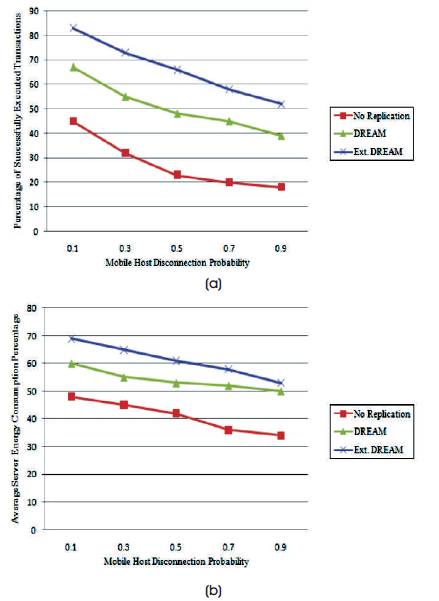
Figure 2 (a) and (b). Impact of Disconnection Probability
3.2.3 Impact of Transaction Inter-Arrival Time
In this experiment, the effect of system workload is studied by varying the transaction inter-arrival time. As transaction inter-arrival time increases, the speed of generating transactions decreases and, hence, the system workload decreases. Thus, transactions have less waiting time for resources and, subsequently, have a higher probability for successful execution. Since Extended DREAM successfully executes more transactions, the power consumption of servers in this model is more than that in the other two models. However, Figures 3 (a) and 3 (b) also show that the additional amount of energy that Extended DREAM requires from servers is much less than the gain it makes in terms of the number of transactions successfully executed.
Figure 3 (a) and (b). Impact of Transactions Inter-arrival Time
3.2.4 Impact of Number of Network Partitions
The impact of the number of network partitions is shown in Figures 4 (a) and 4 (b). As the number of network partitions increases, the number of successfully executed transactions decreases as servers in one network partition cannot provide data services to clients/servers in other network partitions. Server energy consumption distribution becomes less balanced with the increase in the number of network partitions as the isolated servers which host hot data items consume higher power than the other isolated servers.
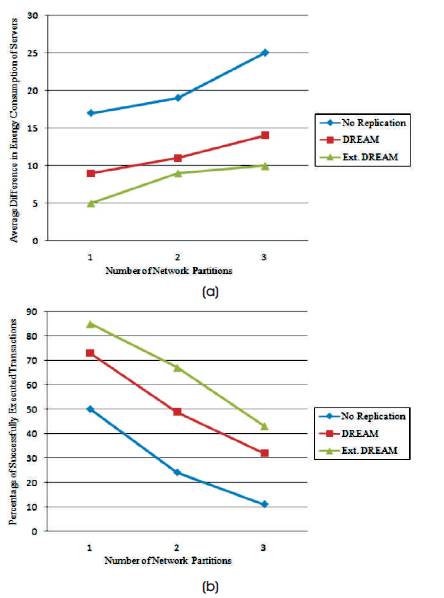
Figure 4. (a) and (b): Impact of Number of Network Partitions
All the above discussed replication models for MANETs consist its own uniqueness and each suffers with some type of degradation. No single existing replication technique considers all of the above issues except DREAM (A Data Replication Technique for Real-Time Ad Hoc Mobile Databases) that addresses all the issues discussed previously, but DREAM has its own limitation. Thus the authors have modified DREAM by making new assumptions to get better results compared to DREAM and other replication techniques. This work proposed a new replication model that removed the problems of DREAM replication model. DREAM suffers with the problem of data redundancy between neighbor servers and problem of data consistency between primary copy server and secondary copy servers. The first problem was related to data redundancy between the neighbors, which was two or more neighbor servers had the same data item. This problem came by getting the same access frequency of a particular data item at neighbor server so same file was replicated at both the servers and thus data become redundant. This became a problem when all requests to data item d at first server was fulfilled through second server or all requests to data item d at second server was fulfilled through first server, then there was no need to keep the same data at neighbor servers. To remove this problem, the proposed model introduced a new formula to calculate the access frequency of each data items and by using that formula we get different access frequency of each data items at neighbors and thus, the problem of redundancy was solved.
The second problem came at the time of replica synchronization, which was data inconsistency. At the time of synchronization between primary copy servers and secondary copy servers, when the most updated server of data item d is found disconnected from the network then this data item d became inconsistent. This problem was solved by maintaining two or more servers with most updated value of particular data item d, which was not the primary copy server of d, by broadcasting the updated value in the network. Thus there was two or more server in the network with most updated value of d and at the time of synchronization if one server found disconnected then other servers were there to synchronize the replicas and problem of data inconsistency was solved.
Thus we can say that the proposed model, Extended DREAM is better than DREAM in terms of number of successfully executed transactions and reduces the number of aborted transactions due to network partition. It also maintains data redundancy between neighbor servers and data consistency between primary copy servers and secondary copy servers.
A possible future work on this work can be mathematical modeling of the proposed replication model and network conditions in order to optimize specific node or network parameters for better performances. For example, in these simulations, its been realized that increasing the number of memory space for a node does not increase the performance of the protocol after a threshold value. However, this value is decided after a mathematical analysis and it is based on simulation model. The authors have also planned to extend DREAM for group-based MANET architectures. Also, they would combine data caching and data replication for further improvement.