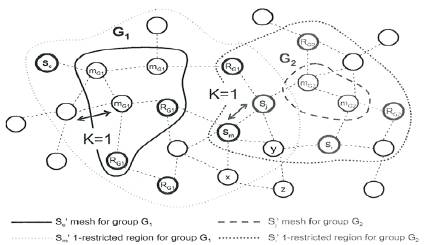
Figure 1. K-restricted region for Hydra Protocol
A Mobile Ad hoc Network (MANET) is a collection of wireless mobile terminals that are able to dynamically form a temporary network without any aid from fixed infrastructure or centralized administration. In recent years, MANETs are continuing to attract the attention for their potential use in several fields such as military activities, rescue operations and time-critical applications. A very important and necessary issue for mobile ad hoc networks is to find the route between source and destination, which is a major technical challenge due to the dynamic topology of the network. Routing protocols for MANETs could differ depending on the application and network architecture. The efficiency of the wireless link can be increased by multicasting, through sending single copy of messages to all group members. This kind of approach is called clustering in MANET. For this one node work as controller and some node act as normal node. This controlling node assigns channel in its group, and that kind of many groups are formed in the network and called as clusters. Various protocols are proposed for this task. But we will design and implement some of the protocols which are most efficient and reliable. The scope of improvement in these protocols are done by analysis and comparisons.
Mobile ad hoc network is a set of mobile nodes which also act as router, and each node has high mobility, and these nodes can move regardless of geographic position. Here each node has fixed wireless range, so to communicate from source to destination, we use intermediate node. These intermediate nodes work as relay, so that these nodes cannot access information, but can collect information and transfer to its neighbour. As a result, information is transmitted from source to ultimate destination. This process is called as hopping.
In MANET, information is transmitted from source to destination by multiple hops, this is called multi-hop communication. A node can deliver a packet by three ways as Unicast, Multicast and Broadcast. According to kind of packet delivery, route between source and destination is created[1]. In this work, the authors define multicast routing protocols and its application and comparison between various multicast routing protocols and then define the proposed routing protocol with increased capabilities.
The term multicasting refers to the transmission of packets from more than one node or in general the authors define it as the transmission of information to the group of nodes. This application is utilised in conference kind of applications, where more than two users are communicating to each other. Many protocols are proposed for this task.
Generally multicasting is done by forming multicast grouping and multicast group can be formed by either tree or mesh in a group[3]. In a group, each node does not have same functionality;in each group according to protocol one node acts as a group leader of that particular group and coordinates the overall controlling of group and remaining all nodes act as ordinary nodes.
The group leader is responsible for any activity that occurs in the group. Generally group leader becomes receiver and receive information from other group leaders and transmit to required nodes. So at a time it performs both the operations, receiving information from other node (group leader) and transmitting to other node (ordinary node). This is a challenging issue, to define group leader for dynamic environment. Many protocols are proposed as, On Demand Multicast Routing Protocol (ODMRP), Multicast Adhoc on Demand Distance Vector (MAODV) protocol, and these protocols form groups as tree and mesh but there is no strategy to define a node as a leader of group. So there is a need to define node as a leader of group on priority basis, which is a disadvantage of these protocols. After that some multicast protocol. as Core Assist Multicast Protocol (CAMP), Ad-hoc multicast routing (AMRIS) protocol are used[5] [6] as sequence numbers for defining the group, so a group hello message is broadcast in the network,thereby number of controlling packets are minimised. But still problem of dynamic environment remains unresolved.
Protocol for Unified Multicasting through Announcement (PUMA) is the first protocol which is defined for this purpose. Here leader of the group is defined as the node which first starts transmission. It will become leader of the group and remaining all nodes will act as ordinary nodes, but if more than one group is formed and in any case they have same or some common area then interference is produced [4] so to overcome this interference the data aggregation technique is used in our proposed work and HYDRA protocol will be more efficiently used for this purpose.
In the presiding section we saw how many protocols are available for this work. In the next subsection, the authors will define working and operation of these protocols and then compare them for good Quality of service issues.
After this through simulation, we will show improved work function of these protocols.
On-Demand Multicast Routing Protocol (ODMRP) is mesh based routing protocol. Main purpose of the on-demand protocol is to reduce the overhead in multicast route. ODMRP is very effective protocol with high efficiency. It uses the concept of forwarding group. There are two phases in ODMRP: route request phase and reply phase. It uses the join query message to create the mesh and to refresh the membership information. It uses soft state approach for maintaining the mesh. Node need not send the message to leave the group.
The Multicast On Demand Distance Vector Routing Protocol is one of the best known network-layer tree-based multicast routing protocols for MANET.It constructs a loop free shared tree for each multicast group in an on-demand manner.In MAODV,nodes use a sequence number and define routing table, the routing table contain sequence number and neighbours and cost merit to reach specific neighbour, and each node contains information about each of its neighbour.
When sender wants to send the message, it will discover route and send the message. If any node wants to join the group, it will send the route request message. Each node maintains three tables: unicast route table, multicast route table and group leader table. Each multicast group have unique address and group sequence number. Each group has a group leader who maintains the tree by periodically sending the group hello message. The member who creates the group first, i.e who joins the group first, is the group leader. MAODV is good for small groups. Performance will be degraded in high mobility and high traffic.
CAMP [4] uses a shared mesh structure. All nodes in the network maintain a set of tables with membership and routing information. CAMP uses hard state maintenance approach to support multicast group membership. Moreover, all member nodes maintain a set of caches that contain previously seen data packet information and unacknowledged membership requests. Cores are used to limit the flow of JOIN REQUEST packets. CAMP possesses good control traffic scalability to facilitate the increased size of a multicast group. Since JOIN_REQUESTS are only propagated until they reach a mesh member, CAMP does not incur exponential growth of multicast updates; as the number of nodes and group members increase, it represents a significant advantage with respect to bandwidth allocation and energy consumption.
However, an important disadvantage of CAMP is that it employs a unicast routing protocol to handle network convergence and control traffic growth in the presence of mobility. Another major disadvantage of CAMP is that it assumes that the routing information from a unicast routing protocol is available and that the correct distance to the specified receiving node can be determined within a specified time. Finally, CAMP assumes that a wireless router contains a pre existing mapping service that provides group addresses which are identified by their specific names.
AMRIS establishes a shared tree for multicast data forwarding. AMRIS does not require a separate unicast routing protocol. Each node in the network is assigned a multicast session ID number. The ranking order of ID numbers is used to direct the flow of multicast data. The main difference between AMRIS and other multicast routing protocols is that each participant in the multicast session must have a session specific multicast session member id (msm-id). This msm-id provides each node with an indication of its ―logical height‖ in the multicast delivery tree[7]. The drawbacks of AMRIS are that each node must send a periodic beacon to signal their presence to neighboring nodes and that it is very sensitive to mobility and traffic load. The primary reasons for its poor performance are the number of necessary retransmissions and the size of beacons, both of which create overhead and can cause increased congestion.
Protocol for Unified Multicasting thorough Announcement (PUMA) is a mesh based, reactive, receiver initiated routing protocol. PUMA protocol is advantageous due to its high packet delivery ratio and limited congestion[8] [9]. Each node generates single control packet that is the multicast announcement. It contains core Id, group sequence number, distance to core and group id. Multicast announcement is used to create mesh, to select core, to maintain the mesh. PUMA selects one core who maintains the mesh. Core periodically generates and broadcasts the multicast announcement. PUMA has high packet delivery ratio and low overhead compared to other protocol. PUMA is more stable. It is more robust against the link breakage compared to other protocols. Performance of PUMA is good in high mobility, more receiver and high traffic. After comparison of protocols, we selected PUMA protocol because it does not rely on any unicast routing approach. Here, CAMP follows unicast routing approach and this may incur considerable overhead in a large ad hoc network.
ODMRP is improved version in terms of control packet overhead as compared to DCMP and NSMP. MAODV and AMRIS, on the other hand, are tree based protocols and they provide only a single route between senders and receivers.
Multicast sources in Hydra periodically broadcast (Join Query Q) messages to establish a partial ordering of the nodes in the network. In the case, of ODMRP and Hydra, the ordering is based on the nodes distances in hops to the sources. This ordering is further used to route Join Reply messages from receivers to sources, forcing intermediate nodes to join either a mesh or a tree[10]. However, Hydra uses three mechanisms to build a routing structure as close as possible to a set of source-rooted breadth-first trees (or meshes composed of the union of breadth-first trees) spanning all the receivers while incurring as few control packets as possible.
In contrast to ODMRP, Hydra uses an elected source as the core of the group, and this is the only source whose Qs reach the entire network. Non-core sources take advantage of the routing state established by the core to identify connected sub-graphs containing themselves and the receivers of the group. This way, the scope of the dissemination of JQs from non-core sources is restricted to these connected regions, and other parts of the network are not flooded with unnecessary control information [2] .
Hydra also identifies regions of the network where two or more sources share common sub-graphs (meshes or trees) and performs routing-state aggregation, so that nodes located inside those common regions only keep routing state regarding one of the aggregated sources and receive JQs and J Rs only from and for that source. To detect the boundaries of a common sub-graph, Hydra compares the orderings established by previous sources with the ordering that is being established by the current Q from a non-core source. If the ordering induced by the J is equivalent to the ordering established by a prior Q from another source, then the current JQ is not forwarded any further and the two sources that have equivalent orderings are considered as aggregated.
Two partial orderings over a graph are equivalent if the gradient vectors among neighbours obtained from the two orderings are the same. As the number of senders increase, the likelihood of finding equivalent regions also increases, because nothing prevents a source to share different sub graphs with different sources, or a given sub-graph to be shared by more than two sources [11]. This property helps the scalability of Hydra with respect to the number of sources.
The authors also note that, while Hydra takes advantage of having a core, it is not necessary for its correct operation. In order to save bandwidth, Hydra opportunistically groups control messages of different sources and groups into control bundles. However, in the rest of our description [13], we focus on the signalling intended for a single multicast group.
Because non-core nodes benefit from the routing structure created by the core, the transmission of JQnCs is roughly synchronized with the reception of JQs. Upon receiving a J Q with a larger sequence number, non-core senders wait for a random period of time that is much smaller than the join query period, but long enough to allow the establishment of the routing structure of the core before transmitting their next J QnC. That J QnC refreshes the routing information for that source. Non-core senders also send J QnC when they have data to send but no route is known to the receivers, or when the sender has not received a JQ from the core in the last two consecutive join query periods.
The objective of the combined use of JQs and JQnC for a given multicast group is to order all nodes with respect to the core of the group, and to make the multicast routing structure (mesh or tree) as close as possible to the aggregation of the source trees of all the multicast sources in the group. JQs must be sent to all nodes; however, the overhead due to the dissemination of J QnCs is reduced using the following two mechanisms. The first way of reducing the overhead incurred with J QnCs consist of disseminating them only to a subset of the network composed of nodes that are part of the mesh or tree established by the core, nodes that lay in the path from the non-core sender to the core[14], and nodes located at most hops away from them. The set of nodes that forward JQnCs for a given non-core sender is called the source's krestricted region of interest or simply k-restricted region. This way, the dissemination of J QnCs is carried out only among nodes that are likely to be close to receivers, and other regions of the network do not receive irrelevant control information.
The optimal value for a k-restricted region depends on the topology of the network, as well as on the mobility of the nodes and on the length of the join query period. In our experiments, a sensitivity analysis showed that a reasonable value for k is one. In general, as the value of k grows, the k-restricted region grows larger, which helps to cope with mobility. In the worst case, the k-restricted regions cover the entire network, and the scheme degenerates to the case of flooding the network with control packets per sender per group as in ODMRP [3].
Figure 1 illustrates, the above concepts. The figure shows two multicast groups, G1 and G2, with their respective cores, 8e and j. Each group has a non-core source m for G1 and 8 for G2 . The mesh of the core 8e of G1 is composed of nodes labelled mCl and the mesh of the core 8 of G is composed of nodes labelled In the Figure. The I-restricted region of m is delimited by a dotted line.
Figure 1. K-restricted region for Hydra Protocol
The authors observe that it contains the mesh constructed by the core of the group 8e, which is delimited by a solid line, as well as the nodes located one hop way from the mesh or from the path from the non-core sender to the mesh. JQnCs generated by 8m are forwarded only by such nodes as node or node y, which are located inside of the Irestricted region, and nodes located outside of this region, such as node z, which may receive the packet but do not forward it. The figure also presents a similar situation for group G2.
The second way to reduce the number of JQnCs sent to the network and the state kept at nodes consist of finding common sub-graphs and performing multicast state aggregation on these particular regions of the network. Nodes located in a common sub-graph only receive and forward JQs (or JQnCs) of one of the sources that share that sub graph and keep state about the source whose join queries are forwarded. Figure 2 shows an example of a network in which two sources, 8e and 8 share a common sub-graph. With this goal, we propose the Dissemination of Multicast Aggregated-State (DIMAS) algorithm. From the standpoint of message complexity, DIMAS behaves as simple flooding in the worst case[15] [16]. However, depending on the current topology of the network, DIMAS stops disseminating control packets of non-core senders before covering the whole k-restricted region.
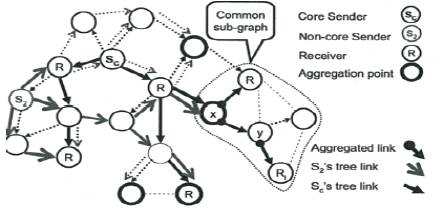
Figure 2. Aggregated Sub graphs
MATlab is taken for creating scenarios and analyze the result. MATlab generates the strong trace file, and due to this fact, it is selected for this work also it has inbuilt random number generation that can be extended to use a large sequence of random numbers.
So user can define in program the fixed values or different random values to show the coordination of the nodes, or set the location of the nodes.
This is timer based simulator, so here we can set particular timers for a particular event, which is a very useful feature of this simulator. This is event simulator; here many events can be set at different times.
For this comparison, the authors have taken variable number of nodes in a simulation environment and compared PUMA and hydra multicast protocol, in terms of routing overhead, throughput, and packet delivery ratio.
Simulation results of both protocols are illustrated in the Tables.
Based on Tables 1 and 2, throughput of HYDRA is greater as compared to PUMA protocol .Graphical results are shown in the graphs.
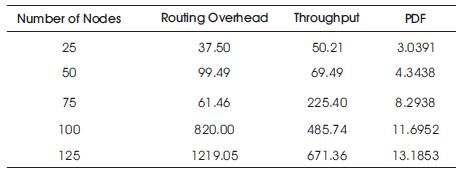
Table 1. Performance Evaluation of Puma
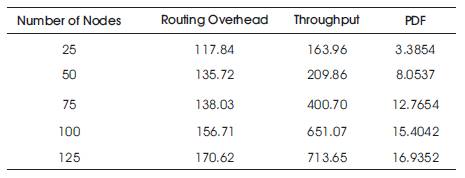
Table 2. Performance Evaluation of Hydra
From above graphs, it is concluded that in HYDRA, the packet delivery fraction and throughput, is increased, packet overhead is increased in PUMA. (Figures 3 and 4).
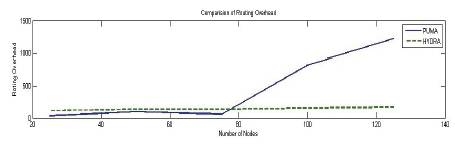
Figure 3. Comparison of Routing over head of PUMA with Hydra
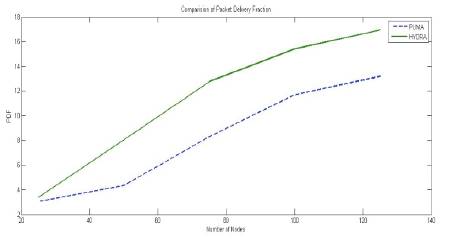
Figure 4. Comparison of Packet Delivery Fraction PUMA with Hydra
So the authors conclude that HYDRA has better performance in terms of transmitting the packet, but in terms of energy it lacks behind PUMA.