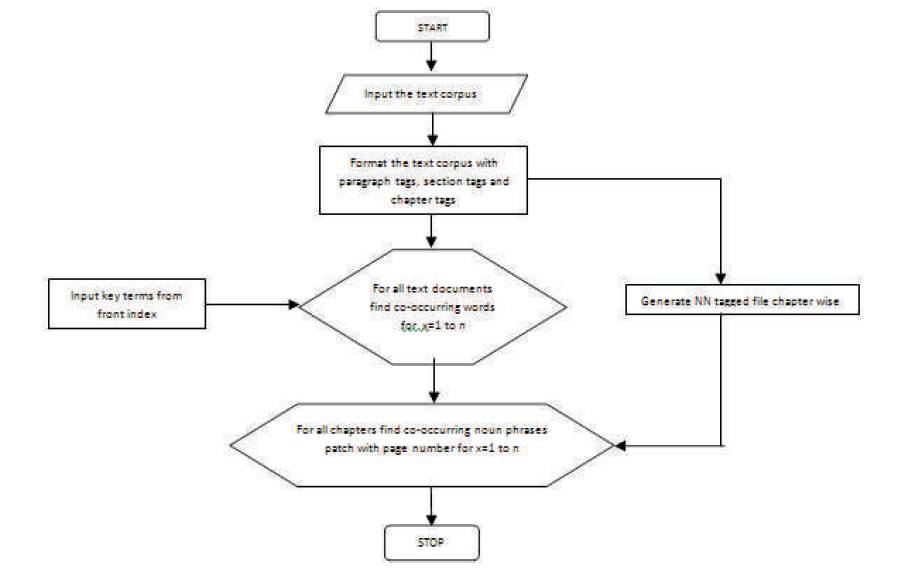
Figure 1. Process Flow Digram (PFD)
An index (plural: indexes) is a list of words or phrases ('headings') and associated pointers ('locators') to where useful material relating to that heading can be found in a document. Generally the books consists of Back Indexes for minimizing the effort and time to search certain topic or word. Manually generated such Back Indexes have certain flaws. The paper describes the Back-Index-Tool of the generation of books in machine readable format, thus minimizing the effort of generation of back index of book manually, reducing the redundancy of occurring words in generated Back Index. The aim of the paper is to construct precise and complete back index for E-books.
Providing the right information to the right user at the right time at the right place is not an easy task. The voluminous information existing in the form of unstructured texts need appropriate tools and aids to guide both document lists and end users utilizing them, and in this process, indexing is seen as a tool.Generation of subject indexes assumes the availability of unstructured texts - books in compatible machine-readable format obviously published with a front index. One cannot think of any release or publication without a table of contents.From the mentioned motivational perspective, the facility of computerassisted subject indexing is in high demand in community repositories, especially for the readers as subject domain experts. These also emerge as facilities where automatic syntactically fetched keyword indexing services rendered by professional (amateur) indexers become inefficient due to the problems of obvious term-synonymy and termpolysemy [1], [2]. In computer science and information science, ontology formally represents knowledge as a set of concepts within a domain, using a shared vocabulary to denote the types, properties and interrelationships of those concepts [10], [11], with reference to such research and development projects being performed in the text mining realm, to construct precise and complete back index for any book available in machine readable format.
The necessity to create such a tool was felt after making following observations:
So to solve these constraints there are some solutions considered in the paper. These are:
The following section 1, presents the related work in the Text mining realm for generation of Back Index. The phrase “text mining” is generally used to denote any system that analyzes large quantities of natural language text and detects lexical or linguistic usage patterns in an attempt to extract probably useful (although only probably correct) information [7], [8]. Section 2 explains the proposed methodology for the work. Section 3 explains the work preluded followed by Implementation and results in section 4. The next Section 5 gives the Conclusion and Future Scope of the work.
Since similarity plays an important role in word acquisition, evaluating the similarity measure allows us to construct clusters of nodes comprising of similar concepts or themes or terms, forming individual display units of complete subject index. Hence, the authors aim at representing texts in the form of concept graphs or subject graphs, a step ahead of the formulation of a sorted dictionary of concept trees as implemented in the CLASSITEX++ system (2000) [3], which deals with trees of concept in a specific domain of text and obtains significant differences from most frequent to least frequent concepts. This also inspires the usefulness of unigrams to n-grams, where, 'n' is the no. of correlated words used in the formation of a specific concept or term [5]. This speeds up the pattern-matching process to find multiple occurrences of a particular k-word long concept in sub tree comprising of a list of k-grams.In order to make an efficient search, indexing process is designed to be 'user-centered' [6]. To select a small set of best terms, as done by Concept Assigner, the system makes use of readily available as controlled vocabularies or relevant information source units to automatically generate domain-specific thesauri subsets forming initial concept spaces.
There had been several works done for the generation of back index. Few of them are mentioned below.
The related work in this direction has mostly exploited the explicitly available domain Ontologies viz. subjectdictionaries, thesauri, glossaries and controlled vocabularies. In the current ongoing research, the idea of implicitly extracted 'front indexes' of the books has been sought to proceed with the semantic processing. The above school of thought arises from the observations of already conducted experiments taking explicitly available relevant controlled vocabularies as Ontologies, where, the generated subject-indexes were found incomplete and imprecise to some extent.Hence, taking the assumption that an unstructured text is available as a book in a compatible machine -readable format along with a front index, the task of computer-assisted subjective indexing begins with initializing of a chapter header index. The highlighted keywords form the 'table-of-contents' or section, subsection and paragraph header titles, that may be boldfaced or italicized, symbolizing the start of any paraphrased text, nominated as header phrases, are collected in a array-like storage structure, giving the appearance of chapter-header index, also known as grown-front-index. The authors do not remain isolated from the intermediary steps of text pre-processing where upon, miscellaneous notes, summary, conclusions, bibliographical and historical notes, exercises, additional readings and discussions may not be considered as a part of core content and hence, can be trimmed out, as demanded. The extraction of header sequences also needs thorough scanning of text, chapter wise, for identification of boldfaced and enumerated titles. A step prelude to the extraction of header sequences needs thorough scanning of text, chapter wise for identification of boldfaced and enumerated titles. This identification process is proposed as 'paragraph tagging'. It should not be forgotten that any topic finding process requires accession of the page-numbers from the book. In this way, tagging each of the paragraphs by two parameters namely paragraph-id, indicating the paragraph-count in its respective section and the page-number from where the paragraph commences on, ser ves as an identification sequence to respective paragraph-header node in chapter header index construction process. As the tool can be seen as a generalized identification utility to provide the page-filtered content, selecting the topicrelevant browsing material or laying out the page references of the topics at the back-indexes, the tool is currently being put to the design phases. Further work was extended by Tripti Sharma, Sarang Pitle as Meta-Content framework for back index generation. A common strategy to spot a page for reading is to use front index and back index. A front index generally contains the sections and subsections topic with their corresponding page numbers. A back index contains various words of books with corresponding page numbers in the sorted alphabetical order. From back index and front index page numbers are identified for topic spotting[10]. The proposed paper presents a Meta content framework for generating back indexes for e books which uses part of speech tagging. Keywords-front index, back index, topic spotting, part of speech tagging.
The usage of Implicit Ontologies pioneered by the project supervisor paved way with the idea behind to exploit the list of prominent terms, focusing on the Subject-domain. These terms mainly revealing subject-specificity, have been comfortably thought to be available at front-page 'table-of-contents'. These could be presumed to be implicitly available as portions of available text in soft format say in form of scanned 'read-only'; pdf documents and e-books for a given set of topics as focused terms. Consequently, the so constructed chapter-header index was used as a set of seed words to trigger the whole set of subject vocabulary as a back-index of the book. Figure 1 shows the PFD.
Figure 1. Process Flow Digram (PFD)
Input corpus of search from Database Management Systems with book of topic search: “Modern Database Management Eighth Edition” authored by Jeffrey A. Hoffer, MaryB. Prescott and Fred R. McFadden. Firstly the content of the book needs to be extracted from .pdf files. Apache PDFBox™ was the best tool available for text extraction from every type of .pdf files. It managed to handle the distorted text and replaced them with equivalent characters with the help of image processing. Further, 'pdfbox' tool worked for all versions of pdf documents, and reflected the structured content pagewise. Further processing was to convert to required XML file format along with tailored identification tags. These tags were needed to identify chapter / section / sub-section / paragraph boundaries, so that page-accession operations could be performed only upon the targeted paragraphs with negligible execution times. Figure 2 shows a tagged section of a chapter.

Figure 2. Tagged Section of a Chapter
The proposed tool makes use of Java implementation of probabilistic natural language parser, a free download from Stanford Group Stanford dependency manual [4].The POS Tagger reads English text and assigns parts of speech to each word (and other token), such as noun, verb, adjective, etc., although generally applications use more fine-grained POS tags like 'noun-plural'.
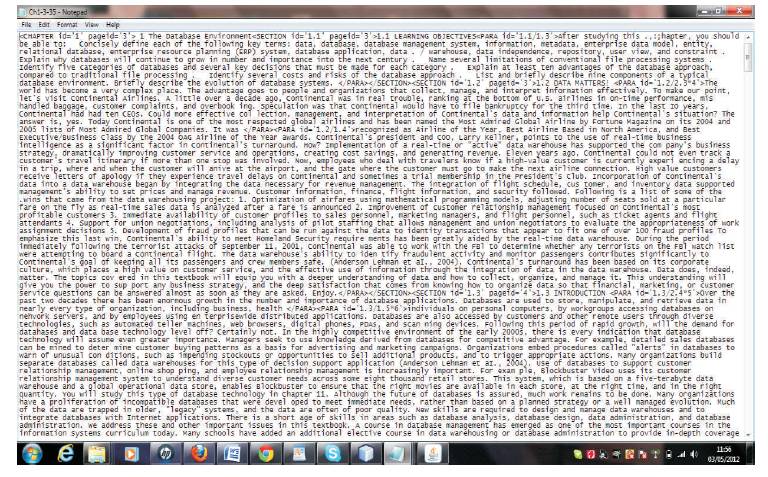
Figure 3. Snapshot represents the Chapter tagged .xml file
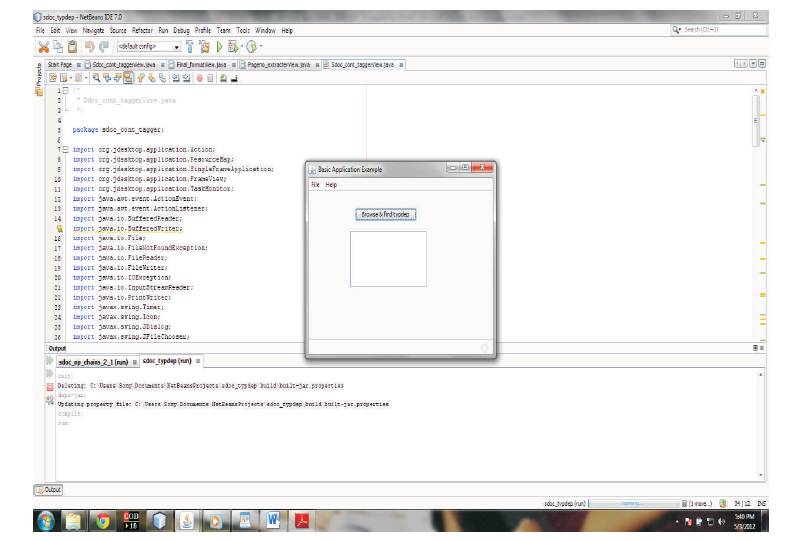
Figure 4. The Stanford parser interface
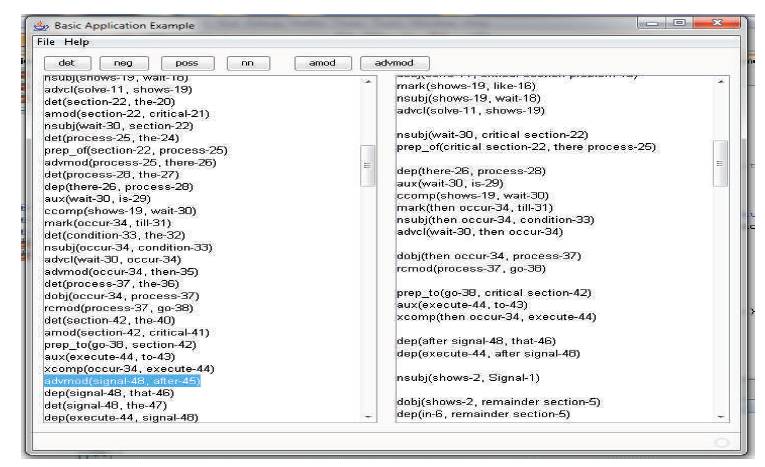
Figure 5. A Snapshot Showing Generation of Noun Phrases
The back index for which the book of Data Base Management System by Henry F.korth. Eighth Edition was chosen. The content was provided with text format in '.xml' extension. The .xml file contained Chapter tags with subsequent sections and also the paragraph tags. Figure 3 shows snapshot that represents the Chapter tagged .xml file of chapter 1 along with their page number and section number.
To select the key terms from the content of the book, the front index provided is used. Selected key terms from the front index and the related words which are noun phrases are added to the back index. To select the noun phrases, the inter relation between the words are required. The Stanford type-dependencies manual was used to find the relations between the word and phrases. The Stanford type-dependency manual provides 55 dependencies(as mentioned in previous chapter) which relate the words and phrases from each other. This Stanford typedependency manual is used to create a Stanford parser using Java. The parser takes the input as text file and generate the dependencies. As mentioned above, the text of the book was made as text document with chapter, section and paragraph tags and given file extension as .xml was made as input to the Stanford parser. The following is taken from the interface designed for the Stanford parser. Figure 4 shows the Interface for the Treated Dependencies.
The chapterwise .xml file were made input for the parser and the parse writes a new file with all the dependencies in to it. This new file was given .tpd as its extension. A sample output of the parsed output is shown as below:
The parsed output shown contains all the relation between all the words of the input text corpus, but only few will be useful for the back index generation. The only selected dependencies are used to find the words for the back index, thus for that purpose, a new module using Java code is created. The module refines or rather treats the dependencies to find the abstract dependencies and the apt words for the back index. This module takes the typed dependencies generated from the Stanford parser i.e. the .tpd file as input. It treats the contents of the .tpd file and writes the treated dependencies to new file. The file so generated so is the another text file which contains the treated dependencies and are saved as extension of .adv file. The following snapshot as shown in Figure 6 is taken from the interface of this module.
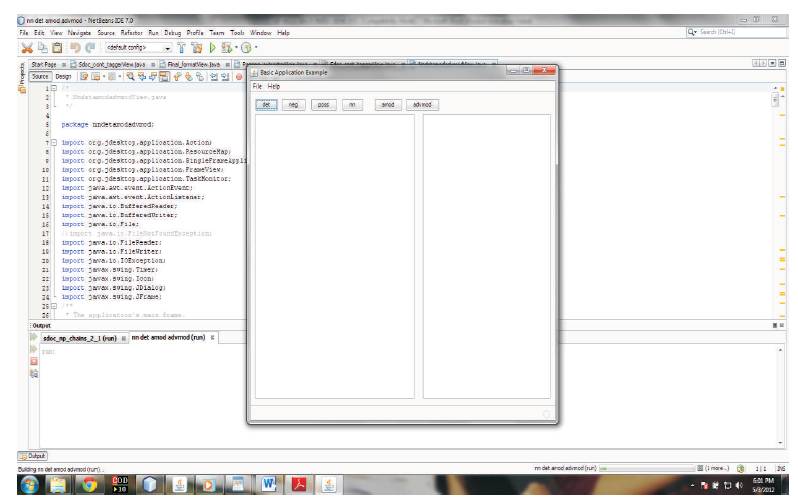
Figure 6. Module to Find Treated Dependencies
The next step towards the back index generation was to select key terms form the front index to find the noun phrases that created chain of the co-occurring word. In addition to this, each word should be attached with the page number according to their occurrence in the respective pages
To proceed in this way, the final module was created. The final module takes the input, the .adv file as input, also the text file which contains the key term for whom the chain of noun phrases is to be created. To patch with the page number of each word, the text of the .xml file is been tokenized and each word in the text is tagged as '/NN'. The final module takes these three files as input, select single word from the /NN tag file and from the .adv file and patch the page number to each word and then will select the key word from the key word file and generate the chain noun phrases. The following snapshot as shown in Figure 7 is taken from the interface of final module. The output of the above module is written in a new text file and is saved as .npc extension, since the .npc file contains the continuous line of the words in the chain to make them in a proper index format, the carriage return is given after each word. Thus the flat back index of the input corpus is generated. Figure 8 and 9 show the Generated back index.
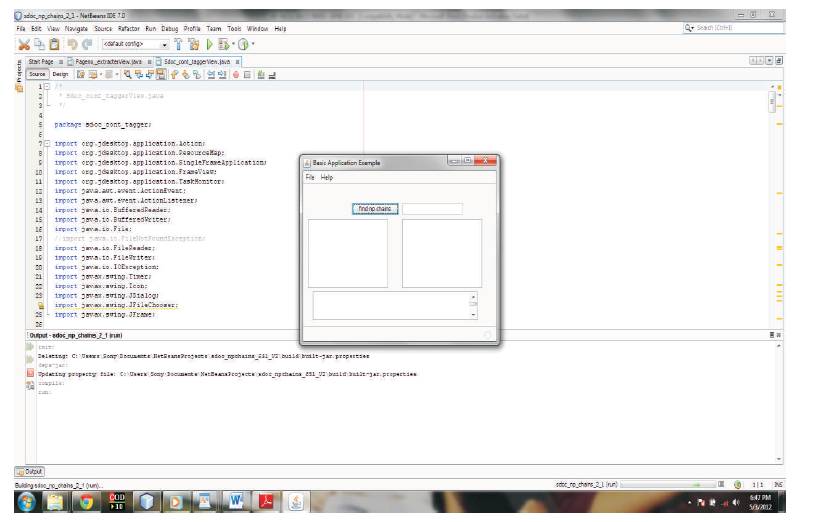
Figure 7. The Noun Phrase Chain Module
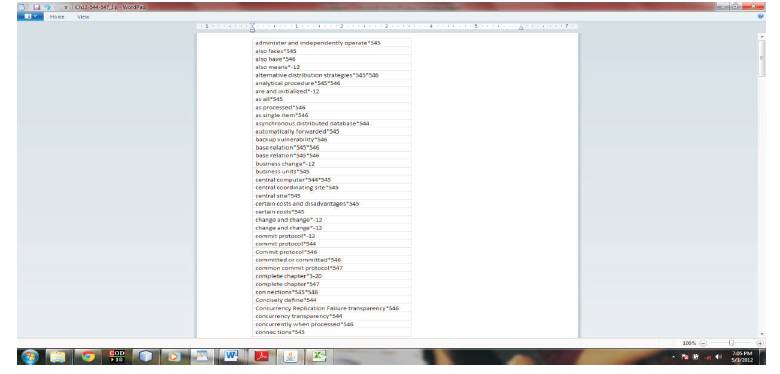
Figure 8. Generated Back Index Chapter 13
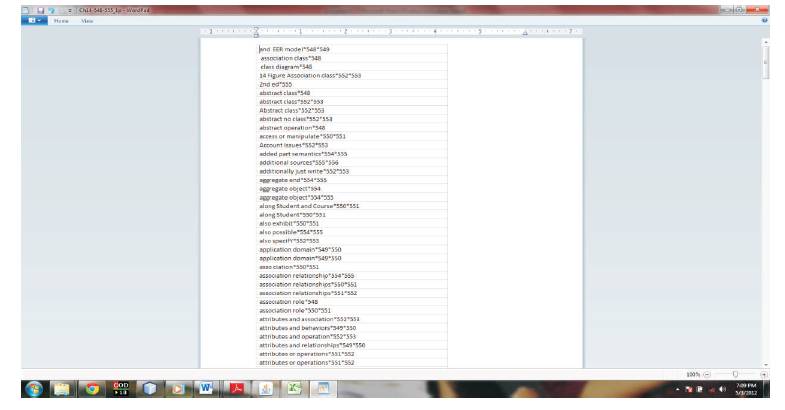
Figure 9. Generated Back Index Chapter 14
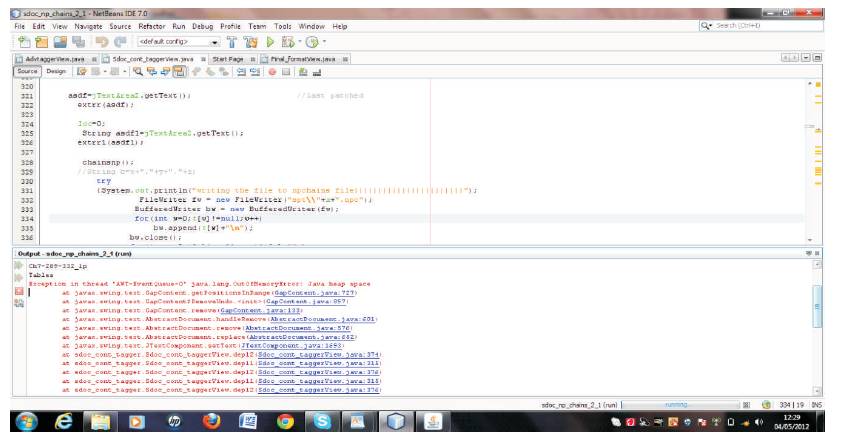
Figure 10. Error in a Large Chapter 7
The above piece of work is able to precisely position the subject-indexing terms that bear high degree of relevance in semantic sense. Thus, the highlighted domain keywords that get into the concept space as string-match patterns directly from the concept header tree, occupy the first positions in the hierarchically indexing segments at back index. The higher the cooccurrence measures found upon the co-occurring links, the above terms and indirectly activated semanticassociated terms, the stronger the synaptic links become, signified by heavy synaptic weight measures. This in turn causes the co-occurring terms to occupy promising positions as subordinate index terms down in the hierarchies of the super-indexing terms. In this way, the relevant topic terms, although non-frequent i.e. having lesser term-frequencies, do find relative positions in the subjective indexes, giving completeness in its construction. The other observations that some of the activated nodes bearing very highterm frequencies, almost negligible co-occurrences and not participating in any way with relevant concepts can appear as independent index terms at the back index along with their multiple page references, shall be taken up as a topic of ongoing research. It was observed that due to limited hardware specifications and exhaustive text in long-sized chapters, the group faced some errors like index out of bound, space of memory heap space, the same implementation could again be performed, but by generating proper noun phrases, instead of all noun phrases (both common and proper nouns). This may lead to generation of reduced but more focused subjectdomain vocabulary, taking the shape of a back-index.
Further, the terms were augmented with page-numbers, by scanning the paragraph tags of each of the sections and sub-sections in all the chapters. Although the module implementation could successfully drill all the subjectvocabulary terms chapter by chapter, however, it was observed that due to limited hardware specifications and exhaustive text in long-sized chapters, the group faced some errors like index out of bound, space of memory heap space, as illustrated for chapters 1,7,10 in Figure 10. Hence, the group was inspired by the opinion that the same implementation could again be performed, but by generating proper noun phrases, instead of all noun phrases (both common and proper nouns). This may lead to generation of reduced but more focused subjectdomain vocabulary, taking the shape of a back-index.